神经网络的优化器
文章目录
- 随机梯度下降
- 动量
- 内斯特洛夫加速梯度
- 自适应梯度
- 均方根支撑
- 自适应矩估计
- 附录
优化器是基于梯度的用来更新可训练参数的方法。本文是参考论文《An overview of gradient descent optimization
algorithms》做出的讨论。我们设置一些符号的含义如下:损失值为 ℓ \ell ℓ,需要被更新的可训练参数为 w w w,使用 ω \omega ω 来泛指除 w w w 外的其它可训练参数,记 ℓ \ell ℓ 对 w w w 的偏导函数为 J ( w , ω ) = ∂ ℓ ∂ w J(w, \, \omega)=\frac{\partial \ell}{\partial w} J(w,ω)=∂w∂ℓ,该函数的自变量为全体可训练参数,记 g t = J ( w t , ω t ) g_t=J(w_t, \, \omega_t) gt=J(wt,ωt),设学习率为 λ \lambda λ(常取值为 0.01 0.01 0.01),优化器迭代的次数为 t t t。
随机梯度下降
随机梯度下降法(stochastic gradient descent, SGD)是原始 BP 算法提供的优化器,也是最早在深度学习中应用的优化器。其公式如下:
w t + 1 = w t − λ g t w_{t+1}=w_t-\lambda g_t wt+1=wt−λgt SGD 算法面临着诸多挑战:
- 当使用 SGD 下降到沟壑或盆地时,SGD 可能产生剧烈的抖动。一方面,抖动可能会使其跳出当前极小值,有机会找到更优的极小值;另一方面,抖动可能使得收敛速度减慢或无法收敛到极小值,此时只能通过手动降低学习率来降低抖动。研究者们最先提出了学习率计划表,为损失值设定阈值及其对应的学习率,当损失值下降到某一阈值时,启用该阈值对应的学习率。但学习率计划表,有针对性没有广泛性,对每一个数据集都需要编制其独有的学习率计划表。
- SGD 对于所有的可训练参数使用相同的学习率是不恰当的。我们不希望以同样的程度来更新所有参数,对于那些频繁更新的参数我们希望它每次更新能有一个较小的幅度,那些更新频率较低的参数我们希望它每次更新能有一个较大的幅度。
动量
在沟壑中 SGD 会在沟壑两侧剧烈抖动,而在沟壑的下降方向移动十分缓慢。动量法(momentum)通过累积的方式,可以抑制在沟壑两侧方向上的抖动,在下降方向上使速度叠加。其公式如下:
m t = α m t − 1 + λ g t m_t = \alpha m_{t-1} + \lambda g_t mt=αmt−1+λgt w t + 1 = w t − m t w_{t+1} = w_t-m_t wt+1=wt−mt 其中 α \alpha α 是新引入的常量参数(常取值为 α = 0.9 \alpha=0.9 α=0.9), m t m_t mt 是为了实现算法而引入的变量。当 g t − 1 g_{t-1} gt−1 的符号与 g t g_t gt 的正负不同时, m t m_t mt 的累加就会使二者得到一定的抵消,即抑制抖动的作用;当 g t − 1 g_{t-1} gt−1 的符号与 g t g_t gt 的正负相投时, m t m_t mt 的累加就会使二者叠加,即叠加速度的作用。

从上图可以看出 Momentum 在短时间内就将抖动抑制,而 SGD 抖动从未停止。并且 Momentum 对在沟壑下降方向上对速度的叠加效果也很明显,仅用 1426 轮迭代就走出了模型,而 SGD 使用了 14778 轮。
内斯特洛夫加速梯度
我们蒙着眼睛向前走时,总是伸出自己的两只手,探测自己的前方有无障碍物,以便及时更改前进方向。内斯特洛夫加速梯度(nesterov accelerated gradient,NAG)就使用了这种方法,而是使用前方的梯度来修正当前的前进方向。其公式如下:
m t = α m t − 1 + λ J ( w t − α m t − 1 , ω t − α μ t − 1 ) m_t = \alpha m_{t-1} + \lambda J(w_t-\alpha m_{t-1}, \, \omega_t - \alpha \mu_{t-1}) mt=αmt−1+λJ(wt−αmt−1,ωt−αμt−1) w t + 1 = w t − m t w_{t+1} = w_t-m_t wt+1=wt−mt 其中 α \alpha α 是新引入的常量参数(常取值为 α = 0.9 \alpha=0.9 α=0.9), m t m_t mt 是为了实现算法而引入的变量, μ t \mu_t μt 泛指对应 ω \omega ω 的 m t m_t mt。接下来我们将通过一幅示意图为读者介绍 NAG 的原理,以及其与 Momentum 的对比。
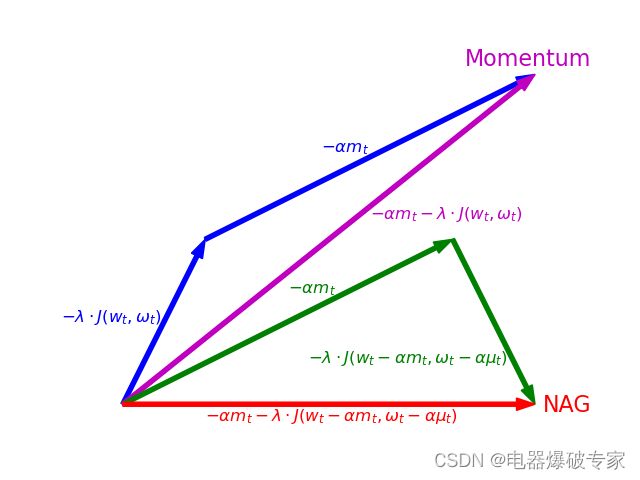
在上图中,Momentum 求当前点的梯度得到图中蓝色短线所示向量,然后再加上动量(图中蓝色长线所示向量)得到最终的更新向量,即图中紫色线所示向量;NAG 不再求当前点的梯度,而是求当前点加上动量所到达的点的梯度,即图中绿色短线所示向量,与动量复合即得到红色线所示的向量。最终 Momentum 将按照紫色向量更新,NAG 将按照红色向量更新。
自适应梯度
前面我们提到为可训练参数设置相同的学习率是不合理的。自适应梯度(adaptive gradient, AdaGrad)提供了一种为参数动态调整学习率的方法。它为频繁更新的参数设置较低的学习率,为不经常更新的参数设置较高的学习率,从而使每个参数都有自己的更新幅度。其公式如下:
v t = v t − 1 + g t 2 v_t=v_{t-1}+g_t^2 vt=vt−1+gt2 w t + 1 = w t − λ v t + ϵ ⋅ g t w_{t+1}=w_t-\frac{\lambda}{\sqrt{v_t+\epsilon}} \cdot g_t wt+1=wt−vt+ϵλ⋅gt 其中为了避免分母为零而引入的常量参数 ϵ \epsilon ϵ (常取值为 ϵ = 1 × 1 0 − 8 \epsilon=1 \times 10^{-8} ϵ=1×10−8), v t v_t vt 是为了实现算法而引入的变量。 v t v_t vt 一直在对 g t 2 g_t^2 gt2 做累加,如果一个参数频繁更新必然会导致 v t v_t vt 增大的幅度超乎寻常,那么 λ v t + ϵ \frac{\lambda}{\sqrt{v_t+\epsilon}} vt+ϵλ 就会超乎寻常的相应变小。这种方式也可以抑制抖动,即让那些梯度有剧烈变化的参数有一个较小的学习率。
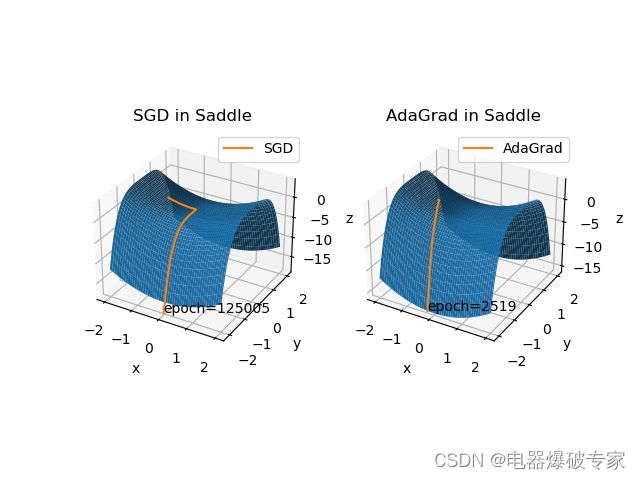
如图所示 AdaGrad 为 y 配置了较大的学习率,为 x 配置了较小的学习率,从而使其能够快速脱离马鞍。AdaGrad 仅迭代了 2519 轮,而 SGD 迭代了 125005 轮。
我们看到 v t v_t vt 一直在做正数累加,总体上会使全体参数的学习率趋向无穷小,在训练的后期会使模型的收敛速度变得极慢。不可否认的是,在训练的后期是需要降低学习率,从而稳定下降到极小值,避免在极小值处抖动,即使用退火学习率。笔者推测,AdaGrad 也是出于这种考量,使用正数累加的方式从总体上来降低学习率,让模型在训练后期稳定下降。但 AdaGrad 的现实表现却不尽如人意。
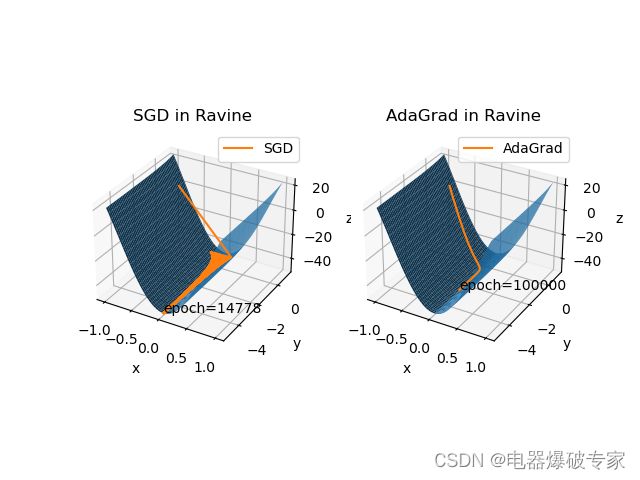
我们可以看到,AdaGrad 在峡谷中十分稳定没有分毫抖动,但不断下降的学习率让它步履维艰,迭代了 100000 轮还没有走出峡谷。
若想深入了解该方法可查阅原始文献《Adaptive Subgradient Methods for Online Learning and Stochastic Optimization》
均方根支撑
均方根支撑(root mean square prop, RMSProp)是 Geoff Hinton 在他的课堂讲义中提出的一个尚未发表的方法。RMSProp 相对于 AdaGrad 单调减少的学习率有了很大改善,它的 v t v_t vt 不再是做正数累加,而是使用了衰减平均值,使其能够稳定在一定的范围之中。其公式如下:
v t = β v t − 1 + ( 1 − β ) g t 2 v_t=\beta v_{t-1}+(1-\beta)g_t^2 vt=βvt−1+(1−β)gt2 w t + 1 = w t − λ v t + ϵ ⋅ g t w_{t+1}=w_t - \frac{\lambda}{\sqrt{v_t + \epsilon}} \cdot g_t wt+1=wt−vt+ϵλ⋅gt 其中常量参数 ϵ \epsilon ϵ 的作用及常用取值与 AdaGrad 一致,新引入常量参数 β \beta β 作为 v t v_t vt 的衰减系数(常取值为 β = 0.9 \beta=0.9 β=0.9), v t v_t vt 是为了实现算法而引入的变量。

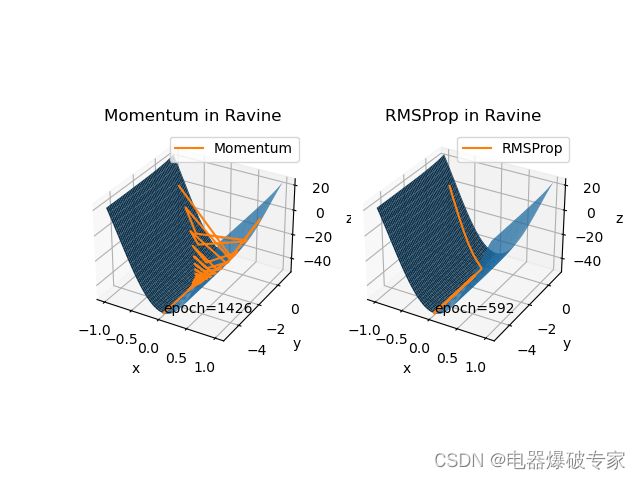
可以看到,无论是在马鞍上还是在峡谷中 RMSProp 在速度和抑制抖动方面都有着非常出色的表现。但细心观察会发现 RMSProp 在峡谷底部还是有细微的抖动,看来仅凭学习率来抑制抖动,还是无法做到根除。
若想深入了解该方法可查阅原始文献《rmsprop: Divide the gradient by a running average of its recent magnitude》
自适应矩估计
自适应矩估计(Adaptive Moment Estimation, Adam)是个缝合怪,它把 Momentum 和 RMSProp 缝合到了一起,使得它既有自适应调节学习率的能力,也有动量抑制抖动、叠加速度的能力。其表达式如下:
{ m t = α ⋅ m t − 1 + ( 1 − α ) g t v t = β ⋅ v t − 1 + ( 1 − β ) g t 2 \left\{ \begin{array}{l} m_t=\alpha \cdot m_{t-1}+(1-\alpha) g_t\\ v_t=\beta \cdot v_{t-1}+(1-\beta) g_t^2 \end{array} \right. {mt=α⋅mt−1+(1−α)gtvt=β⋅vt−1+(1−β)gt2 w t + 1 = w t − λ v t 1 − β t + ϵ ⋅ m t 1 − α t w_{t+1}=w_t - \frac{\lambda}{\sqrt{\frac{v_t}{1-\beta^t}}+\epsilon} \cdot \frac{m_t}{1-\alpha^t} wt+1=wt−1−βtvt+ϵλ⋅1−αtmt 其中 α \alpha α 和 β \beta β 是用作衰减系数的常量参数(常取值为 α = 0.9 , β = 0.999 \alpha=0.9,\beta=0.999 α=0.9,β=0.999),常量参数 ϵ \epsilon ϵ 的作用及常用取值与 AdaGrad 一致, m t m_t mt 和 v t v_t vt 是为了实现算法而引入的变量。值得注意的是 Adam 的作者对 m t m_t mt 和 v t v_t vt 做了如下处理: m t 1 − α t \frac{m_t}{1-\alpha^t} 1−αtmt 、 v t 1 − β t \frac{v_t}{1-\beta^t} 1−βtvt。是因为作者发现 m t m_t mt 和 v t v_t vt 在初始化时为零,所以在刚开始迭代时其值很小(特别是在衰减值设置的很大的时候)。所以作者加入 m t 1 − α t \frac{m_t}{1-\alpha^t} 1−αtmt 、 v t 1 − β t \frac{v_t}{1-\beta^t} 1−βtvt,在刚开始迭代时使其得到适当放大。可以看到随着迭代次数的增加 1 − α t 1-\alpha^t 1−αt 与 1 − β t 1-\beta^t 1−βt 的值逐渐趋于 1 1 1,所以迭代次数达到一定值时,二者的影响就可以忽略不计了。

通过上图可以看到可以看到 Adam 相对于 RMSProp 在马鞍上的表现更为优秀,下降曲线也比较平滑。

通过上图可以看到,虽然 Adam 的下降速度比 RMSProp 慢一些,但是在峡谷中没有像 RMSProp 一样发生抖动。

通过上图可以更直观的看出 Adam 的优势,Adam 经过 1379 轮迭代后下降到了最小值点,而 RMSProp 一直在最小值附近抖动,经过 100000 轮迭代还没有稳定下来。
若想深入了解该方法可查阅原始文献《ADAM: A METHOD FOR STOCHASTIC OPTIMIZATION》
附录
以下为笔者将优化器的表现可视化所使用的代码:
from matplotlib import pyplot as plt
from matplotlib import colors
import numpy as np
class Ravine:
@staticmethod
def get_name():
return 'Ravine'
# 模型的方程
@staticmethod
def function(x, y):
return -np.cos(2 * x) * 50 + np.power(np.e, y)
# 模型的梯度
@staticmethod
def gradient(x, y):
return np.sin(2 * x) * 100, np.power(np.e, y)
# 输出模型的范围,依次为:x 轴最小值、x 轴最大值、y 轴最小值、y 轴最大值
@staticmethod
def get_scope():
return -1, 1, -5, 1
# 输出优化器在本模型上梯度下降的起点
@staticmethod
def get_start():
return -0.8, 0.5
class Saddle:
@staticmethod
def get_name():
return 'Saddle'
@staticmethod
def function(x, y):
return x * x - y * y * y * y
@staticmethod
def gradient(x, y):
return x * 2, -y * y * y * 4
@staticmethod
def get_scope():
return -2, 2, -2, 2
@staticmethod
def get_start():
return -1, -0.01
class Beale:
@staticmethod
def get_name():
return 'Beale'
@staticmethod
def function(x, y):
return (1.5 - x * y)**2 + (2.25 - x - x * y * y)**2 + (2.625 - x + x * y * y * y)**2
@staticmethod
def gradient(x, y):
gradient_x = 2 * ((1.5 - x + x * y) * (-1 + y) + (2.25 - x + x * y * y) * (-1 + y * y) + (
2.625 - x + x * y * y * y) * (-1 + y * y * y))
gradient_y = 2 * ((1.5 - x + x * y) * x + (2.25 - x + x * y * y) * (2 * x * y) + (2.625 - x + x * y * y * y) * (
3 * x * y * y))
return gradient_x, gradient_y
@staticmethod
def get_scope():
return -5, 5, -5, 5
@staticmethod
def get_start():
return 1.5, 1.2
class SGD:
_learning_rate = 0.01
def optimize(self, gradient_w, w, t):
w = w - self._learning_rate * gradient_w
return w
class Momentum:
_learning_rate = 0.01
_alpha = 0.9
def __init__(self):
self.m = 0
def optimize(self, gradiant_w, w, t):
self.m = self._alpha * self.m + self._learning_rate * gradiant_w
w = w - self.m
return w
class NAG:
_learning_rate = 0.01
_alpha = 0.9
def __init__(self):
self.m = 0
def get_momentum(self):
return self._alpha * self.m
def optimize(self, detection_gradiant_w, w, t):
self.m = self._alpha * self.m + self._learning_rate * detection_gradiant_w
w = w - self.m
return w
class AdaGrad:
_learning_rate = 0.01
_epsilon = 0.0000000001
def __init__(self):
self.v = 0
def optimize(self, gradient_w, w, t):
self.v = self.v + gradient_w**2
w = w - self._learning_rate / np.sqrt(self.v + self._epsilon) * gradient_w
return w
class RMSProp:
_learning_rate = 0.01
_beta = 0.9
_epsilon = 0.0000000001
def __init__(self):
self.v = 0
def optimize(self, gradient_w, w, t):
self.v = self._beta * self.v + (1 - self._beta) * gradient_w**2
w = w - self._learning_rate / np.sqrt(self.v + self._epsilon) * gradient_w
return w
class AdaDelta:
_beta = 0.9
_epsilon = 0.0000000001
def __init__(self):
self.v = 0
self.d = 0
def optimize(self, gradient_w, w, t):
self.v = self._beta * self.v + (1 - self._beta) * gradient_w**2
t = np.sqrt(self.d + self._epsilon) / np.sqrt(self.v + self._epsilon) * gradient_w
w = w - t
self.d = self._beta * self.d + (1 - self._beta) * t**2
return w
class Adam:
_learning_rate = 0.01
_alpha = 0.9
_beta = 0.99
_epsilon = 0.0000000001
def __init__(self):
self.m = 0
self.v = 0
def optimize(self, gradient_w, w, t):
self.m = self._alpha * self.m + (1 - self._alpha) * gradient_w
self.v = self._beta * self.v + (1 - self._beta) * gradient_w**2
w = w - self._learning_rate \
/ (np.sqrt(self.v / (1 - np.power(self._beta, t))) + self._epsilon) \
* self.m / (1 - np.power(self._alpha, t))
return w
optimizers = {
'SGD': SGD,
'Momentum': Momentum,
'NAG': NAG,
'AdaGrad': AdaGrad,
'RMSProp': RMSProp,
'AdaDelta': AdaDelta,
'Adam': Adam,
}
def experiment(axes, model, optimizer):
scope = model.get_scope()
x, y = np.meshgrid(np.linspace(scope[0], scope[1], 100), np.linspace(scope[2], scope[3], 100))
z = model.function(x, y)
# axes.plot_surface(x, y, z, zorder=1) # 在图上绘制模型
axes.plot_surface(x, y, z, zorder=1, norm=colors.LogNorm(), cmap='jet') # 在图上绘制模型
axes.set_xlabel('x')
axes.set_ylabel('y')
axes.set_zlabel('z')
axes.set_title(f'%s in %s' % (optimizer, model.get_name()))
optimizer_x = optimizers[optimizer]() # 为 x 生成优化器
optimizer_y = optimizers[optimizer]() # 为 y 生成优化器
x, y = model.get_start()
xa, ya = [x], [y] # 用于记录下降过程中经过的点
t = 1 # 记录迭代轮次
while (t < 10
or (t < 100000
and not (ya[-1] == ya[-2] and xa[-1] == xa[-2])
and (scope[0] < x < scope[1] and scope[2] < y < scope[3]))):
if optimizer == 'NAG': # 计算梯度
gradient_x, gradient_y = model.gradient(x - optimizer_x.get_momentum(), y - optimizer_y.get_momentum())
else:
gradient_x, gradient_y = model.gradient(x, y)
x = optimizer_x.optimize(gradient_x, x, t) # 用优化器优化
y = optimizer_y.optimize(gradient_y, y, t) # 用优化器优化
xa.append(x)
ya.append(y)
t = t + 1
za = [model.function(i, j) for i, j in zip(xa, ya)] # 生成下降时经过的点的 z 轴坐标
axes.plot(xa, ya, za, zorder=3, label=optimizer) # 在图上绘制下降路线
axes.text(x, y, model.function(x, y), f'epoch=%d' % t)
axes.legend()
if __name__ == '__main__':
experiment(plt.subplot(121, projection='3d'), Beale, 'RMSProp')
experiment(plt.subplot(122, projection='3d'), Beale, 'Adam')
plt.show()
以下为生成 NAG 示意图的代码:
from matplotlib import pyplot as plt
import numpy as np
ax = plt.subplot(111, aspect='equal')
ax.axis('off')
ax.arrow(0.00, 0.00, 0.02, 0.04, length_includes_head=True, color='b')
ax.arrow(0.02, 0.04, 0.08, 0.04, length_includes_head=True, color='b')
ax.arrow(0.00, 0.00, 0.10, 0.08, length_includes_head=True, color='m')
ax.arrow(0.00, 0.00, 0.08, 0.04, length_includes_head=True, color='g')
ax.arrow(0.08, 0.04, 0.02, -0.04, length_includes_head=True, color='g')
ax.arrow(0.00, 0.00, 0.10, 0.00, length_includes_head=True, color='r')
ax.text(-0.015, 0.02, r'$-\lambda \cdot J(w_t, \omega_t)$', color='b', size=12)
ax.text(0.048, 0.061, r'$-\alpha m_t$', color='b', size=12)
ax.text(0.06, 0.045, r'$-\alpha m_t-\lambda \cdot J(w_t, \omega_t)$', color='m', size=12)
ax.text(0.083, 0.082, 'Momentum', color='m', size=16)
ax.text(0.04, 0.027, r'$-\alpha m_t$', color='g', size=12)
ax.text(0.045, 0.010, r'$-\lambda \cdot J(w_t - \alpha m_t, \omega_t - \alpha\mu_t)$', color='g', size=12)
ax.text(0.02, -0.004, r'$-\alpha m_t - \lambda \cdot J(w_t - \alpha m_t, \omega_t - \alpha\mu_t)$', color='r', size=12)
ax.text(0.102, -0.002, 'NAG', color='r', size=16)
plt.show()