主从复制,读写分离,分表分库
垂直拆分和水平拆分的区别
垂直拆分:垂直拆分就是根据不同的业务,拆分成不同的数据库,比如会员数据库,订单数据库,支付数据库,消息数据库,打醒互联网电商平台,微服务项目架构中比较常见;他是把不同的表拆到不同的数据库
优点:拆分后业务更加清晰,拆分规则明确,系统之家你整合或扩展更加容易
缺点 :部分业务表无法join,只能通过接口方式解决,挺高了系统复杂度分布式事务问题
水平拆分: 他是把同一个表拆分到不同的数据库中,他的设计策略不是根据具体的服务,而是根据具体的业务来规定的,比如按照时间,或者订单的编号;
优点: 拆分规则抽象好,join操作基本可以数据库做,不存在单库大数据,高并发的性能瓶颈,提高了系统的稳定性跟负载能力。。
缺点: 分片事务一致性难以解决,跨库join性能较差,数据多次扩展难度跟维护量极大
什么是mycat
MyCAT是一款由阿里Cobar演变而来的用于支持数据库,读写分离、分表分库的分布式中间件。MyCAT支持Oracle、MSSQL、MYSQL、PG、DB2关系型数据库,同时也支持MongoDB等非关系型数据库。 MyCAT原理MyCAT主要是通过对SQL的拦截,然后经过一定规则的分片解析、路由分析、读写分离分析、缓存分析等,然后将SQL发给后端真实的数据块,并将返回的结果做适当处理返回给客户端。
http://www.mycat.io/
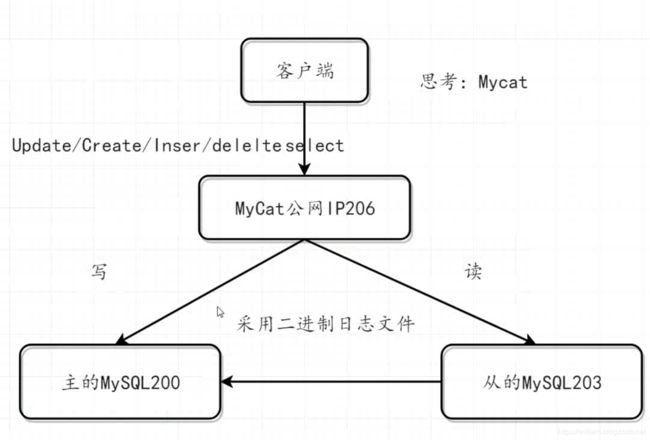
整体读写分离的架构体系为如下
Mycat的安装
Linux环境安装MyCat实现读写分离
1、上传安装Mycat-server-1.6.5-release-20180122220033-linux.tar
2、解压安装包tar –zxvf
3、配置schema.xml 和server.xml
4、客户端连接端口号: 8066
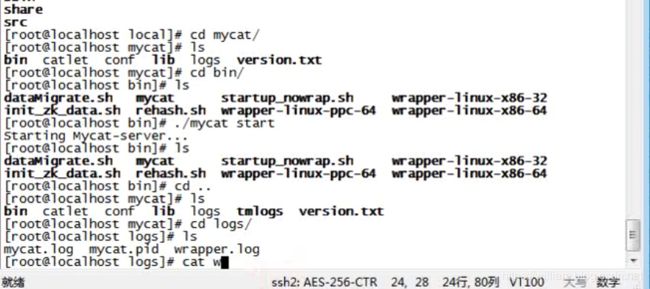
查看warpper.log 如何展示sucess则启动成功
进入bin目录 启动MyCat ./mycat start 停止MyCat ./mycat stop
查看/usr/local/mycat/logs wrapper.log日志
如果是为successfully 则启动成功
关闭防火墙:systemctl stop firewalld.service
只可读的账号 user user 端口号8066
可读可写的账号 root 123456 端口号8066
servet.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- TESTDB1 是mycat的逻辑库名称,链接需要用的 -->
<schema name="mycat_testdb" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1"></schema>
<!-- database 是MySQL数据库的库名 -->
<dataNode name="dn1" dataHost="localhost1" database="test" />
<!--
dataNode节点中各属性说明:
name:指定逻辑数据节点名称;
dataHost:指定逻辑数据节点物理主机节点名称;
database:指定物理主机节点上。如果一个节点上有多个库,可使用表达式db$0-99, 表示指定0-99这100个数据库;
dataHost 节点中各属性说明:
name:物理主机节点名称;
maxCon:指定物理主机服务最大支持1000个连接;
minCon:指定物理主机服务最小保持10个连接;
writeType:指定写入类型;
0,只在writeHost节点写入;
1,在所有节点都写入。慎重开启,多节点写入顺序为默认写入根据配置顺序,第一个挂掉切换另一个;
dbType:指定数据库类型;
dbDriver:指定数据库驱动;
balance:指定物理主机服务的负载模式。
0,不开启读写分离机制;
1,全部的readHost与stand by writeHost参与select语句的负载均衡,简单的说,当双主双从模式(M1->S1,M2->S2,并且M1与 M2互为主备),正常情况下,M2,S1,S2都参与select语句的负载均衡;
2,所有的readHost与writeHost都参与select语句的负载均衡,也就是说,当系统的写操作压力不大的情况下,所有主机都可以承担负载均衡;
-->
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="3" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- 可以配置多个主从 -->
<writeHost host="hostM1" url="192.168.212.202:3306" user="root" password="root">
<!-- 可以配置多个从库 -->
<readHost host="hostS2" url="192.168.212.203:3306" user="root" password="root" />
</writeHost>
</dataHost>
</mycat:schema>
server.xml
<?xml version="1.0" encoding="UTF-8"?>
<!-- - - Licensed under the Apache License, Version 2.0 (the "License");
- you may not use this file except in compliance with the License. - You
may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0
- - Unless required by applicable law or agreed to in writing, software -
distributed under the License is distributed on an "AS IS" BASIS, - WITHOUT
WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - See the
License for the specific language governing permissions and - limitations
under the License. -->
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://io.mycat/">
<!-- 读写都可用的用户 -->
<user name="root" defaultAccount="true">
<property name="password">123456</property>
<property name="schemas">mycat_testdb</property>
<!-- 表级 DML 权限设置 -->
<!--
<privileges check="false">
<schema name="TESTDB" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
</user>
<!-- 只读用户 -->
<user name="user">
<property name="password">user</property>
<property name="schemas">mycat_testdb</property>
<property name="readOnly">true</property>
</user>
</mycat:server>
springboot 整合读写分离
利用aop读取方法名,进行判断
package com.mayikt.db.aop;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.springframework.context.annotation.Lazy;
import org.springframework.core.annotation.Order;
import org.springframework.stereotype.Component;
import com.mayikt.db.config.DataSourceContextHolder;
// 使用AOP动态切换不同的数据源
@Aspect
@Component
@Lazy(false)
@Order(0) // Order设定AOP执行顺序 使之在数据库事务上先执行
public class SwitchDataSourceAOP {
// 这里切到你的方法目录
@Before("execution(* com.mayikt.service.*.*(..))")
public void process(JoinPoint joinPoint) {
String methodName = joinPoint.getSignature().getName();
if (methodName.startsWith("get") || methodName.startsWith("count") || methodName.startsWith("find")
|| methodName.startsWith("list") || methodName.startsWith("select") || methodName.startsWith("check")) {
DataSourceContextHolder.setDbType("selectDataSource");
} else {
// 切换dataSource
DataSourceContextHolder.setDbType("updateDataSource");
}
}
}
package com.mayikt.db.config;
import javax.sql.DataSource;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.jdbc.DataSourceBuilder;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class DataSourceConfig {
// 创建可读数据源
@Bean(name = "selectDataSource")
@ConfigurationProperties(prefix = "spring.datasource.select") // application.properteis中对应属性的前缀
public DataSource dataSource1() {
return DataSourceBuilder.create().build();
}
// 创建可写数据源
@Bean(name = "updateDataSource")
@ConfigurationProperties(prefix = "spring.datasource.update") // application.properteis中对应属性的前缀
public DataSource dataSource2() {
return DataSourceBuilder.create().build();
}
}
package com.mayikt.db.config;
import org.springframework.context.annotation.Lazy;
import org.springframework.stereotype.Component;
@Component
@Lazy(false)
public class DataSourceContextHolder {
// 采用ThreadLocal 保存本地多数据源
private static final ThreadLocal<String> contextHolder = new ThreadLocal<>();
// 设置数据源类型
public static void setDbType(String dbType) {
contextHolder.set(dbType);
}
public static String getDbType() {
return contextHolder.get();
}
public static void clearDbType() {
contextHolder.remove();
}
}
package com.mayikt.db.config;
import java.util.HashMap;
import java.util.Map;
import javax.sql.DataSource;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.context.annotation.Primary;
import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;
import org.springframework.stereotype.Component;
//在Spring 2.0.1中引入了AbstractRoutingDataSource, 该类充当了DataSource的路由中介, 能有在运行时, 根据某种key值来动态切换到真正的DataSource上。
@Component
@Primary
public class DynamicDataSource extends AbstractRoutingDataSource {
@Autowired
@Qualifier("selectDataSource")
private DataSource selectDataSource;
@Autowired
@Qualifier("updateDataSource")
private DataSource updateDataSource;
/**
* 这个是主要的方法,返回的是生效的数据源名称
*/
@Override
protected Object determineCurrentLookupKey() {
System.out.println("DataSourceContextHolder:::" + DataSourceContextHolder.getDbType());
return DataSourceContextHolder.getDbType();
}
/**
* 配置数据源信息
*/
@Override
public void afterPropertiesSet() {
Map<Object, Object> map = new HashMap<>();
map.put("selectDataSource", selectDataSource);
map.put("updateDataSource", updateDataSource);
setTargetDataSources(map);
setDefaultTargetDataSource(updateDataSource);
super.afterPropertiesSet();
}
}
yml
spring:
datasource:
###可读数据源
select:
jdbc-url: jdbc:mysql://192.168.212.205:8066/mycat_testdb
driver-class-name: com.mysql.jdbc.Driver
username: user
password: user
####可写数据源
update:
jdbc-url: jdbc:mysql://192.168.212.205:8066/mycat_testdb
driver-class-name: com.mysql.jdbc.Driver
username: root
password: 123456
type: com.alibaba.druid.pool.DruidDataSource
mycat 根据分片枚举进行分表
分片枚举算法:就是根据不同的枚举常量,进行分类存储
应用场景:可以使用分片枚举,实现根据地区分类存储到不同的数据库进行存放
比如咱们的数据库中有中国13亿人口的数据, 我们不可能将他们都存放在同一个表中,此时我们可以根据中国省份进行划分,比如河南数据库,上海数据库。。
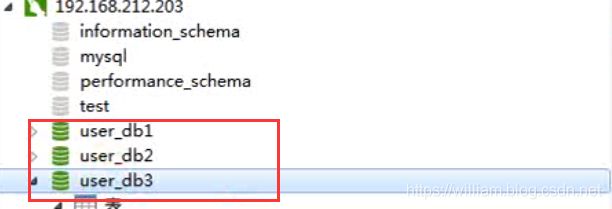
1:操作步骤 分别创建上海和数据库

此时我们还应该改再创建一个order.info这个表,作用下面再说
其中我们需要如下配置文件

获取文件的连接
partition-hash-int.txt

这个说明wuhan 会在插入在第0个库,上海存储在第1个库,苏州存储在第2个库
rule.xml
<?xml version="1.0" encoding="UTF-8"?>
<!-- - - Licensed under the Apache License, Version 2.0 (the "License");
- you may not use this file except in compliance with the License. - You
may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0
- - Unless required by applicable law or agreed to in writing, software -
distributed under the License is distributed on an "AS IS" BASIS, - WITHOUT
WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - See the
License for the specific language governing permissions and - limitations
under the License. -->
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/">
<tableRule name="role2">
<rule>
<columns>name</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
<function name="hash-int" class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
//如果key中文就是1,不是就选0 ,这个key值得就是partition-hash-int.txt键值对
<property name="type">1</property>
//当传入的不属于任何key,默认传入第一个节点
<property name="defaultNode">1</property>
</function>
</mycat:rule>
schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- TESTDB1 是mycat的逻辑库名称,链接需要用的 -->
<schema name="mycat_testdb" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
<table name="order_info" dataNode="dn1,dn2,dn3" rule="role2" />
</schema>
<!-- database 是MySQL数据库的库名 -->
<dataNode name="dn1" dataHost="localhost1" database="user_db1" />
<dataNode name="dn2" dataHost="localhost1" database="user_db2" />
<dataNode name="dn3" dataHost="localhost1" database="user_db3" />
<!--
dataNode节点中各属性说明:
name:指定逻辑数据节点名称;
dataHost:指定逻辑数据节点物理主机节点名称;
database:指定物理主机节点上。如果一个节点上有多个库,可使用表达式db$0-99, 表示指定0-99这100个数据库;
dataHost 节点中各属性说明:
name:物理主机节点名称;
maxCon:指定物理主机服务最大支持1000个连接;
minCon:指定物理主机服务最小保持10个连接;
writeType:指定写入类型;
0,只在writeHost节点写入;
1,在所有节点都写入。慎重开启,多节点写入顺序为默认写入根据配置顺序,第一个挂掉切换另一个;
dbType:指定数据库类型;
dbDriver:指定数据库驱动;
balance:指定物理主机服务的负载模式。
0,不开启读写分离机制;
1,全部的readHost与stand by writeHost参与select语句的负载均衡,简单的说,当双主双从模式(M1->S1,M2->S2,并且M1与 M2互为主备),正常情况下,M2,S1,S2都参与select语句的负载均衡;
2,所有的readHost与writeHost都参与select语句的负载均衡,也就是说,当系统的写操作压力不大的情况下,所有主机都可以承担负载均衡;
-->
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="3" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- 可以配置多个主从 -->
<writeHost host="hostM1" url="192.168.212.202:3306" user="root" password="root">
<!-- 可以配置多个从库 -->
<readHost host="hostS2" url="192.168.212.203:3306" user="root" password="root" />
</writeHost>
</dataHost>
</mycat:schema>
server.xml*
<?xml version="1.0" encoding="UTF-8"?>
<!-- - - Licensed under the Apache License, Version 2.0 (the "License");
- you may not use this file except in compliance with the License. - You
may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0
- - Unless required by applicable law or agreed to in writing, software -
distributed under the License is distributed on an "AS IS" BASIS, - WITHOUT
WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - See the
License for the specific language governing permissions and - limitations
under the License. -->
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://io.mycat/">
<!-- 读写都可用的用户 -->
<user name="root" defaultAccount="true">
<property name="password">123456</property>
<property name="schemas">mycat_testdb</property>
<!-- 表级 DML 权限设置 -->
<!--
<privileges check="false">
<schema name="TESTDB" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
</user>
<!-- 只读用户 -->
<user name="user">
<property name="password">user</property>
<property name="schemas">mycat_testdb</property>
<property name="readOnly">true</property>
</user>
</mycat:server>
然后进入mycat的conf文件夹下。进行替换
然后启动mycat,如果启动的是发现有端口号被占用
可以使用netstat -tunlp | grep 8080 然后kill -9 pid
如果启动出现 未找到命令安装 ym -y install net-tools