注册ChatGPT,试用MidJourney和Stable Diffusion
文章目录
-
- 一、ChatGPT
-
- 1.1 什么是ChatGPT
- 1.2 注册ChatGPT
- 二、 玩转MidJourney
- 三、本地配置Stable Diffusion
-
- 3.1 百度飞浆跑AIGC模型
- 3.2 colab试用Stable Diffusion-v1-4
- 3.3 colab试用stable-diffusion-2
- 3.4 其它功能
一、ChatGPT
1.1 什么是ChatGPT
能直接生成代码、会自动修复bug、在线问诊、模仿莎士比亚风格写作……各种话题都能hold住,它就是OpenAI上周推出的——ChatGPT。
ChatGPT 是 OpenAI 训练的对话式大规模语言模型,以对话的方式进行交互。它和之前的另一款模型 InstructGPT 属于同级模型,代表“GPT 3.5”代。
1. 写代码
有网友分别问谷歌和ChatGPT“如何使用Latex表示微分结果”,相较于谷歌中规中矩的回答:

ChatGPT则是一下给出了直接可用的代码,你只需动动手复制粘贴即可:

你还可以让它生成一个带有电子邮箱、密码输入框,以及登陆按钮的登陆界面等等。
2. 改bug
另一位网友 Josh 提交了一段代码,问 ChatGPT“我怎么都搞不懂这段代码为什么无法运行”。
ChatGPT 很详细地进行了解释:除法公式格式有问题,一个字符串(a)无法被一个数字(1)除,因为被除数和除数应该都是数字。

但这还没完。ChatGPT 再次试图理解原代码的意图,然后给 Josh 提供了一些修改的建议:如果想让除法处理非数字,则需要给函数加入额外的逻辑,让它能够检查实参的类型是什么,只有在两边都是数字的时候才运行。如果有一边不是数字,就返回错误或者一个默认值。

- 写数学公式和正则表达式等等
- 帮忙查询各种文档,给出学习建议和路线等等
- 输入中文,帮写英文邮件,语法非常好。
ChatGPT上线两天就有100万用户申请,现在正是免费测试期,不可不试。更多ChatGPT介绍可以参考演示视频《ChatGPT - 你的 AI 助教》、介绍帖《ChatGPT有多厉害,影响到谷歌地位?》、《行走的代码生成器:chatGPT》
1.2 注册ChatGPT
参考视频《1块钱注册火爆全网的ChatGPT机器人》
注册一个ChatGPT,你需要以下两点:
- 可以访问google,注册google账号
- 有一个国外的手机号,这个通过网站https://sms-activate.org/cn,注册一个虚拟手机号来完成
简单说就是国内不在OpenAI的服务地区,所以只有这样才能注册OpenAI的账户。
1. 注册OpenAI账户:
先定位到国外节点,打开ChatGPT注册地址,点击注册→接受

跳到OpenAI官网,用自己的邮箱注册一个OpenAI账户:(也可以用自己的google账户登录,但如果不是绑定国外手机号,就废了,所以还是重新注册好一点)

2. 邮件确认
注册完之后,提示确认邮件,此时网络节点一定要在国外,否则报错Not available,这个账户就没法用了,而且网页无法登出。你只能重开一个别的浏览器或者手机操作(未登录),比较麻烦

如果不在国外节点,打开邮箱进行确认操作,马上报错:

如果节点在国外,确认邮件后弹出以下界面:

3. 注册国外虚拟电话
填好之后弹出一个界面需要确认手机号,国内的手机号不行,所以需要注册一个虚拟的国外手机号。
打开https://sms-activate.org/cn,现在页面右上角注册账号(需要大写字母)。登录账号之后,左侧搜索OpenAI,打开:

最便宜的是印度10.5卢布,大概一块钱。点击购物车之后提示余额不够,点击资金,进行充值(可以选支付宝等方式):

复制下面的电话号码,到刚才确认电话的界面。其中前两个数字(比如下面巴西的号是55)是区号,选择国家为巴西,输入55后面的号码,确定之后等待网站受到短信:

这个接收短信(激活)好像是有成功率的,如果过几分钟收不到就取消短信,系统会退款,重新选一个号。我是先选印度的一直没收到,就取消重选巴西的,收到短信激活成功了。
激活后选择用户类型,看自己需要了

之后再打开ChatGPT登录界面,登录刚刚的账户就行,下面就可以愉快的玩耍了。

点击上面的OpenAI discord还可以加入discord的OpenAI服务器。
二、 玩转MidJourney
参考B站《Midjourney 人工智能绘画 零基础保姆级教程 》、MidJourney官网
MidJourney可以在discord里面使用,discord就相当于一个巨大的聊天室,集成了很多功能。MidJourney运行在discord中,只需要在聊天框输入prompt,就可以生成需要的图片。下面介绍简单操作。
1. 在聊天室使用MidJourney
打开discord主页进行登录:

在打开后的页面左上角搜索MidJourney,就到了MidJourney板块。
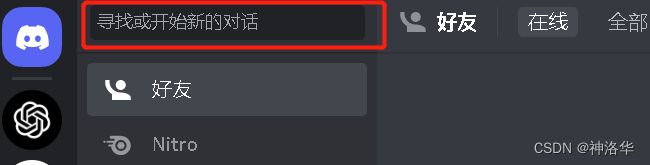
点击左侧newbies新手区,进入之后在聊天框输入/,选择/imagine,就可以输入prompt生成图片了

比如输入network of ideas with galaxy backgroud,生成:

2. 在私人服务器使用MidJourney
在多人服务器,大家都在生成图片,网页经常刷新,容易找不到自己的图。下面介绍创建私人服务器的方法。点击左侧栏+创建自己的服务器:

此时输入/并没有imagine的选项,是因为生成机器人还没有加入服务器。下面进行配置。点击左上方蓝色图标, 弹出窗口点击“寻找或开始新的对话”,输入MidJourney Bot。

点击MidJourney Bot,弹出窗口选择添加至刚刚创建的服务器,下面就可以和刚才一样进行prompt作图了。

三、本地配置Stable Diffusion
- 本地windows跑Stable Diffusion参考:《10分钟Window本地部署stable diffusion AI绘图》,或者视频《AI绘画速成指南,stable-diffusion 2.0 从安装到使用》。安装要求Win10及以上系统,内存16G及以上,有GPU显卡,最好是4G以上的NVIDIA系列,不支持N卡1050以下。
- 没有GPU在
colab跑主要参考《Google Colab尝试 Stable Diffusion》
3.1 百度飞浆跑AIGC模型
打开百度飞浆官网,注册后新建项目。输入以下代码就能跑了:
from paddlenlp import Taskflow
text_to_image = Taskflow("text_to_image", model="CompVis/stable-diffusion-v1-4")
prompt = [
"In the morning light,Chinese ancient buildings in the mountains,Magnificent and fantastic John Howe landscape,lake,clouds,farm,Fairy tale,light effect,Dream,Greg Rutkowski,James Gurney,artstation",
]
image_list = text_to_image(prompt)
for batch_index, batch_image in enumerate(image_list):
# len(batch_image) == 2 (num_return_images)
for image_index_in_returned_images, each_image in enumerate(batch_image):
each_image.save(f"stable-diffusion-figure_{batch_index}_{image_index_in_returned_images}.png") # 保存图片
可选参数:
model:可选,默认为pai-painter-painting-base-zh。
另外支持的还有[“dalle-mini”, “dalle-mega”, “dalle-mega-v16”, “pai-painter-painting-base-zh”, “pai-painter-scenery-base-zh”, “pai-painter-commercial-base-zh”, “CompVis/stable-diffusion-v1-4”, “openai/disco-diffusion-clip-vit-base-patch32”, “openai/disco-diffusion-clip-rn50”, “openai/disco-diffusion-clip-rn101”, “disco_diffusion_ernie_vil-2.0-base-zh”]。num_return_images:返回图片的数量,默认为2。特例:disco_diffusion模型由于生成速度太慢,因此该模型默认值为1。
Disco Diffusion-2.0-base-zh模型,支持中文:
# 注意,该模型生成速度较慢,在32G的V100上需要10分钟才能生成图片,因此默认返回1张图片。
text_to_image = Taskflow("text_to_image", model="disco_diffusion_ernie_vil-2.0-base-zh")
image_list = text_to_image("一幅美丽的睡莲池塘的画,由Adam Paquette在artstation上所做。")
for batch_index, batch_image in enumerate(image_list):
for image_index_in_returned_images, each_image in enumerate(batch_image):
each_image.save(f"disco_diffusion_ernie_vil-2.0-base-zh-figure_{batch_index}_{image_index_in_returned_images}.png")
3.2 colab试用Stable Diffusion-v1-4
官网发布了在线版本,大家可以体验,不过要收费。本地部署的方案,这样就没有数量的限制、不用排队、自由度也很高、可以随意修改配置、替换模型。
直接打开StableDiffusion的GoogleColab notebook,按提示操作,就可以了。英文看的头疼就参考帖子《Google Colab尝试 Stable Diffusion》。这个是使用的Stable Diffusion-v1-4模型,讲解了各种操作。有一点是下面阅读同意的选项是没有的,其它正常跑。
步骤5:获取Hugging Face 的 Stable Diffusion 的访问权限
前往 https://huggingface.co/CompVis/stable-diffusion-v1-4勾选同意并点击按钮:

3.3 colab试用stable-diffusion-2
如果要试验stable-diffusion-2的话,参考https://huggingface.co/stabilityai/stable-diffusion-2:
pip install --upgrade git+https://github.com/huggingface/diffusers.git transformers accelerate scipy
from diffusers import StableDiffusionPipeline, EulerDiscreteScheduler
import torch
model_id = "stabilityai/stable-diffusion-2"
# Use the Euler scheduler here instead
scheduler = EulerDiscreteScheduler.from_pretrained(model_id, subfolder="scheduler")
pipe = StableDiffusionPipeline.from_pretrained(model_id, scheduler=scheduler, revision="fp16", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt, height=768, width=768).images[0]
image.save("astronaut_rides_horse.png")
image
如果想一次生成多张图片,控制每张图迭代次数,并都一一保存,可以运行以下代码:
from PIL import Image
generator = torch.Generator("cuda").manual_seed(1024)
def image_grid(imgs, rows, cols):
assert len(imgs) == rows*cols
w, h = imgs[0].size
grid = Image.new('RGB', size=(cols*w, rows*h))
grid_w, grid_h = grid.size
for i, img in enumerate(imgs):
grid.paste(img, box=(i%cols*w, i//cols*h))
return grid
num_cols = 3
num_rows = 4
prompt = ["A cute English shorthair cat"] * num_cols
all_images = []
for i in range(num_rows):
images = pipe(prompt,num_inference_steps=50).images
for j,img in enumerate(images):
img.save(f"img_row{i}_clo{j}.png")
all_images.extend(images)
grid = image_grid(all_images, rows=num_rows, cols=num_cols)
grid
更多API和操作,还是参考StableDiffusion的GoogleColab notebook。
3.4 其它功能
- Stable Diffusion修图:参考《Stable Diffusion一句话帮你换图,网友魔改《戴珍珠耳环的少女》。效果展示:

- 生成动漫美女,参考《AI绘画 stable diffusion二次元美少女测试》


测试一下stable的二次元美少女,全用了日本的画家,包括: - 小岛文美Ayami Kojima/山本高远takato yamamoto 用于华丽的浮世绘风格
- 副岛成记shigenori soejima/皆叶英夫minaba hideo/小畑健takeshi obata 用于人物造型
- 寺田克也katsuya terada 用于表现结构线
- 空山基Hajime Sorayama 用于塑造盔甲
关于二次元风格的要点:
-
二次元有两种风格 :动画Anime/漫画Manga ,动画人物细节较少,动作比较僵硬但表情丰富。漫画细节动态多,背景丰富但没有表情。
-
关键词权重是按顺序排列的,二次元风格很吃画风,要比其他风格更加注意权重。
-
1-3号图是按照正常的书写习惯,描述+画家 +效果。结果画家没有权重,画面只体现了非常普通的美少女风格。用的画家是皆叶英夫/小畑健
-
从四号开始把画家放在首位。粉丝推荐用米山舞,但谷歌查她的英文名只有不到10张作品且AI无法识别,因此我用了她曾经参与过的动漫Fate,放在句式的第一位,变成:详细描述fate的漫画海报 关于一个什么少女,什么衣服等等。画风就秒变专业。
-
第五张,也是Fate开头,把漫画改成动画,人物立体了,但动态没有那么丰富。
-
第六张前置了副岛成记,人物就变成他画的那种细长条身材。
-
第七张前置了小岛文美,变成华丽成熟画风。
-
第八张前置了小岛文美+新艺术风格,变成华丽卡牌造型。
-
第九张前置了山本高远,变成复古的风格。
-
寺田克也/空山基 夹杂在中间人物描述里面,能丰富细节。
-
想要好看的造型最好在末尾加上artgerm和穆夏。这两个人相当于二次元钥匙。
-
千万不要加的词是pixiv,会变成小学生画风。
-
AI对日本画家收录很少,所以用整部动漫的名字比画家名字更容易出效果,但要连载时间很长的动漫才可以,例如连载12年的进击的巨人可以识别,而鬼灭之刃只有4年就无法识别。而Fate是一个历时18年包含很多动画,漫画,游戏,小说的综合体,因此风格非常的突出。
-
手部依然不够准确,动作不够丰富,元素多的图片像素不高。
- 二次元进阶教程《AI作画stable diffusion 本地化的教程收集·进阶教程(二次元向)收集·资源指路》、《使用stable-diffusion-webui的Textual Inversion功能》
我比较喜欢的动漫风格:
- 约会大作战:英文名DATE A LIVE

- 科学电磁炮:Toaru Kagaku no Railgun