前端面试题(带文字+代码解析),我不相信你看不懂(2022.11.04)
HTML部分(包括h5)
1. 行内元素有哪些?块级,行内块元素有那些?空元素有那些?
此题较为简单,这里我们不需要把所有的都写出来,只要大概写出比较有代表性的就可以了
- 行内元素(display:inline):a、span、small、strong、em、i…
- 块级元素(display:block):div,p,footer,h1~h6,header…
- 行内块(display:inline-block):img、input
- 空元素(void):br,hr
这个问题很容易衍生出一个高频问题:转换问题
比如,行内怎么转成块级
来代码演示:
<body>
这是一条消息
这是第二条消息
<div>这是一个divdiv>
body>
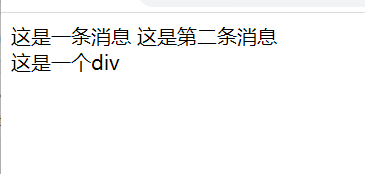
这是浏览器效果没错吧
我们给div转换一下
div {
display: inline;
}

div就变成行内元素了,其它的同理,就是用display来进行转换
这里也简单带着大家回忆下三种元素的区别
行内元素:不独占一行,而且不可以设置宽高
行内块元素:不独占一行,但是可以设置宽高
块级元素:独占一行,并且可以设置宽高
2. 页面导入样式时,使用link和@import有什么区别
我们首先知道,link是一个标签,是我们在HTML中导入CSS时用到的
而 @import是在CSS中导入样式的
区别一:先创造的是link,然后之后才创造的@import(所以在兼容性上看,link比@import要好)
区别二:加载顺序有区别,浏览器先加载的是标签link,后加载@import
区别三:导入的位置不同(有眼就能看出来,所以没有以上两点重要)
3.title和h1,b与strong,i与em的区别
这个其实主要考察的是我们身为一个前端程序员对标签广度的认知
title与h1的区别
我们先要知道,我们在写代码的时候,是不是先去写title的,也就是标题,然后在下面我们才会去写div啦,h1啦,等等
这就涉及到一个问题,一个网页在上线以后,我们会用各种搜索引擎去搜索关键字

就比如这样,那么我们的搜索引擎亦或者是爬虫,在查找对应网站的时候,也是从上往下搜索关键字的,先看title有没有我们查的关键字,没有再去往下走,才会看到h1,h1要是没有,继续往下找。这样,如果我们在最开始的title都没找到我们查的这个关键字,那么,这个网页绝对不会靠前显示给我们的
title与h1的区别
定义:
title:概括了网站的信息,可以大致告诉搜索引擎或者用户,关于这个网站的主题是什么
h1:文章的主题内容是什么,即网站内容最主要是什么
区别:
- title显示在网页标题上, h1显示在内容上
- title比h1更加重要(title > h1)==》对于seo的了解
- 网站的logo都是用h1标签包裹的
b与strong的区别:
定义 :
- b:实体标签,用来给文字加粗的
- strong:逻辑标签,用来加强字符语气的
区别 :
- b标签只有加粗的样式,没有实际的含义
- strong表示标签内的字符比较重要,用以强调的
注意:为了符合CSS3的规范,b尽量少用
i与em的区别
定义:
- i:实体标签,用来做文字倾斜的
- em:逻辑标签,用来强调文字内容的
区别:
- i只是一个倾斜标签,没有实际含义
- em表示标签内的字符比较重要,用以强调的
场景:
i更多用在字体图标,em一般用在术语上
4. img标签的title和alt有什么区别
区别一:
title:鼠标放在图片显示的值
alt:图片无法加载显示的值
区别二:
在seo层面上,蜘蛛抓取不到图片的内容,所以前端在写img标签时为了增加seo效果要加入alt属性来描述这张图时什么内容或者关键词
5. png,jpg,gif 这些图片格式解释一下,分别什么时候用?
png:无损压缩,尺寸体积要比jpg/jpeg的大,适合做小图标
jpg:采用压缩算法,有一点失真,比png体积要小,适合做一些中大型图片
gif:一般是用来做动图的,但是现在很少去用了
webp:同时支持有损压缩和无损压缩,相同质量的图片,webp具有更小的体积,但是兼容性上不是很好
6. 语义化标签
我们要知道,在h5之前我们写一个网页的布局是什么样子的
<div class="header">div>
<div class="footer">div>
我们都是这么写的,然后我们一看,哦!这个是头部,这个是底部
在h5以后新加了一些标签,所以写法就发生了变化
<header>header>
<footer>footer>
最简单来看,有什么好处呢
让人更容易读懂(增加代码可读性)、维护性增强
其次在SEO层面呢
让搜索引擎更容易读懂,有助于爬虫抓取更多的有效信息,爬虫依赖于标签来确定上下文和各个关键字的权重(SEO)。
补充优点:
在没有 CSS 样式下,页面也能呈现出很好地内容结构、代码结构。
缺点:
老生常谈IE老版本不兼容问题
但是有解决方法
通过html5shiv.js去处理
文件可以去网上搜,作用就是让IE浏览器识别并支持HTML元素
CSS部分
1. 介绍一下CSS的盒子模型
CSS的盒子模型有哪些:
- 标准盒子模型
- IE盒子模型
CSS的盒子模型区别:
标准的盒子模型:

从图中可以看出:标准的w3c盒子模型包括:margin,boder,padding,content,并且content部分不包含其它部分

而IE盒子模型,我们在图中看到,它也包括:margin,border,padding,content,但是和标准w3c盒子模型相比,content部分包含了border和padding
进阶:如何转换盒子模型
通过CSS来转换盒子模型:box-sizing
box-sizing : content-box 标准盒子模型
box-sizing : border-box IE盒子模型
2. line-height和height的区别
我们第一反应,line-height不是行高吗,height不是高嘛
小伙伴们,你们说能这么简单嘛,不要太小瞧这道题,这道题在面京东的时候被问过哦
首先line-height是行高,height是高这个解释是对的,但是不完整
line-height是每一行文字的高,如果文字换行,则这个盒子的高度会被撑大(行数*行高)
而height是一个不变的值,就是这个盒子的高度
3. CSS选择符有哪些?哪些属性可以继承?
CSS选择符:
- id选择器( # myid)
- 类选择器(.myclassname)
- 标签选择器(div, h1, p)
- 相邻选择器(h1 + p)
- 子选择器(ul > li)
- 后代选择器(li a)(中间是空格分隔)
- 通配符选择器( * )
- 属性选择器(a[rel = “external”])
- 伪类选择器(a:hover, li:nth-child)
CSS哪些属性可以继承:
文字系列:font-size、color、line-height、text-align…
不可继承属性:
border padding margin width height
4. 清除浮动的方式
- 触发BFC:父级添加overflow属性(父元素添加overflow:hidden)(不推荐
- 额外标签法:多创建一个盒子,添加样式:clear:both (此方法较老)
- after方式:元素:after{ content:’ ’ , display : block ; clear : both }(常用!重点)
- 使用before和after双伪元素清除浮动,这跟第三种实际上是一个意思
5. 对BFC规范的理解
BFC规范,即块级格式化上下文:block formatting context
BFC就是页面上一个隔离的独立容器,容器里面的子元素不会影响到外面的元素
意思就是:如果一个元素具有BFC,那么内部元素再怎么弄,都不会影响到外面的元素
如何触发BFC呢
- float的值非none
- overfloat的值非visible
- display的值为:incline-block、table-cell…
- position的值为:abslout、fixed
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Documenttitle>
<style>
* {
margin: 0;
padding: 0;
}
ul {
list-style: none;
border: 1px solid pink;
float: left;
}
ul li {
float: left;
margin: 10px;
width: 100px;
height: 100px;
background: skyblue;
}
style>
head>
<body>
<ul>
<li>1li>
<li>2li>
<li>3li>
ul>
<p>这是一段文字p>
body>
html>
这里我是用浮动触发的BFC

可以看到已经触发了BFC
6. CSS优先级算法
我们先要有一个优先级的概念
优先级比较:!important > 内联样式 > id > class > 标签 > 通配符(*)
这个大家都知道吧,我就不来做演示了
为什么会有这个优先级的比较呢?我用代码引出来
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Documenttitle>
<style>
ul li.lis1 {
background: pink;
}
.lis1 {
background: skyblue;
}
style>
head>
<body>
<ul>
<li class="lis1">111li>
<li>222li>
<li class="lis3">333li>
<li>444li>
<li class="lis5">555li>
ul>
body>
html>

按照常规来说,我下面的lis1应该是覆盖到上面的样式了,为什么还是会呈现上面的样式呢?
这就说明,我们常规的优先级比较已经不太够用了
由此,就有了优先级运算
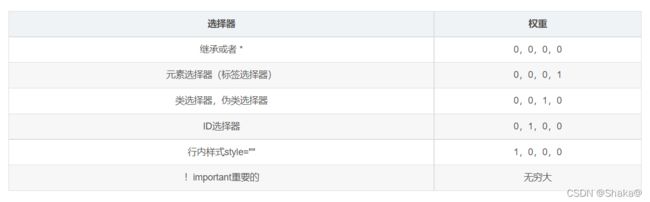
欧克,一张表直接搞定权重
权重叠加:如果是复合选择器,则会有权重的叠加,需要计算权重
太抽象,来代码实际计算一下
<head>
<style>
li {
color:green;
}
/* li 的权重是 0,0,0,1 */
ul li{
color :red;
}
/* 复合选择器权重叠加,ul li权重 0,0,0,1 + 0,0,0,1 =0,0,0,2 */
.nav li{
color:pink;
}
/* .nav li 权重 0,0,1,0 + 0,0,0,1 = 0,0,1,1 */
<style>
head>
<body>
<ul class="nav">
<li>大猪蹄子li>
<li>大肘子li>
<li>猪尾巴li>
ul>
body>
- div ul li----------> 0,0,0,3
- .nav ul li -------------->0,0,1,2
- a:hover ---------------->0,0,1,1 /* 伪类选择器*/
- .nav a-------------------->0,0,1,1
注意点:
5. 等级判断是从左到右,如果某一位数值相同,则判断下一位数值
6. 继承的权重是0
7. 权重可以叠加,但是永远不会有进位
7. CSS画三角形
这道题我没有遇到过,也是看别人的面经上遇到过,这里就带着大家画一下
用边框画(boder)
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Documenttitle>
<style>
.box {
width: 0;
height: 0;
border-left: 100px solid #000;
border-right: 100px solid transparent;
border-top: 100px solid transparent;
border-bottom: 100px solid transparent;
}
style>
head>
<body>
<div class="box">div>
body>
html>

很简单哈,我们只保留左边的即可,别的方向的三角形同理,把不需要的变成透明即可
这是最最简单的方式了
8. 盒子水平居中
问:一个盒子不给宽度和高度如何水平居中
代码如下
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Documenttitle>
<style>
* {
margin: 0;
padding: 0;
}
.father {
width: 500px;
height: 500px;
border: 5px solid skyblue;
}
.son {
background: pink;
}
style>
head>
<body>
<div class="father">
<div class="son">这是sondiv>
div>
body>
html>

样式如图
解决方法一:第一反应弹性盒子(这个真的太常用了)
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Documenttitle>
<style>
* {
margin: 0;
padding: 0;
}
.father {
display: flex;
justify-content: center;
align-items: center;
width: 500px;
height: 500px;
border: 5px solid skyblue;
}
.son {
background: pink;
}
style>
head>
<body>
<div class="father">
<div class="son">这是sondiv>
div>
body>
html>

完美解决
方式二:定位(子绝父相)
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Documenttitle>
<style>
* {
margin: 0;
padding: 0;
}
.father {
position: relative;
width: 500px;
height: 500px;
border: 5px solid skyblue;
}
.son {
position: absolute;
left: 50%;
top: 50%;
background: pink;
transform: translate(-50%, -50%);
}
style>
head>
<body>
<div class="father">
<div class="son">这是sondiv>
div>
body>
html>
也是可以解决的,但是这里注意要加个tansform,要不会歪
9. display有哪些值,以及作用

最常用的就是前四个
10. 在网页中应该使用奇数还是偶数的字体,为什么?
比较冷门的问题,稍微了解就好
答案:偶数
偶数可以让字体在浏览器上表现地更好看
而且ui给前端一般设计图都是偶数的,这样不管布局也好,转换px也好,方便一点
11. position有哪些值?分别是根据什么定位的
默认值:static 表示没有定位
fixed :固定定位,根据浏览器窗口进行定位(视口)
relative :相对定位,相对于自身定位,不脱离文档流
absolute :绝对定位,相对于第一个有relative的父元素,脱离文档流
relative,absolute区别:
- relative不脱离文档流,absolute脱离文档流
- relative相对于自身定位,absolute相对于第一个有relative的父元素
- relative如果有left、right、top、bottom,则只能有left和top
- absolute如果有left、right、top、bottom,则都可以有
12. rem和em区别
这俩是在移动端布局比较多的,所以我们更多地会考虑到一个适配的问题
rem和em是一个相对单位,所以用它可以解决一些问题
它俩是相对于font-size的
em针对于父元素的font-size
rem只针对HTML元素的font-size
实际上,因为实际开发,父元素可能会很多,我们找的费劲 所以实际上我们会用rem
13. 自适应布局
注意这里不要回答rem,rem只是一种单位,不是我们布局的一种方式(方案)吗,只是用到了它,不是说它就是核心
我们根本是要让HTML根节点,自适应(发生变化)
淘宝无限适配(github有,cv即可):淘宝无限适配+布局单位使用rem单位就可以了
14. 响应式布局
淘宝其实不是一个纯粹的响应式,因为换成移动端的时候,会发现url变了
响应式是什么呢?
一个URL可以响应多端(例如bootstrap官网)
语法结构:利用媒体查询
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Documenttitle>
<style>
* {
margin: 0;
padding: 0;
}
ul {
list-style: none;
}
ul li {
display: inline-block;
width: 260px;
background: pink;
}
@media only screen and (max-width:1000px) {
ul li :last-child {
display: none;
}
}
style>
head>
<body>
<ul>
<li>首页li>
<li>我的li>
<li>热门li>
<li>关注li>
<li>粉丝li>
ul>
body>
html>
- only:可以排除不支持媒体查询的浏览器
- screen:设备类型
- max-width:临界值
还有一种情况,我们有一张很大的图片,我们是不是要给这个图片也做一下响应式
这叫响应式图片 :可以做性能优化
<picture>
<source srcset="1.jpg" media="min-width:1000px">
<source srcset="2.jpg" media="min-width:700px">
<source srcset="3.jpg">
picture>
意思就是不同窗口大小,显示不同尺寸图片
15.对Css预编语言的理解?有哪些区别?
预处理语言
扩充了 Css 语言,增加了诸如变量、混合(mixin)、函数等功能,让 Css 更易维护、方便
本质上,预处理是Css的超集
包含一套自定义的语法及一个解析器,根据这些语法定义自己的样式规则,这些规则最终会通过解析器,编译生成对应的 Css 文件
都有哪些预处理语言
- sass
- less
- stylus
区别:
基本使用
less和scss
.box {
display: block;
}
sass
.box
display: block
stylus
.box
display: block
三者的嵌套语法都是一致的,甚至连引用父级选择器的标记 & 也相同
区别只是 Sass 和 Stylus 可以用没有大括号的方式书写
less
.a {
&.b {
color: red;
}
}
变量
变量无疑为 Css 增加了一种有效的复用方式,减少了原来在 Css 中无法避免的重复「硬编码」
less声明的变量必须以@开头,后面紧跟变量名和变量值,而且变量名和变量值需要使用冒号:分隔开
@red: #c00;
strong {
color: @red;
}
sass声明的变量跟less十分的相似,只是变量名前面使用@开头
$red: #c00;
strong {
color: $red;
}
stylus声明的变量没有任何的限定,可以使用$开头,结尾的分号;可有可无,但变量与变量值之间需要使用=
在stylus中我们不建议使用@符号开头声明变量
red = #c00
strong
color: red
作用域
Css 预编译器把变量赋予作用域,也就是存在生命周期。就像 js一样,它会先从局部作用域查找变量,依次向上级作用域查找
sass中不存在全局变量
$color: black;
.scoped {
$bg: blue;
$color: white;
color: $color;
background-color:$bg;
}
.unscoped {
color:$color;
}
编译后
.scoped {
color:white;/*是白色*/
background-color:blue;
}
.unscoped {
color:white;/*白色(无全局变量概念)*/
}
所以,在sass中最好不要定义相同的变量名
less与stylus的作用域跟javascript十分的相似,首先会查找局部定义的变量,如果没有找到,会像冒泡一样,一级一级往下查找,直到根为止
@color: black;
.scoped {
@bg: blue;
@color: white;
color: @color;
background-color:@bg;
}
.unscoped {
color:@color;
}
编译后:
.scoped {
color:white;/*白色(调用了局部变量)*/
background-color:blue;
}
.unscoped {
color:black;/*黑色(调用了全局变量)*/
}
混入
混入(mixin)应该说是预处理器最精髓的功能之一了,简单点来说,Mixins可以将一部分样式抽出,作为单独定义的模块,被很多选择器重复使用
可以在Mixins中定义变量或者默认参数
在less中,混合的用法是指将定义好的ClassA中引入另一个已经定义的Class,也能使用够传递参数,参数变量为@声明
.alert {
font-weight: 700;
}
.highlight(@color: red) {
font-size: 1.2em;
color: @color;
}
.heads-up {
.alert;
.highlight(red);
}
编译后
.alert {
font-weight: 700;
}
.heads-up {
font-weight: 700;
font-size: 1.2em;
color: red;
}
Sass声明mixins时需要使用@mixinn,后面紧跟mixin的名,也可以设置参数,参数名为变量$声明的形式
@mixin large-text {
font: {
family: Arial;
size: 20px;
weight: bold;
}
color: #ff0000;
}
.page-title {
@include large-text;
padding: 4px;
margin-top: 10px;
}
stylus中的混合和前两款Css预处理器语言的混合略有不同,他可以不使用任何符号,就是直接声明Mixins名,然后在定义参数和默认值之间用等号(=)来连接
error(borderWidth= 2px) {
border: borderWidth solid #F00;
color: #F00;
}
.generic-error {
padding: 20px;
margin: 4px;
error(); /* 调用error mixins */
}
.login-error {
left: 12px;
position: absolute;
top: 20px;
error(5px); /* 调用error mixins,并将参数$borderWidth的值指定为5px */
}
JavaScript部分
1. 延迟加载JS有哪些方式
这里不考虑settimeout延迟器的使用,这里重点说
async,defer
我们知道,我们写JS代码,或者引入JS文件都是在后面,由此让我们的浏览器先解析DOM,然后再去解析JS代码,这样,即使我们JS的代码出现错误了,也不会影响我们DOM的正常的渲染
DOCTYPE html>
<html lang="en">
<head>
<title>0406title>
<script src="./0406.js">script>
head>
<body>
<div id="box">div>
body>
html>
html>
就好比这样,那么,如果我们要把script写在上面,还想成功运行要怎么办呢?这就需要我们的async,defer 了,比如,我们先不加看看什么效果
0406.html
DOCTYPE html>
<html lang="en">
<head>
<title>0406title>
<script src="./0406.js">script>
head>
<body>
<div id="box">div>
body>
html>
0406.js
console.log(document.getElementById('box'));

不出预料,我们是无法获取到box的,那么我们加async试试
DOCTYPE html>
<html lang="en">
<head>
<title>0406title>
<script async src="./0406.js">script>
head>
<body>
<div id="box">div>
body>
html>

我们加了async获取到了box,我们再试试defer也可以获取到,这里就不放代码了
但是虽然async,defer,都可以获取到(可以做到延迟加载JS),但是他们俩的原理(也可以说是过程)是不一样的
async,defer的区别
这里,三张官方图演示出区别
- 不加async,defer

- 加async

3.加defer

几种颜色代表什么

绿色:HTML加载(解析)
灰色:HTML停止加载
紫色:script脚本下载
粉色:script脚本执行
这三张图一对比,简单清晰明了,就不需要我说啦
2. JS数据类型
JS数据类型有哪些呢?
虽然此题基础,但是很重要
基本类型:string、number、boolean、undefined、null、symbol、bigint
引用类型:object(array,function)
这里如果有小伙伴有笔试的话,可能会考到隐式转换的题,这里用代码给大家看看
<body>
<script>
console.log(true + 1);
console.log('name' + true);
console.log(undefined + 1);
console.log(typeof null);
</script>
</body>

这里注意NaN是一个数值类型(number),但是不是具体的数
还需注意null是一个特殊的object类型
除了这些一般还会问你,
typeof和instanceof的区别
这里我带着大家粗略地说一下
区别一:
typeof返回的结果是一个字符串
什么意思呢,我们得到的不是,number,string,Boolean…吗?
对,的确是这样,但是大家有没有思考,输出的这个number,这难道不是一个字符串吗,带着大家演示一下
console.log(typeof typeof (1));

但是instanceof返回的是一个布尔值
区别二:
我们typeof能检测object类型,但是却检测不出是object类型的哪一个
但是instanceof 可以准确地判断复杂引用数据类型,但是不能正确判断基础数据类型
3. null和undefined的区别
不要说,null代表空,undefined代表未定义,这个不是等于没说嘛
在历史背景上看,作者在设计JS的时候是先设计的null(其实是借鉴了Java的null),当我们用Number转换的时候,null可以被转成0
console.log(Number(null)); // 0
null像在Java里一样,被当作是一个对象,但是,JavaScript的数据类型分为原始类型(primitive)和合成类型(complex)两大类,作者觉得表示“无”,的值最好不是对象。
JavaScript的最初版本没有包括错误处理机制,发生数据类型不匹配时,往往时自动转换类型或者默默地失败,作者觉得,如果null自动转为0,很不容易发现错误。
因此,作者设计了一个undefined
所以,先有null后有undefined,出undefined是为了填补null的坑
JavaScript最初版本是这样区分的,null是一个表示“无”的对象(空对象指针),转为数值时为0,undefined是一个表示“无”的原始值,转为数值时为NaN
总结区别:
1.作者在设计JS的时候是先设计的null(其实是借鉴了Java的null)
2. null会被隐式转换成0,不容易发现错误
3. 先有null后有undefined,出undefined是为了填补null的坑
4. (具体区别):JavaScript最初版本是这样区分的,null是一个表示“无”的对象(空对象指针),转为数值时为0,undefined是一个表示“无”的原始值,转为数值时为NaN
4. == 和 === 有什么不同
大家可能知道的是
==:比较的是值
=== :除了比较值,还比较数据类型
===是严格意义上的相等,相信大家至少会掌握到这个地步,这里带着大家细说一下
大家也可能会判断结果,但是说的话却说不太好
<script>
console.log(1 == '1');
console.log(true == 1);
console.log(null == undefined);
console.log([1, 2] == '1,2');//引用类型转成基本类型
</script>
我们先复习一下哈,以上的输出结果都是true,这个没什么问题,就是一个隐式转换的问题
这里怕有的小伙伴不知道,所以我提一嘴,隐式转换实际上就是用 valueOf()这个方法转换的
valueOf()的定义和用法
valueOf()方法返回Math对象的原始值
该原始值由Math对象派生的所有对象继承
valueOf()方法,通常用JavaScript在后台自己调用,并不显式地出现在代码中
语法:mathObject.valueOf()
总结
== 和 === 有什么不同
==:比较的是值
但是当 == 比较不同的数据类型时,会通过valueOf()方法进行隐式转换
=== :除了比较值,还比较数据类型
5. 事件循环
我们JS是一门单线程的语言,也就是说,同一时间只能做一件事
但是这会导致一个问题:如果这个单线程执行任务队列,前一个任务耗时太长,则后续的任务就不得不一直等待,从而导致程序假死的问题。
为了防止某个耗时任务导致程序假死的问题,JavaScript 把待执行的任务分为了两类:
1.同步任务(synchronous):
- 又叫做非耗时任务,指的是在主线程上排队执行的那些任务
- 只有前一个任务执行完毕,才能执行后一个任务
2.异步任务(asynchronous):
- 又叫做耗时任务,异步任务由 JavaScript 委托给宿主环境进行执行
- 当异步任务执行完成后,会通知 JavaScript 主线程执行异步任务的回调函数
同步任务和异步任务的执行过程:
① 同步任务由 JavaScript 主线程次序执行
② 异步任务委托给宿主环境执行
③ 已完成的异步任务对应的回调函数,会被加入到任务队列中等待执行
④ JavaScript 主线程的执行栈被清空后,会读取任务队列中的回调函数,次序执行
⑤ JavaScript 主线程不断重复上面的第 4
步
图解:

EventLoop (事件循环)的基本概念:
JavaScript 主线程从“任务队列”中读取异步任务的回调函数,放到执行栈中依次执行。这个过程是循环不断的,所以整个的这种运行机制又称为 EventLoop(事件循环)
6. 微任务和宏任务
在学习这个概念之前,我们要有事件循环的概念
JS代码执行流程: 先执行同步任务==>事件循环
事件循环再分为:【宏任务】【微任务】
宏任务(macrotask):
- 异步 Ajax 请求
- setTimeout、setInterval
- 文件操作
- 其它宏任务
微任务(microtask):
- Promise.then、.catch 和 .finally
- process.nextTick
- 其它微任务
宏任务和微任务的执行顺序:
每一个宏任务执行完之后,都会检查是否存在待执行的微任务, 如果有,则执行完所有微任务之后,再继续执行下一个宏任务
也就是说,执行宏任务的前提是清空了所有的微任务
理论大概就是这么多,但是很多时候会给你一段代码题,让你说出输出结果,这里我给大家两段代码以及输出结果,供大家思考和练习
代码一:
<script>
setTimeout(function () {
console.log('1');
})
new Promise(function (resolve) {
console.log('2');
resolve()
}).then(function () {
console.log('3');
})
console.log('4');
</script>
输出结果:2 4 3 1
不知道大家有写对吗?
这个就是个热身,下面这道会了之后,基本这个题型问题不大了
代码二:
<body>
<script>
console.log('1');
setTimeout(function () {
console.log('2');
new Promise(function (resolve) {
console.log('3');
resolve()
}).then(function () {
console.log('4');
})
})
new Promise(function (resolve) {
console.log('5');
resolve()
}).then(function () {
console.log('6');
})
setTimeout(function () {
console.log('7');
new Promise(function (resolve) {
console.log('8');
resolve()
}).then(function () {
console.log('9');
})
})
</script>
</body>
正确的输出顺序是:1 5 6 2 3 4 7 8 9
希望大家都可以做对!
7. JS作用域(里面含有变量提升和函数提升)
这里特别重要哈!
在ES5中除了函数外,JS是没有块级作用域的
函数是有函数作用域的(也叫局部作用域)
举个例子:
<body>
<script>
function fn() {
let a = 10
}
fn()
console.log(a);
</script>
</body>
毫无疑问,a是无法输出的

但是除了函数以外呢,比如
<body>
<script>
for (var i = 0; i <= 10; i++) {
}
console.log(i);//11
</script>
</body>
是可以打印出来的
这就会体现出一个概念:作用域链
作用域链:内部可以访问外部的变量,但是外部不能访问内部的变量
根据内部函数可以访问外部函数变量的这种机制,用链式查找决定哪些数据能被内部函数访问,就称作 作用域链
比如:
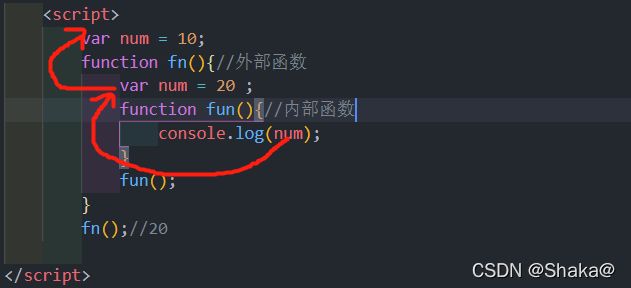
注意:如果内部有,优先查找到内部,如果内部没有,就查找外部
还需注意:全局作用域和局部作用域的问题
- 全局变量:全局作用域下的变量,全局下都可以使用(如果在函数内部,没直接声明赋值的变量也属于全局变量)
- 局部变量:局部作用域下的变量,函数内部使用
例如:
<body>
<script>
f1();
console.log(c);
console.log(b);
console.log(a);
function f1() {
var a = b = c = 9;//这个代码相当于:var a =9 ,b=9,c=9
console.log(a);
console.log(b);
console.log(c);
}
</script>
</body>
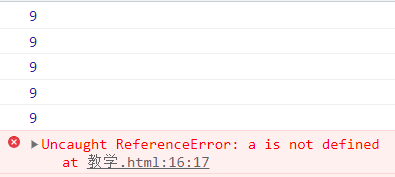
外面的a是无法输出的,因为a不是全局作用域,而b、c是全局作用域,这里如果没看懂的小伙伴思考一下哈
当然,这里涉及了 变量提升(也叫做变量悬挂声明) 的问题
JS代码是由浏览器中的JavaScript解析器来执行的,JS解析器在运行JS代码的时候分为两步:
预解析:JS引擎会把JS里面所有var和function提升到当前作用域的最前面 代码执行:按照代码的书写顺序从上往下执行
预解析分为:
- 变量预解析(也叫变量提升)
- 函数预解析(也叫函数提升)
变量提升:就是把所有变量声明提升到当前的作用域最前面,但是不提升赋值操作
函数提升:就是把所有函数声明提升到当前的作用域最前面,但是不调用函数
这里文字还是看不懂的小伙伴,建议复习一下JS基础
简单一段代码演示把
var num = 10;
fun();
function fun() {
console.log(num);
var num = 20;
//undefined
}
它相当于
var num;
function fun() {
var num;
console.log(num);
num = 20;
}
num = 10;
fun();
懂了吧!再不懂我也没办法啦
这回再回头看上面的代码,它其实等价于
function f1() {
var a;
a = b = c = 9;
console.log(a);
console.log(b);
console.log(c);
}
f1();
console.log(c);
console.log(b);
console.log(a);
这回懂了吧
总结:做题注意点:
- 本层作用域有没有变量提升
- 注意JS除了函数没有块级作用域
再来一道题:
<body>
<script>
var name = 'a'
(function () {
if (typeof name == 'undefined') {
var name = 'b'
console.log('111' + name);
} else {
console.log('222' + name);
}
})()
</script>
</body>
输出111b,你做对了吗
ok,到这种理解了之后,就差不多了
8. JS作用域(this指向+原型)
9. JS对象
首先,有一个问题
console.log([1, 2, 3] === [1, 2, 3]);
结果是false,诶?为什么,不都是对象吗,也都是数组,值也一样,那为什么是false
我们知道,任意的数组都是new出来的,只要new,就会创建一个新对象
这里的两个数组就好比一个双胞胎,长得一样,但是你能说他俩是一个人吗,不能,对不对
所以,引出一个概念
对象是通过new操作符构建出来的,所以对象之间不相等
但是另一种情况呢
<script>
var arr1 = [1, 2, 3]
var arr2 = arr1
console.log(arr1 === arr2);
</script
结果是true,为什么呢?
因为数组是一个引用类型的数据,arr2=arr1后,指向的是同一个地址,并没有去new了
可以理解为 “克隆” ,是同一个基因
所以又有一个新概念
对象注意:引用类型,会指向一个地址
来题练习一下吧
<script>
var obj1 = {
a: 'hello'
}
var obj2 = obj1
console.log(obj1);
(function () {
console.log(a);
var a = 1
})()
</script>
我们对象的key都是字符串类型
<script>
var obj1 = {
a: 1,
'张三': '你好'
}
for (var k in obj1) {
console.log(typeof k);
}
</script>
</body>

看考题:求输出结果
<script>
var a = {}
var b = {
key: 'a'
}
var c = {
key: 'c'
}
a[b] = '123'
a[c] = '456'
console.log(a[b]);
</script>
结果是456,做对了吗
因为b、c不是对象了,是字符串了,后者覆盖前者了
10. typeof和instanceof的区别
我们常说typeof检查简单数据类型,instanceof检查复杂数据类型,但其实还是有所不同的
总结如下:
typeof与instanceof都是判断数据类型的方法,区别如下:
- typeof会返回一个变量的基本类型,instanceof返回的是一个布尔值
- instanceof 可以准确地判断复杂引用数据类型,但是不能正确判断基础数据类型
- 而typeof 也存在弊端,它虽然可以判断基础数据类型(null 除外),但是引用数据类型中,除了function 类型以外,其他的也无法判断
11. instanceof原理
首先,我们知道instanceof的作用,就是帮助我们去检查复杂数据类型
例如
let arr = [1, 2, 3]
console.log(arr instanceof Array);// true
console.log(arr instanceof Object);// true
instanceof其实就是借助原型链往下去找,而原先链实质上就是一个链表
const ins = (target, obj) => {
let p = target
while (p) {
if (p == obj.prototype) {
return true
}
p = p.__proto__
}
return false
}
console.log(ins([1, 2, 3], Object));
ES6部分
1. var、let、const的区别
相信这道题,大家都看烂了,相当的高频了,这里再简单过一遍
var、let、const共同点:都可以声明变量
var、let、const区别:
区别一:
var具有变量提升的机制
let 和 const 没有变量提升的机制
区别二:
var可以多次声明同一个变量
let 和 const 不可以声明同一个变量
区别三:
var、let声明变量
const声明常量(不去改变,固定住)
var和let声明的变量可以再次赋值,但是const不可以了
2. 作用域考题
首先一段代码来热身
<body>
<script>
console.log(str);
var str = 'hello';
console.log(num);
let num = 10;
</script>
</body>
上面是undefined,下面会报错,这个肯定没问题了哈,就是变量提升的问题
let和const没有变量提升性
再来一段代码
<body>
<script>
function demo() {
let n = 2;
if (true) {
let n = 1;
}
console.log(n);
}
demo();
</script>
</body>
结果是输出2,有没有写对呢
但是思考一下,如果这里的let换成var,会输出什么呢?是1。大家要多多思考哈
关于const的不可再赋值的特性,我们来一段代码,思考一下会发生什么
<body>
<script>
const obj = {
a: 1
}
obj = '123'
</script>
</body>
答案是它会报错
<body>
<script>
const obj = {
a: 1
}
obj.a = 123
console.log(obj);
</script>
</body>
但是我们这样是可以改的,没有问题吧
它的意思是:
用const声明的变量是不可以更改的,但是它里面的值是可以修改的
这里的考题大致就是这样,就是要考察你,var、let、const,看你到底名没明白
3. 合并对象的问题
考题:用你知道的方法合并下列对象,尽可能写多个答案
const a = { a:1 , b:4 }
const b = { b:2 , c:3 }
方式是比较多的,比如es6中提供了object.assign(),这种浅拷贝的方式,可以把多个对象进行一个合并
当然,我们也可以自己封装一个方法,进行对象的合并
我们列举几个方法来解决这道题
方法一:object.assign()
<body>
<script>
const a = { a: 1, b: 4 };
const b = { b: 2, c: 3 };
let obj = Object.assign(a, b);
console.log(obj);
</script>
</body>

成功解决
方法二:暴力…(展开运算符)
<body>
<script>
const a = { a: 1, b: 4 };
const b = { b: 2, c: 3 };
const ab = { ...a, ...b }
console.log(ab);
</script>
</body>
效果是一样的哦
方式三:自己封装方法
<body>
<script>
const a = { a: 1, b: 4 };
const b = { b: 2, c: 3 };
function fn(target, source) {
for (var obj in source) {
target[obj] = source[obj];
}
return target
}
console.log(fn(a, b));
</script>
</body>
也是一个效果
这里就提供这三种思路,当然,方式多种多样。大家可以用自己的方法,勤加思考
4. 箭头函数和普通函数的区别
也是一道经典的问题了,很多小伙伴这个问题搞不懂的话,会连带着以后很多关于箭头函数的问题都会不懂
当然哈,不要说书写格式不同哈!等于没说
其实,最关键的是this指向的问题
具体是怎么体现的呢?代码演示
<body>
<script>
let obj = {
a: function () {
console.log(this);
},
b: () => {
console.log(this);
}
}
obj.a()
obj.b()
</script>
</body>
思考,这两个this都指向谁呢

这下就体现出区别的,但是更具体点呢
<script>
let obj = {
a: function () {
return function () {
console.log(this);
}
}
}
obj.a()()
</script>
比如这段代码指向是谁呢?
细心的小伙伴发现这是一个闭包对不对,那这里的this肯定是指向window的了
但是,如果我们return里面不是普通函数,而是箭头函数呢
<script>
let obj = {
a: function () {
return () => {
console.log(this);
}
}
}
obj.a()()
</script>

哦!指向了我们的大对象obj
这里总结一下,我们的箭头函数的this指向在定义的时候就已经决定了,而且是不可修改的(不能有call,apply,bind)
箭头函数的this指向定义的时候,外层第一个普通该函数的this
但是我们的普通函数是可以修改this指向的
其次,箭头函数是不可以new的(也就是不可以当作构造函数)
<script>
let run = () => {
return shaka
}
console.log(new run());
</script>
![]()
提示我们,不可以是一个构造函数
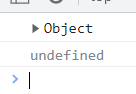
还有,箭头函数是没有prototype的
<script>
let run = () => {
return 111
}
console.log(run.prototype);
</script>
提示我们没被定义
补充:箭头函数是没有arguments的
<script>
let run = () => {
console.log(arguments);
return shaka
}
run()
</script>

提示我们arguments没被定义,如果这里是一个普通函数的话,就是有arguments对象的
总结:
- 箭头函数的this指向在定义的时候就已经决定了,而且是不可修改的(不能有call,apply,bind),箭头函数的this指向定义的时候,外层第一个普通该函数的this
- 箭头函数是不可以new的(也就是不可以当作构造函数)
- 箭头函数是没有prototype的
- 箭头函数是没有arguments的
5. promise有几种状态以及发展史
我们知道,promise不论是在哪里,都是亘古不变的一个考题,考法特别多
一般会直接问你,promise有几种状态啊,然后就会问你,有没有手写过promise啊
或者也会问你promise有几种状态啊,promise解决什么问题了啊,promise以及generator,或者说async,await它们之间的区别
这里我们围绕promise的几种状态说起,我后面会单出一篇文,系统地来讲promise
promise三种状态:
pending(进行中)、fulfilled(已成功)、rejected(已失败)
那么promise诞生是为了解决什么问题呢?
promise是异步编程的一种解决方案,最突出的就是解决了我们所称的“地狱回调”的问题
就是把异步,写成同步的感觉,一直.then下去
这样我们就不用一直嵌套了,比如我们Vue中用axious发请求就用promise
这里地狱回调的代码我就不详细说了哈,等我出文哈!
这里会考什么呢?手写promise,或者实现一个promise.all()
给大家代码演示一下
Promise.all = function (promises) {
return new Promise((resolve, reject) => {
// 参数可以不是数组,但必须具有 Iterator 接口
if (typeof promises[Symbol.iterator] !== "function") {
reject("Type error");
}
if (promises.length === 0) {
resolve([]);
} else {
const res = [];
let count = 0;
const len = promises.length;
for (let i = 0; i < len; i++) {
//考虑到 promises[i] 可能是 thenable 对象也可能是普通值
Promise.resolve(promises[i])
.then((data) => {
res[i] = data;
if (++count === len) {
resolve(res);
}
})
.catch((err) => {
reject(err);
});
}
}
});
};
但是随着我们的发展,.then已经不能满足我们的需求了,就比如我们.then写多了,它还是乱套对不对,也不是那么好维护
在这个基础上,产生了一个语法糖generator
generator就是为了解决我们promise写起来过于复杂的问题的
是为了解决我们promise问题的
形式上,generator是一个普通函数,但是有两个特征
- function关键字与函数名之间有一个星号
- 函数体内部使用yieid表达式,定义内部不同的状态
后来我们发现generator这个方法还是不够简洁
就有了我们现在的async、await
这大概就是我们promise的发展史了,简单带着大家回顾一下
后面针对promise完整的各种知识,等我出文吧!
6. Set和Map有什么区别
Set是一种叫做集合的数据结构,Map是一种叫做字典的数据结构
什么是集合?什么又是字典?
集合 是由一堆无序的、相关联的,且不重复的内存结构【数学中称为元素】组成的组合
字典 是一些元素的集合。每个元素有一个称作key 的域,不同元素的key 各不相同
如果学过Java的朋友对这两个数据结构是很熟悉的,用法也基本一致
- Map是键值对,Set是值的集合
- Map可以通过get方法进行取值,而Set不行,因为它只有值
- 都能通过迭代器进行for…of进行遍历
- Set的值是唯一的可以进行数组去重,而Map由于没有格式限制,可以进行数据存储
Vue部分
1. 为什么data要是个函数
首先,我们要先说明,我们data是个函数,是针对于Vue组件化开发的
在除App.vue以外的组件,data才必须使用函数形式
也就是说,甚至我们的App.vue组件的data都可以是对象的形式
我们先从最基础的 ,非组件化开发讲起,也就是外部导入vue.js文件的形式
在这里,我们data有两种写法
- 对象式
- 函数式
new Vue({
el:'#app',
data:{}
})
new Vue({
el:'#app',
data(){}
})
我们之所以在App.vue组件写对象形式是因为,我们App.vue组件是不需要来回调用的(当然,还是推荐大家都写成函数形式)
为什么data要是个函数?
我先把结论给大家
之所以是个函数,是因为一个组件可能会被多处调用,而每一次调用就会执行data函数,并返回新的数据对象,我们写成函数的形式,可以避免多处调用之间的数据污染
我不知道大家是否真正理解这个含义
所以我打算用最简单的代码,演示一下如果用对象的话,会有什么后果
<script>
let a = () => {
return {
name: 'shaka',
address: '辽宁东北'
}
}
let b = {
name: 'virgo',
address: '辽宁葫芦岛'
}
a.name = 'sssss'
console.log(a());
b.name = 'hhhh'
console.log(b);
</script>
结果是什么呢?

对象里的值会变,但是函数內不会
这很关键
因为我们每个组件都会有自己的data,而我们使用组件化开发,是不是就是因为其复用性,我们会经常调用各个组件,我们在调用这个组件的时候,里面的data里的内容都改变了,那我们,还说什么复用性呢
2. Vue2生命周期
先来图吧,我感觉一张图足够唤起大家的回忆了
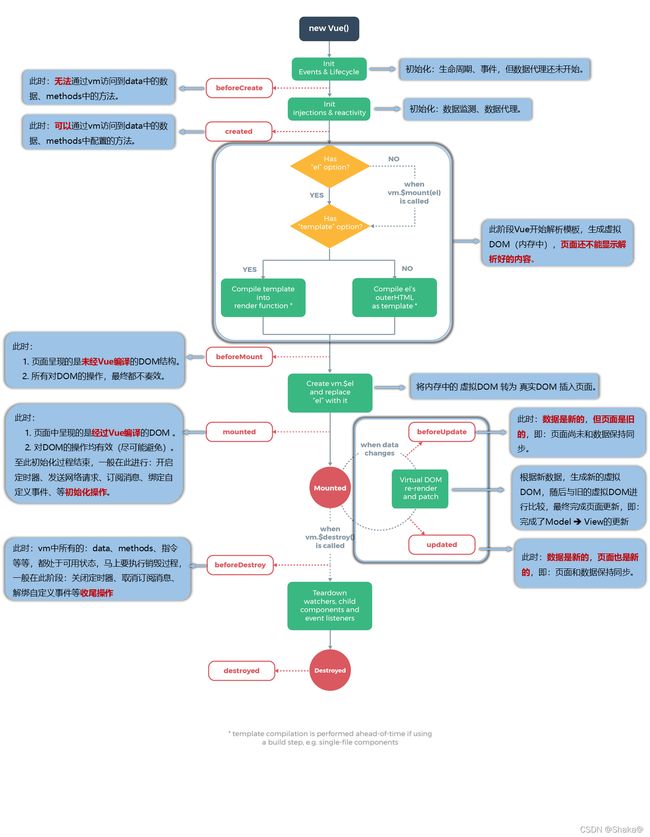
有哪些生命周期:
系统自带的8个构造函数(也可以说是4对)
一旦进入页面或者组件,会执行哪些生命周期,顺序是什么
前四个:beforeCreate,created, beforeMount, mounted。
我就 不带着大家演示代码了,比较这就是个复习,从头开始讲的话篇幅太长了
在哪个阶段会有$el,在哪个阶段会有 $data
大家打印试一下就可以了,我这里总结一下
beforeCreate:啥也没有
created:有data,没有el
beforeMount:有data,没有el
mounted:都有
需要注意什么呢?
我们加入keep-alive会多两个生命周期
2. keep-alive
3. v-if和v-show区别
这两个指令都可以做到让一个元素展示出来以及消失掉(注意,我这里可没说组件,v-show是不可以和template一起使用的)
一、实现原理不同:
- v-if 指令会动态地创建或移除 DOM 元素,从而控制元素在页面上的显示与隐藏
- v-show 指令会动态为元素添加或移除 style=“display: none;” 样式,从而控制元素的显示与隐藏
由此我们知道:
在使用template时,v-show将失去作用。因为v-show是设置显示与隐藏,而template是没有实际东西的dom,所以v-show与template联合使用将失效。
也因此,我们初次加载,v-if比v-show好,页面不会做加载盒子
二、性能消耗不同:
v-if 有更高的切换开销,而 v-show 有更高的初始渲染开销。因此:
- 如果需要非常频繁地切换,则使用 v-show 较好
- 如果在运行时条件很少改变,则使用 v-if 较好
还有就是,v-if是可以配合v-elseif、v-else搭配使用的
但是需要注意的是:
v-if与v-else语句需要联合使用,如中间加了其他语句如:P标签,使上下不连贯儿将导致报错!!但是v-if仍可以使用
4. v-if和v-for优先级
这道题就当是一个拓展就好,就是怕大家看到后麻爪
我们优先级高与低,是不是取决于源码
就好比我们的生命周期一样
v-for的优先级会比v-if高
是在源码中体现出来的
5. computed、methods、watch区别
我们这里做一个详解,先引出概念,再对比出区别
<body>
<div id="app">
{{first + " " + last}}
div>
<script>
//创建了一个Vue实例
var vm = new Vue({
el: '#app',
data: {
first: "Jin",
last: "Lin"
}
})
script>
body>
我想让页面上显示Jin Lin,我在插值中是这个写法,可以发现,他成语句了,也就是有逻辑了,但是我们不想在模版的插值中去写逻辑,怎么办
我们引出一个概念:计算属性
<body>
<div id="app">
{{full}}
div>
<script>
//创建了一个Vue实例
var vm = new Vue({
el: '#app',
data: {
first: "Jin",
last: "Lin"
},
computed: {
full: function () {
console.log('计算了');
return this.first + " " + this.last
}
}
})
script>
body>
计算属性和别的最重要的区别就是:它还是属性,它和data里的属性最大的区别就是,它是通过计算得来的
计算属性有一个缓存的机制:就是计算属性依赖的值不发生改变,计算属性就不会发生计算
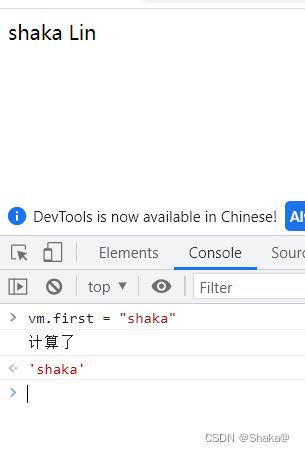
除了计算属性,我们还可以通过方法来达到相同的效果
<body>
<div id="app">
{{full()}}
div>
<script>
//创建了一个Vue实例
var vm = new Vue({
el: '#app',
data: {
first: "Jin",
last: "Lin"
},
methods: {
full: function () {
return this.first + " " + this.last
}
},
})
script>
body>
只不过我们需要用()调用一下
但是这种方法,是没有计算属性有效的,为什么这么说呢
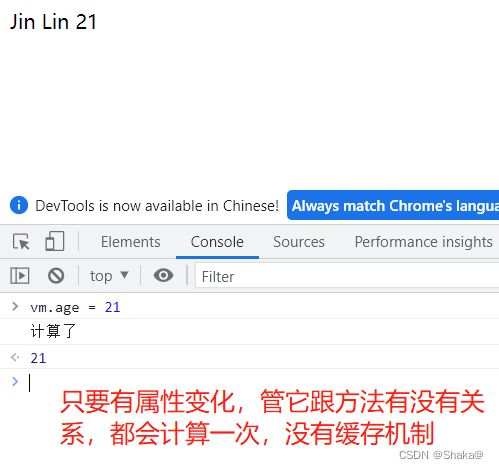
所以方法没有缓存,它的性能显然没有计算属性要高
除了以上的两种,还有一种,叫做侦听
<body>
<div id="app">
{{full}}
{{age}}
div>
<script>
//创建了一个Vue实例
var vm = new Vue({
el: '#app',
data: {
first: "Jin",
last: "Lin",
full: "Jin Lin",
age: "18"
},
watch: {
first: function () {
console.log('计算了一次');
this.full = this.first + "" + this.last
},
last: function () {
console.log('计算了一次');
this.full = this.first + "" + this.last
}
}
})
script>
body>

watch也有缓存
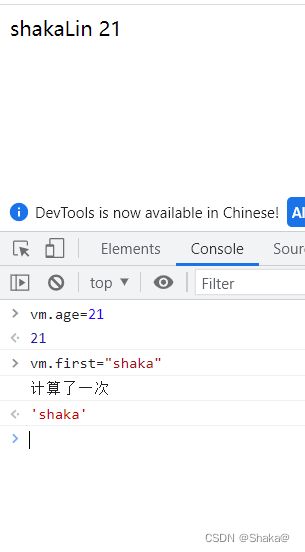
总结:
watch和computed和methods的区别:
watch和computed具有缓存的机制,methods没有
watch和computed区别:
watch可以开启异步任务,computed不可以开启异步,因为它依靠返回值
computed可以完成的功能,watch都可以完成
6.
手写部分
1. 轮播图(尚未写完)
老土的手写题,直接写吧
最重要的两点:Css以及JS,尤其是JS
先布局吧
<div class="container">
<ul class="ul-img">
<li class="li-img">1li>
<li class="li-img">2li>
<li class="li-img">3li>
<li class="li-img">4li>
<li class="li-img">5li>
ul>
<div class="prev">
<span><span>
div>
<div class="next">
<span>>span>
div>
<div class="num-box">
<ul class="num-ul">
<li data-index="0">1li>
<li data-index="1">2li>
<li data-index="2">3li>
<li data-index="3">4li>
<li data-index="4">5li>
ul>
div>
div>
css:
我们需要将图片列表排成一排,并且让最外层的盒子设置超出隐藏,其它两个部分可以定位到对应的位置
下面会通过Css和JS两种方式来完成效果
2. 防抖,节流
防抖:指定时间内 频繁触发一个事件,以最后一次触发为准
节流:指定时间内 频繁触发一个事件,只会触发一次
应用场景有很多比如:
防抖: input搜索,用户在不断输入内容的时候,用防抖来减少请求的次数并且节约请求资源
节流:场景普遍就是按钮点击,一秒点击 10下会发起 10 次请求,节流以后 1 秒点再多次,都只会触发一次
也可以用游戏例子来体现
防抖:类似回城,打断会重新开始
节流:类似技能CD,CD期间无法放技能
// 防抖
// fn 需要防抖的函数,delay 为定时器时间
function debounce(fn, delay) {
let timer = null // 用于保存定时器
return function () {
// 如果timer存在 就清除定时器,重新计时
if (timer) {
clearTimeout(timeout);
}
//设置定时器,规定时间后执行真实要执行的函数
timeout = setTimeout(() => {
fn.apply(this);
}, delay);
}
}
// 节流
function throttle(fn) {
let timer = null; // 首先设定一个变量,没有执行定时器时,默认为 null
return function () {
if (timer) return; // 当定时器没有执行的时候timer永远是false,后面无需执行
timer = setTimeout(() => {
fn.apply(this, arguments);
// 最后在setTimeout执行完毕后再把标记设置为true(关键)
// 表示可以执行下一次循环了。
timer = null;
}, 1000);
};
}