【机器视觉案例】(15) 虚拟答题板,手部关键点识别,附python完整代码
各位同学好,今天和大家分享一下如何使用 opencv+Mediapipe 制作虚拟问答,先放张图看效果。
当食指在某个答案框内部,并且食指指尖和中指指尖之间的距离小于预设值,那么就认为是点击该答案框,然后切换下一个问题,所有问题答完后给出得分。
答题时:

结算时:

1. 安装工具包
pip install opencv_python==4.2.0.34 # 安装opencv
pip install mediapipe # 安装mediapipe
# pip install mediapipe --user #有user报错的话试试这个
pip install cvzone # 安装cvzone
# 导入工具包
import cv2
import cvzone
import csv
from cvzone.HandTrackingModule import HandDetector # 导入手部跟踪模块21个手部关键点如下,这次我们主要研究食指指尖关键点 '8' 和 中指指尖 '12'

2. 文件准备,手部关键点识别
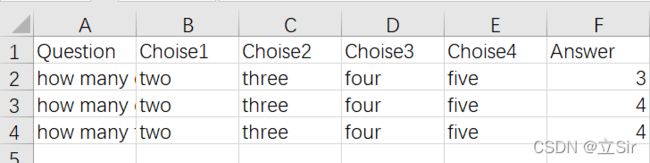
答题文件准备,将问题、选项、正确答案写在一个CSV文件中,该文件和程序文件放在同一个路径下。Answer的数字代表第几个选项是对的
(1) cvzone.HandTrackingModule.HandDetector() 是手部关键点检测方法
参数:
mode: 默认为 False,将输入图像视为视频流。它将尝试在第一个输入图像中检测手,并在成功检测后进一步定位手的坐标。在随后的图像中,一旦检测到所有 maxHands 手并定位了相应的手的坐标,它就会跟踪这些坐标,而不会调用另一个检测,直到它失去对任何一只手的跟踪。这减少了延迟,非常适合处理视频帧。如果设置为 True,则在每个输入图像上运行手部检测,用于处理一批静态的、可能不相关的图像。
maxHands: 最多检测几只手,默认为 2
detectionCon: 手部检测模型的最小置信值(0-1之间),超过阈值则检测成功。默认为 0.5
minTrackingCon: 坐标跟踪模型的最小置信值 (0-1之间),用于将手部坐标视为成功跟踪,不成功则在下一个输入图像上自动调用手部检测。将其设置为更高的值可以提高解决方案的稳健性,但代价是更高的延迟。如果 mode 为 True,则忽略这个参数,手部检测将在每个图像上运行。默认为 0.5
它的参数和返回值类似于官方函数 mediapipe.solutions.hands.Hands()
MULTI_HAND_LANDMARKS: 被检测/跟踪的手的集合,其中每只手被表示为21个手部地标的列表,每个地标由x, y, z组成。x和y分别由图像的宽度和高度归一化为[0,1]。Z表示地标深度。
MULTI_HANDEDNESS: 被检测/追踪的手是左手还是右手的集合。每只手由label(标签)和score(分数)组成。 label 是 'Left' 或 'Right' 值的字符串。 score 是预测左右手的估计概率。
(2)cvzone.HandTrackingModule.HandDetector.findHands() 找到手部关键点并绘图
参数:
img: 需要检测关键点的帧图像,格式为BGR
draw: 是否需要在原图像上绘制关键点及识别框
flipType: 图像是否需要翻转,当视频图像和我们自己不是镜像关系时,设为True就可以了
返回值:
hands: 检测到的手部信息,由0或1或2个字典组成的列表。如果检测到两只手就是由两个字典组成的列表。字典中包含:21个关键点坐标(x,y,z),检测框左上坐标及其宽高,检测框中心点坐标,检测出是哪一只手。
img: 返回绘制了关键点及连线后的图像
代码如下:
import cv2
import csv
from cvzone.HandTrackingModule import HandDetector # 导入手部跟踪模块
#(1)视频捕获
cap = cv2.VideoCapture(0) # 0代表捕获电脑摄像头
cap.set(3, 1280) # 图像的宽
cap.set(4, 720) # 图像的高
#(2)文件配置
detector = HandDetector(maxHands=1, detectionCon=0.8) # 最多检测一只手,检测置信度为0.8
# 读取cvs文件
csvpath = 'question.csv'
with open(csvpath, newline='\n') as f:
reader = csv.reader(f)
dataAll = list(reader)[1:] # 接收问题和答案部分,标题不要
print(dataAll)
quentionNum = 0 # 当前是第几个问题
questionTotal = len(dataAll) # 一共有几个问题
#(3)创建答题的类
class MCQ:
def __init__(self, data): # 初始化
# 将每个的问题列表中的元素分类出去
self.question = data[0] # 问题
self.choice1 = data[1] # 答案1
self.choice2 = data[2] # 答案2
self.choice3 = data[3] # 答案3
self.choice4 = data[4] # 答案4
self.answer = eval(data[5]) # 正确答案,是整数
# 我们选择了哪个答案
self.userAns = None
#(4)接收每个问题及其答案
mcqList = [] # 保存每个问题及内容
for q in dataAll: # 遍历所有问题和答案
mcqList.append(MCQ(q)) # 保存每个类实例
print(len(mcqList))
# 处理帧图像
while True:
# 是否读取成功success, 读取的帧图像img
success, img = cap.read() # 每次执行读取一帧
# 图像翻转,呈镜像关系
img = cv2.flip(img, 1)
# 手部关键点捕获,返回手部信息hands,绘制关键点后的图像img
hands, img = detector.findHands(img, flipType=False) # fliptype前面翻转了,这里就不用了
# 显示图像
cv2.imshow('img', img)
k = cv2.waitKey(1) # 每帧滞留1毫秒
if k & 0XFF==27: # ESC键退出程序
break
# 释放视频资源
cap.release()
cv2.destroyAllWindows()读入的问题及其答案如下:
[['how many corners does a rectangle have ?', 'two', 'three', 'four', 'five', '3'],
['how many oceans are in the world ?', 'two', 'three', 'four', 'five', '4'],
['how many fingers do you have ?', 'two', 'three', 'four', 'five', '4']]手部关键点检测图如下:
3. 选择答案框,关键点处理
mcqList 存放三个问题及其答案的类,mcq 接收每个问题的类实例化对象,使用 cvzone.putTextRect() 绘制每个问题及其答案的矩形框,返回矩形框的左上角坐标 (x1, y1) 和右下角坐标 (x2, y2),保存在bbox中。然后只需要判断 食指指尖坐标 在哪一个矩形框中即可。detector.findDistance() 计算食指指尖坐标 lmList[8][0:2],和中指指尖坐标 lmList[12][0:2] 之间的距离。如果指尖之间的距离小于50,并且食指在某个矩形框选项内部,就认为是点击该选项。点击后 questionNum + 1,切换下一个问题
为了避免按下一次就经过了很多帧的情况,设置延时计数器 delayCounter,每30帧可以有效点击一次选项,点击之后 延时器 delay = False, 代表下一帧点击选项无效。
在上面的代码中补充:
import cv2
import cvzone
import csv
from cvzone.HandTrackingModule import HandDetector # 导入手部跟踪模块
#(1)视频捕获
cap = cv2.VideoCapture(0) # 0代表捕获电脑摄像头
cap.set(3, 1280) # 图像的宽
cap.set(4, 720) # 图像的高
#(2)文件配置
detector = HandDetector(maxHands=1, detectionCon=0.8) # 最多检测一只手,检测置信度为0.8
# 读取cvs文件
csvpath = 'question.csv'
with open(csvpath, newline='\n') as f:
reader = csv.reader(f)
dataAll = list(reader)[1:] # 接收问题和答案部分,标题不要
print(dataAll)
questionNum = 0 # 当前是第几个问题
questionTotal = len(dataAll) # 一共有几个问题
#(3)创建答题的类
class MCQ:
def __init__(self, data): # 初始化
# 将每个的问题列表中的元素分类出去
self.question = data[0] # 问题
self.choice1 = data[1] # 答案1
self.choice2 = data[2] # 答案2
self.choice3 = data[3] # 答案3
self.choice4 = data[4] # 答案4
self.answer = eval(data[5]) # 正确答案,是整数
# 我们选择了哪个答案
self.userAns = None
# 判断食指指尖是否在答案框中
def update(self, cursor, bboxs, img):
# 遍历四个答案框, x记录检测框的索引
for x, box in enumerate(bboxs):
# 获取答案框的左上坐标和右下坐标
x1, y1, x2, y2 = box
# 判断食指指尖是否在某个答案框中
if x1 < cursor[0] < x2 and y1 < cursor[1] < y2:
# 如果在某个框中就记下用户选择了第几个答案
self.userAns = x+1 # 索引0代表第一个答案
# 让这个答案边框变成红色
cv2.rectangle(img, (x1,y1), (x2,y2), (0,0,255), 10)
#(4)接收每个问题及其答案
mcqList = [] # 保存每个问题及内容
for q in dataAll: # 遍历所有问题和答案
mcqList.append(MCQ(q)) # 保存每个类实例
print(len(mcqList))
#(5)设置延时器
delay = True # 下一帧可以选答案
delayCounter = 0 # 延时计数
#(5)处理帧图像
while True:
# 是否读取成功success, 读取的帧图像img
success, img = cap.read() # 每次执行读取一帧
# 图像翻转,呈镜像关系
img = cv2.flip(img, 1)
# 手部关键点捕获,返回手部信息hands,绘制关键点后的图像img
hands, img = detector.findHands(img, flipType=False) # fliptype前面翻转了,这里就不用了
# 获取每个问题的类实例
if questionNum < questionTotal:
mcq = mcqList[questionNum] # 获取当前问题对应的类实例
# 创建矩形文本框放置问题及其答案, 返回绘制后的图像img, 矩形文本框的左上和右下角坐标
# 问题
img, bbox = cvzone.putTextRect(img, mcq.question, [100,100], 3, 4, colorR=(255,255,0), colorT=(0,0,255),
offset=25, border=3, colorB=(0,255,255)) # 边框距字体20,边框颜色和厚度设置
# 答案
img, bbox1 = cvzone.putTextRect(img, mcq.choice1, [100,300], 3, 4, colorR=(255,255,255), colorT=(255,0,0),
offset=30, border=3, colorB=(0,255,0))
img, bbox2 = cvzone.putTextRect(img, mcq.choice2, [400,300], 3, 4, colorR=(255,255,255), colorT=(255,0,0),
offset=30, border=3, colorB=(0,255,0))
img, bbox3 = cvzone.putTextRect(img, mcq.choice3, [100,500], 3, 4, colorR=(255,255,255), colorT=(255,0,0),
offset=30, border=3, colorB=(0,255,0))
img, bbox4 = cvzone.putTextRect(img, mcq.choice4, [400,500], 3, 4, colorR=(255,255,255), colorT=(255,0,0),
offset=30, border=3, colorB=(0,255,0))
#(6)是否点击了答案
if hands: # 是否检测到了手
lmList = hands[0]['lmList'] # 获取一只手的21个关键点坐标
# 获取食指指尖xy坐标
cursor = lmList[8][0:2]
# 计算食指指尖和中指指尖之间的距离
# 返回长度、绘制后的图像、连线的坐标
length, info, img = detector.findDistance(lmList[8][0:2], lmList[12][0:2], img)
# 如果指尖距离小于50就认为是点击
if length < 50 and delay is True:
# 食指指尖是否在某个答案框中
mcq.update(cursor, [bbox1, bbox2, bbox3, bbox4], img)
print(mcq.userAns) # 打印选择了第几个答案
#(7)如果回答了那就换下一个问题
if mcq.userAns is not None:
delay = False # 启动延时器防止连续点击
questionNum += 1 # 记录当前是第几个问题
#(8)延时器
if delay is False:
delayCounter += 1 # 延时器加一
# 30帧之后才能重新点击一次
if delayCounter > 30:
delay = True # 下一针可以可以选择答案
delayCounter = 0 # 重置延时计数器
# 显示图像
cv2.imshow('img', img)
k = cv2.waitKey(1) # 每帧滞留1毫秒
if k & 0XFF==27: # ESC键退出程序
break
# 释放视频资源
cap.release()
cv2.destroyAllWindows()效果图如下:
4. 校对答案,优化界面
等所有问题答完之后,每个问题类的 self.userAns 属性中,保存了我对每个问题选择的答案,是整数不是索引,代表选择了第几个选项。和标准答案 self.answer 比较。如果选择的答案和标准答案相同,那么得分加一。遍历所有的问题的答案,得到最终得分,在图像上绘制出来。
在上面的代码中修改:
import cv2
import cvzone
import csv
from cvzone.HandTrackingModule import HandDetector # 导入手部跟踪模块
#(1)视频捕获
cap = cv2.VideoCapture(0) # 0代表捕获电脑摄像头
cap.set(3, 1280) # 图像的宽
cap.set(4, 720) # 图像的高
#(2)文件配置
detector = HandDetector(maxHands=1, detectionCon=0.8) # 最多检测一只手,检测置信度为0.8
# 读取cvs文件
csvpath = 'question.csv'
with open(csvpath, newline='\n') as f:
reader = csv.reader(f)
dataAll = list(reader)[1:] # 接收问题和答案部分,标题不要
print(dataAll)
questionNum = 0 # 当前是第几个问题
questionTotal = len(dataAll) # 一共有几个问题
#(3)创建答题的类
class MCQ:
def __init__(self, data): # 初始化
# 将每个的问题列表中的元素分类出去
self.question = data[0] # 问题
self.choice1 = data[1] # 答案1
self.choice2 = data[2] # 答案2
self.choice3 = data[3] # 答案3
self.choice4 = data[4] # 答案4
self.answer = eval(data[5]) # 正确答案,是整数
# 我们选择了哪个答案
self.userAns = None
# 判断食指指尖是否在答案框中
def update(self, cursor, bboxs, img):
# 遍历四个答案框, x记录检测框的索引
for x, box in enumerate(bboxs):
# 获取答案框的左上坐标和右下坐标
x1, y1, x2, y2 = box
# 判断食指指尖是否在某个答案框中
if x1 < cursor[0] < x2 and y1 < cursor[1] < y2:
# 如果在某个框中就记下用户选择了第几个答案
self.userAns = x+1 # 索引0代表第一个答案
# 让这个答案边框变成红色
cv2.rectangle(img, (x1,y1), (x2,y2), (0,0,255), 10)
#(4)接收每个问题及其答案
mcqList = [] # 保存每个问题及内容
for q in dataAll: # 遍历所有问题和答案
mcqList.append(MCQ(q)) # 保存每个类实例
print(len(mcqList))
#(5)设置延时器
delay = True # 下一帧可以选答案
delayCounter = 0 # 延时计数
#(6)处理帧图像
while True:
# 是否读取成功success, 读取的帧图像img
success, img = cap.read() # 每次执行读取一帧
# 图像翻转,呈镜像关系
img = cv2.flip(img, 1)
# 手部关键点捕获,返回手部信息hands,绘制关键点后的图像img
hands, img = detector.findHands(img, flipType=False) # fliptype前面翻转了,这里就不用了
# 获取每个问题的类实例
if questionNum < questionTotal:
mcq = mcqList[questionNum] # 获取当前问题对应的类实例
# 创建矩形文本框放置问题及其答案, 返回绘制后的图像img, 矩形文本框的左上和右下角坐标
# 问题
img, bbox = cvzone.putTextRect(img, mcq.question, [100,100], 3, 4, colorR=(255,255,0), colorT=(0,0,255),
offset=25, border=3, colorB=(0,255,255)) # 边框距字体20,边框颜色和厚度设置
# 答案
img, bbox1 = cvzone.putTextRect(img, mcq.choice1, [100,300], 3, 4, colorR=(255,255,255), colorT=(255,0,0),
offset=30, border=3, colorB=(0,255,0))
img, bbox2 = cvzone.putTextRect(img, mcq.choice2, [400,300], 3, 4, colorR=(255,255,255), colorT=(255,0,0),
offset=30, border=3, colorB=(0,255,0))
img, bbox3 = cvzone.putTextRect(img, mcq.choice3, [100,500], 3, 4, colorR=(255,255,255), colorT=(255,0,0),
offset=30, border=3, colorB=(0,255,0))
img, bbox4 = cvzone.putTextRect(img, mcq.choice4, [400,500], 3, 4, colorR=(255,255,255), colorT=(255,0,0),
offset=30, border=3, colorB=(0,255,0))
#(7)是否点击了答案
if hands: # 是否检测到了手
lmList = hands[0]['lmList'] # 获取一只手的21个关键点坐标
# 获取食指指尖xy坐标
cursor = lmList[8][0:2]
# 计算食指指尖和中指指尖之间的距离
# 返回长度、绘制后的图像、连线的坐标
length, info, img = detector.findDistance(lmList[8][0:2], lmList[12][0:2], img)
# 如果指尖距离小于50就认为是点击
if length < 50 and delay is True:
# 食指指尖是否在某个答案框中
mcq.update(cursor, [bbox1, bbox2, bbox3, bbox4], img)
print(mcq.userAns) # 打印选择了第几个答案
#(8)如果回答了那就换下一个问题
if mcq.userAns is not None:
delay = False # 启动延时器防止连续点击
questionNum += 1 # 记录当前是第几个问题
#(9)增加一个进度条记录当前是第几个问题
barval = 150 + (1100-150)//questionTotal * questionNum
# 绘制矩形框
cv2.rectangle(img, (150,600), (barval,650), (0,255,0), cv2.FILLED)
cv2.rectangle(img, (150,600), (1100,650), (0,0,255), 3)
# 显示完成了多少
cv2.putText(img, f'{int(questionNum / questionTotal * 100)}%', (1130, 640), 1, cv2.FONT_HERSHEY_COMPLEX, (0,255,0), 3)
#(10)答完所有问题后计算答对了几题
else:
score = 0 # 初始化得分
for mcq in mcqList:
# 查看标准答案和回答的答案是否相同
if mcq.answer == mcq.userAns:
# 如果相同得分加一
score += 1
# 答对了多少
score = int((score / questionTotal)*100)
# 显示游戏结束
img, _ = cvzone.putTextRect(img, 'Game Over', [450,300], 4, 4, colorR=(255,255,255), colorT=(0,0,255),
offset=30, border=3, colorB=(255,0,255))
# 绘制在最后的图像上
img, _ = cvzone.putTextRect(img, 'Your Score: '+str(score)+'%', [400,500], 4, 4, colorR=(255,255,0), colorT=(255,0,255),
offset=30, border=3, colorB=(0,0,255))
#(11)延时器
if delay is False:
delayCounter += 1 # 延时器加一
# 30帧之后才能重新点击一次
if delayCounter > 30:
delay = True # 下一帧可以可以选择答案
delayCounter = 0 # 重置延时计数器
#(12)显示图像
cv2.imshow('img', img)
k = cv2.waitKey(1) # 每帧滞留1毫秒
if k & 0XFF==27: # ESC键退出程序
break
# 释放视频资源
cap.release()
cv2.destroyAllWindows()效果图如下: