十分钟理解Faster-RCNN系列算法及相关算法详细原理
说明:本文为总结性文章,适合有一定基础的童孩们阅读哦~文章来源于个人学习笔记,仅做学习交流!
一、二阶段算法RCNN、Fast-RCNN、Faster-RCNN比较

1.R-CNN
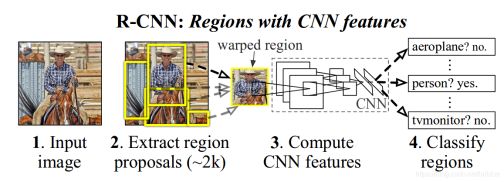

实现过程
(1)region proposal。用区域合并算法SS(Selective Search for Object Recognition解读https://blog.csdn.net/mao_kun/article/details/50576003 )在同一张图片上产生候选框。
(2)feature extraction。分别将图片上的每个候选框送入卷积神经网络CNN(由conv+relu+pool层组成的VGG、Inception、Resnet等),获得的结果叫做特征图;(CNN卷积神经网络原理讲解+图片识别应用(附源码)
https://blog.csdn.net/kun1280437633/article/details/80817129 )
(3)classification。针对每个类别训练一个SVM的二分类器。输入特征,输出为是否属于该类别,训练结果是得到SVM的权重矩阵W。
(4)rect refine。用提取的特征和bounding box的ground truth(预先标定的真实框)来训练回归,每种类型的回归器单独训练。
算法结果
在pascal VOC 2012数据集上:mAP 53.3%、平均每张图片耗时47s,共计训练耗时84小时。
主要缺点
步骤太多;在训练卷积神经网络的过程中对每个region proposal都要计算卷积,因此基于region proposal卷积的计算量太大,而这也正是之后Fast R-CNN主要解决的问题。只有feature extraction在GPU上运行、其他三个步骤都只能在CPU上完成。
2.Fast-RCNN


算法结果
基于VGG16的Fast RCNN算法在训练速度上比RCNN快了将近9倍,比SPPnet快大概3倍;测试速度比RCNN快了213倍,比SPPnet快了10倍。在VOC2012上的mAP在66%左右。
对整张图像卷积而不是对每个region proposal卷积,ROI Pooling,分类和回归都放在网络一起训练的multi-task loss是算法的三个核心。另外还有SVD分解等是加速的小贡献,数据集的增加时mAP提高的小贡献。
主要缺点
Fast RCNN的主要缺点在于region proposal的提取使用selective search,目标检测时间大多消耗在这上面(提region proposal 2~3s,而提特征分类只需0.32s),这也是后续Faster RCNN的改进方向之一。
3. Faster RCNN

Faster-rcnn中的核心优势
1)提出了“RPN”网络,在提高精度的同时提高了速度;
2)RPN网络和Fast-rcnn网络的特征共享与训练;
3)使用了ROI Pooling技术 ;
4)使用了NMS技术;
“RPN”网络详解
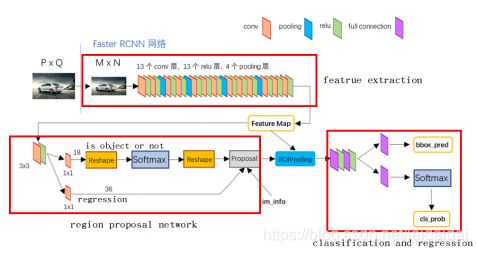
核心贡献是在已经提取出的特征图上产生候选区域(anchor),(之前都是在原始图像上产生候选框)。这些候选区域在特征图上是一个点,每个点映射原始图像中的某个区域(通过以该点为中心不同比例和大小产生候选框)。
通过剔除边界、NMS(多个重叠较大的框存在时只保留与正例重合度最高的框)、得分最高M个IOU值等方法,在众多anchors中提取256个,分别对这些框进行分类(只判断该区域是不是一个物体,无需知道是什么物体)和回归(得到候选框中心坐标和长宽(x,y,w,h)与真实已标注的框之间的差异)。将得到的结果送入ROI Pooling层进行标准化,为进一步分类和位置精修做准备。
候选区域(anchor)
特征可以看做一个尺度5139的256通道图像,对于该图像的每一个位置,考虑三种面积{128^2 , 256^2, 512^2}*三种比例{1:1,1:2,2:1}这9个可能的候选窗口,下图示出5139个anchor中心,以及9种anchor示例(每个中心点9个框,这里只是示例)。

具体可参考(《一文读懂Faster RCNN》https://zhuanlan.zhihu.com/p/31426458 )
二、与一阶段算法YOLO、SSD的比较
总结
三大目标检测方法中,Faster R-CNN对小目标的检测效果还是最好,SSD检测的速度是最快的,尤其是SSD mobilenet,YOLO v3吸取了前两者的一些优点,比Faster R-CNN快、比SSD检测小目标准,效果中规中矩。具体指标可以参考如下图。

1.YOLO

算法实现步骤
(1) 给个一个输入图像,首先将图像划分成77的网格
(2) 对于每个网格,我们都预测2个边框(包括每个边框是目标的置信度以及每个边框区域在多个类别上的概率)
(3) 根据上一步可以预测出7x7x2个目标窗口,然后根据阈值去除可能性比较低的目标窗口,最后NMS去除冗余窗口即可。
小结:YOLO将目标检测任务转换成一个回归问题,大大加快了检测的速度,使得YOLO可以每秒处理45张图像。而且由于每个网络预测目标窗口时使用的是全图信息,使得false positive比例大幅降低(充分的上下文信息)。
但是YOLO也存在问题:没有了Region Proposal机制,只使用77的网格回归会使得目标不能非常精准的定位,这也导致了YOLO的检测精度并不是很高。
YOLO和Fast-R-CNN相比:
(1)YOLO的背景判断错误率不到Fast-R-CNN的一半。虽然相较于其他的state-of-the-art 物体检测系统,YOLO在物体定位时更容易出错,但是在背景上预测出不存在的物体(false positives)的情况会少一些。
(2)能够学到更加抽象的物体的特征,这使得YOLO可以从真实图像领域迁移到其他领域,如艺术。
(3)YOLO对小物体的检测效果不好(尤其是密集的小物体,因为一个栅格只能预测2个物体)。由于损失函数的问题,定位误差是影响检测效果的主要原因,尤其是大小物体的处理上,还有待加强。
(4)召回率低。
2.SSD(SSD: Single Shot MultiBox Detector)
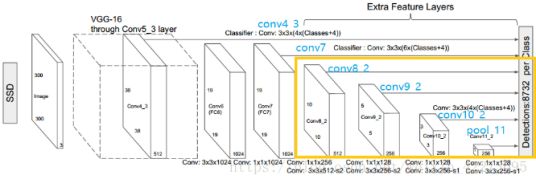

上图是SSD的一个框架图,首先SSD获取目标位置和类别的方法跟YOLO一样,都是使用回归,但是YOLO预测某个位置使用的是全图的特征,SSD预测某个位置使用的是这个位置周围的特征(感觉更合理一些)。
使用Faster R-CNN的anchor机制建立某个位置和其特征的对应关系。如SSD的框架图所示,假如某一层特征图(图b)大小是88,那么就使用33的滑窗提取每个位置的特征,然后这个特征回归得到目标的坐标信息和类别信息(图c)。SSD训练图像中的 ground truth 需要赋予到那些固定输出的 boxes 上,SSD输出的是事先定义好的,一系列固定大小的 bounding boxes。
小结:SSD结合了YOLO中的回归思想和Faster R-CNN中的anchor机制,使用全图各个位置的多尺度区域特征进行回归,既保持了YOLO速度快的特性,也保证了窗口预测的跟Faster R-CNN一样比较精准。SSD在VOC2007上mAP可以达到72.1%,速度在GPU上达到58帧每秒。
SSD和Fast-R-CNN相比:
(1)SSD对小物体目标较为敏感,在检测小物体目标上表现较差,但比YOLO要好。
(2)SSD 对大目标检测效果非常好。
(3)SSD 对于不同aspect ratios的物体检测效果也很好。因为SSD使用了不同aspect ratios的default boxes,使用更多的 default boxes,结果也越好。
(4)使用atrous版本VGG-16作为预训模型比较普通VGG-16要提高0.7%mAP。
主要参考博文
《详述目标检测最常用的三个模型:Faster R-CNN、SSD和YOLO》:
https://blog.csdn.net/weixin_42273095/article/details/81699352
《一文读懂目标检测:R-CNN、Fast R-CNN、Faster R-CNN、YOLO、SSD》
https://blog.csdn.net/v_JULY_v/article/details/80170182