第四范式OpenMLDB在金融风控数据库的计算优化实践
近日,在DataFunSummit:智能金融在线峰会上,第四范式平台架构师陈迪豪以《OpenMLDB风控数据库计算优化》为主题,重点介绍了第四范式开源机器学习数据库OpenMLDB在金融领域的应用,以及底层时序特征的处理、窗口的计算优化细节等,让用户可以理解风控数据库的技术架构,了解底层基于窗口的计算性能优化点,以及性能优化的实现细节。
一.风控场景特征设计
基于机器学习的智能风控数据库,逐渐取代了人工审核和专家规则,成为准确性更高、更可靠的风控系统,后面会介绍一下风控场景下智能风控平台的设计以及它的特征设计。
首先是风控系统的演化,大家已经了解了,从最早的人工审核,取得了一定的效果,但成本较高,效率较低。进入21世纪,行业内开始利用计算机自动化能力与专家规则相结合的方式,解决效率低、自动化较差的问题,但是它同时出现容易误杀,用户体验较差,无法用于事中拦截,准确率低的问题。近几年,各大金融机构和互联网金融企业的风控系统开始采用基于机器学习的方式来实现。
首先应用从海量的数据中训练得到机器学习模型,比如说传统的LR模型,还有更复杂的DNN都可以实现更高准确率,还可以根据不同的应用场景,实现千人千面的模型预测。机器学习的特点就是隐蔽性更强,准确性更高,迭代速度更快,也逐渐成为智能风控系统必不可少的技术支撑。
从效果来看,在某国有银行的线上非本人交易欺诈防控场景中,OpenMLDB上线以后在召回率0.5左右的情况下,预测准确率提升了316%;在事中交易欺诈检测场景中,相比使用专家规则的事中反欺诈检测,误报率在召回54%左右的时候,整体误报率下降了33%。
智能风控系统是结合过去的一些专家规则和最新的机器学习模型来实现的一个平台。蓝色部分是银行内部已有的业务系统,有黑白名单,有一些外部数据如时序数据等都可以通过数仓导到我们决策平台,它不会全部依赖模型,而是结合专家规则,由规则引擎和模型预估服务来共同协作,做出最终的决策。
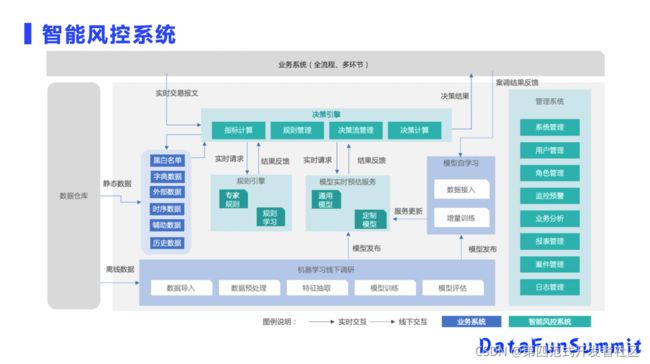
模型部分是传统的机器学习流程,比如说离线数据部分,实现数据导入和数据预处理、特征抽取、模型训练以及后续的模型上线以及模型自学习、模型更新等等功能。
这是一套完整的智能风控系统,我们今天介绍的是OpenMLDB在这套系统里最底层的离线数据管理以及在线的特征查询服务。
风控场景下复杂的特征工程
我们看一下风控场景它的特征有哪些特点,首先是用户的交易信息以及用户的属性是非常重要的。时序特征在风控场景里面也是特别重要的,用户在不同的窗口,前一天、前七天、前一个月、前三个月,这些窗口都包含了很重要的信息特征,我们对于不同的数据,因为它的交易次数,交易的金额在不同的历史窗口里面,也是需要计算出不同的特征过来。
还有就是交易的金额最大值和最小值,交易的地点信息等,都包含一些连续行为特征。所以,我们在构建一个风控场景下的机器学习模型时,特征设计是比较复杂的,需要考虑特征时序相关的计算,最大的难点在于这些特征由科学家设计出来以后,需要在在线系统重新实现。
离线的实现传统做法是用OLAP或者MPP系统,Spark、Flink等本身就支持SQL标准的滑动窗口。但在线是很难实现的,每一个离线的特征都需要翻译到在线。如果我们的建模方案修改了或者新增一些特征,在线也需要做新增特征的开发。新增在线特征开发与离线基于MPP系统是两套计算逻辑和执行引擎,表达优化也不一样,需要大量的人工做离线在线的特征一致性校验。
OpenMLDB为特征计算提供更优的支撑
OpenMLDB可以解决这个问题,它针对AI场景做了特征优化,既实现了离线存储特征计算的优化,还实现了在线业务在毫秒级别的实时查询。
首先,OpenMLDB是针对AI场景的特征计算引擎,可以面向机器学习应用提供正确高效的数据供给,无论是离线数据还是在线数据,底层都有一致性同步的,这个与前面提到的HTAP有点类似。但是我们的在线数据是一个高性能的内存时序存取接口,可以毫秒级别实现时序数据供给。要实现在线离线特征计算一致性和存储一致性,这是由统一的执行引擎来实现,由统一的基于(LLVM JIT)实现的SQL优化器,离线和在线使用相同的执行引擎,才能把离线在线的特征算出来,而不需要人工校验翻译,同时也支持了机器学习场景的特殊批表操作,以及特殊的特征抽取函数等。
其次,OpenMLDB也是高性能的OLTP和MPP执行引擎,支持高性能在线时序数据的读写和恢复。它的读写性能非常高,而且是针对时序数据做优化,这是目前业界无论是OLTP还是TSDB这些时序数据库都不能达到毫秒级别的性能。在硬件的优化与支持上,OpenMLDB可在Memory和PMEM存储介质上使用,PMEM是英特尔提供的全新存储介质,它的成本会比内存更低,而且是一种可持久化的全新存储介质,我们针对PMEM也做了优化,数据恢复速度是它原来的十倍以上。此外,OpenMLDB离线批处理性能比业界主流MPP系统提升6倍以上。大家都知道像Spark、Presto等分布式系统,本身的性能优化是非常好的,有很好的执行引擎,但是它没有针对AI场景做特殊优化。下图是我们实际场景验证的性能图,纵坐标是运行时间,OpenMLDB比我们测试的最新版Spark性能提升十倍以上。

二.并行计算优化
OpenMLDB是如何为这些风控特征做计算优化的呢?首先从并行计算优化开始介绍。大家使用OpenMLDB进行大规模特征抽取的时候,相比业界主流的MPP系统有数倍的性能提升,得益于底层计算优化实现。
在大规模数据处理系统里,在2000年开始出现了Hadoop,2010年以后开始流行Spark、Presto、Flink等,可以使用内存做Shuffle避免落盘,其计算性能相比Hadoop又数倍甚至数十倍性能提升。如今,第四范式OpenMLDB在一些大规模数据处理上,会比Spark和Presto性能提升更多,以下会详细介绍底层的优化细节。
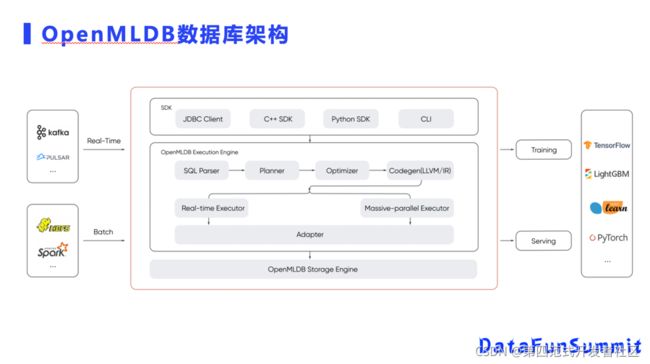
OpenMLDB的左边是一些外围系统,支持数据引入,它的外层用户有JDBC或者Pytho SDK等编程接口,底层是自研实现的SQL Parser,也包含自定义的一些Optimizer,后端实现了基于LLVM的执行引擎,它可以针对不同的硬件做优化,比如说X86、ARM架构等,以后也可以基于LLVM PTX后端实现GPU硬件加速。
底层包括两个执行引擎,一个是Realtime executor,这个是跟传统的OLTP系统一样,可以提供超高性能的时序特征读写功能。第二部分是Massive parallel executor,和传统的MPP系统类似,支持OLAP的大数据处理场景。底层是统一的存储引擎,使用OpenMLDB来做特征抽取,还支持导出开源的机器学习数据格式,比如说Tensorflow、LightGBM都可以直接使用OpenMLDB的数据做模型训练。因为离线在线一致性等特性,每个特征不需要在线做额外的翻译开发,可以直接上线了。
多窗口并行优化
为什么OpenMLDB的批处理模式比最新的Spark 3.1还能快数倍?第一个优化点是多窗口并行优化。
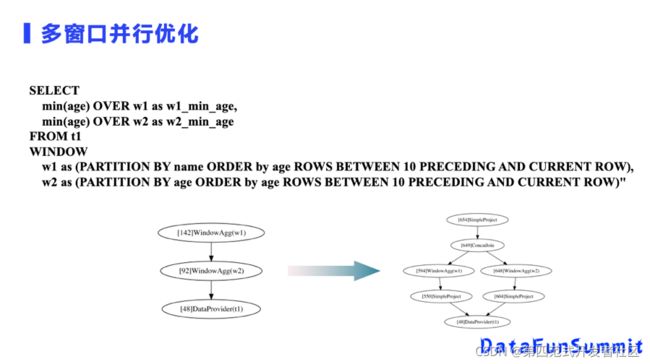
上面是一个简单的SELECT语句,根据W1、W2做窗口聚合计算,这两个窗口定义是不一样,如果一样的话,生成的逻辑计划就会做合并优化。但是因为它的Partition key不一样,这个SELECT翻译出来的逻辑计划就是和左边一样的。首先数据是从T1表过来的,上面有两个Window的串行计算,几乎所有开源分布式数据处理框架都是这样实现的。这种实现的难度较低,遇到多个窗口也是串行计算,把W2的结果和T1需要的列筛选出来再做W1就可以了。
然而,在这里会出现资源浪费的情况,因此还有很大的优化空间。这两个窗口计算本身不一定会用满所有的计算资源,理论上应该可以并行计算来实现更高的性能,如果有一个窗口有数据倾斜的问题,即时第二个窗口很快就可以完成,它也必须等第一个窗口做完才可以开始。所以,它的整体计算时间是直接累加的,W1需要多少时间,W2需要多少时间,加起来就是它的总运行时间。

OpenMLDB多窗口并行优化的实现,会把串行的结构做成并行化,DataProvider节点左边和右边分别是两个WindowAgg节点,这两个节点没有相互依赖,运行时只要资源足够可以并行计算。当然即时实现了并行计算,优化后它的结果与串行执行结果也是一致的。
这种并行是怎么实现的呢?前面用户经过我们的SQL parser编译,可以得到一个优化后的逻辑计划。最底层是一个DataProvider节点,优化后是一个并行的结构。我们执行的时候先把需要的数据取出来,然后再做第二个WindowAgg,它们之间并没有互相依赖,数据也不需要读两份,而是都依赖于DATA PROVIDER节点。为了实现并行窗口数据的合并,需要再加一个JOIN节点。前面的简单列筛选节点,本身没有性能消耗,只是在逻辑计划里表示我计算时需要输入哪些列,在实际计算的时候,它不需要对整行数据进行编解码和传输。
数据过来以后我们把两个节点数据做并行计算,计算后通过拼表操作拼接出来,最后再PROJECT需要的列,除了做Window我们虽然还增加了拼表操作,但优化了多个Window的执行。如果有连续的Window,我们就可以把它都做成连续的并行优化。
虽然实现逻辑看起来比较简单,只是把串行结构并行化,但现在大家都没有这样实现,主要原因是这种优化的实现细节还是比较复杂的。我们知道像第一个窗口,在做W1窗口聚合的时候,首先需要对于窗口的name、age这些列保留出来,有这两列才能做分区排序,还有age需要做聚合。
W1和W2的要求是不一样的,每个窗口计算出来只保留age列是不够的,实际上是这种串行的执行,T1做完了W2窗口的时候,并不是只保留W2算出来的列,还保留W1列,甚至所有的需要列,输出W2以后才可以做W1。做并行的时候,每个窗口只需要输出它自己的列就可以了,但是窗口的分区键是不一样,分布式数据里面每个分区内的数据也不一样,不能直接按照相同顺序做简单拼接,因此实现上我们有一些新增列的操作,对所有数据都会给它分配一个索引列。
代码实现就需要八步,每一步都相对复杂。这里简单介绍一下,大家可以从OpenMLDB开源的代码里面可以看到具体的实现(OpenMLDB开源地址:https://github.com/4paradigm/OpenMLDB)。
首先是拿到一个逻辑计划,我们就要给它做分析,我们要知道哪些Window节点是需要并行优化的,而且并行优化的节点列数不一样,这个节点在处理的时候,实现的方法和普通Window也是不一样的。
-
遍历LastJoin1节点,找到所有ConcatJoin节点, 这里只有ConcatJoin3节点,存到一个List中。
-
以ConcatJoin3节点开始,进行先序遍历,这时开始打标志,创建一个唯一的index column name,设置到标志的Map中。
-
遍历ConcatJoin3的子节点,每一个节点都设置标志的Map,其中key为node id,value就是前面生成的index column name。
-
在遍历子节点的过程中,还需要检查找到ConcatJoin3的下一个公共子节点,也就是这里的SimpleProject6,并且设置到标志Map中。
-
在实际运行节点时,通过后序遍历逻辑计划来执行,对于SimpleProject6节点,在运行左边的逻辑时需要提前根据标志Map来添加一个index column,这时结果不能缓存,因为在计算右边时不能返回添加index column的DataFrame。
-
中间节点如WindowProject4和WindowProject5,根据标志Map的信息了解到已经添加了index column,在做窗口计算和编解码时需要去掉index column。
-
在ConcatJoin3节点计算时,则可以使用last join或者left join实现,并且需要根据标志Map把index column列给去掉。
-
其他节点,如LastJoin1、SimpleProject2、DataProvider7和SimpleProject8,都按旧逻辑正常运行。
需要注意的是,第六步是所有带索引列的输出。如果还有其他节点,需要的是没有索引列的输出,这个节点会有两个输出。WindowProject4和WindowProject5这两个节点已经打了标签,知道自己是什么节点,在计算的时候需要去掉索引列。因为在这个节点,本身没有被优化之前,它的计算是输入多少列就处理多少列,但是在被并行优化以后,它在执行C函数的时候需要先去掉索引列,但是输出的时候又要把索引列加进去。
在上面的SQL例子,W1和W2只做一个特征的计算,他们只输出各自的结果列和一个索引列。拿到这两个输出表后我们要做一个拼表操作,因为他们都有一个唯一的索引ID,即时做完窗口计算后索引也是不变的。我们基于前面的索引列,做一个拼表,用last join或者left join实现即可,这两个节点不受优化影响,执行逻辑和以前一样,无论是输入还是输出,最终的表和之前的未优化是一样的。
我们看一下多窗口并行优化的效果。首先从逻辑上就可以看到,如果你有两个窗口,计算资源足够的话,两个窗口并行计算,它的计算耗时应该是可以减少运行时间较短的那个窗口的,在并行优化以后短的窗口耗时就被忽略了。类似木桶效益,整个用户的耗时瓶颈是在最长的窗口里面。再加上做LLVM的窗口计算逻辑优化,我们最终优化后的时间就可以降到很低了。
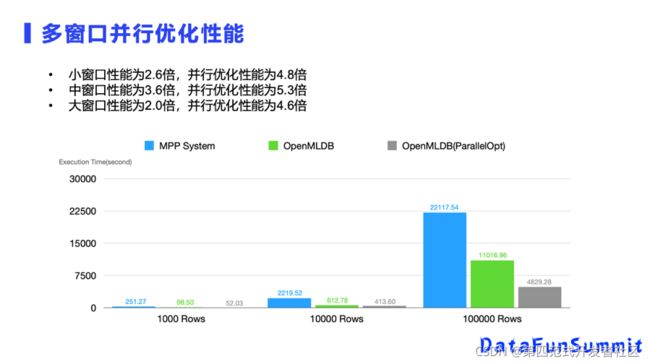
并行优化性能如图所示,这里罗列了三个性能测试场景,和最新的MPP System进行对比,基于窗口并行优化后的OpenMLDB与开源MPP系统性能可以是原来的5.3倍,相比OpenMLDB本身性能也在2倍左右。
三.窗口倾斜优化
OpenMLDB在窗口数据倾斜上也有大量优化实现。首先介绍一下数据倾斜和窗口数据倾斜的基础,数据倾斜是大数据处理场景下常见的一个现象,某一个分区或某一个key的数据量非常大,和其他的分区数据量不成比例。例如用户在统计这种游戏用户信息的时候,针对游戏用户的男女做一个分区处理,很可能就出现倾斜的情况,比如说男性用户会比较多,而这个数据因为是按照性别来分区的,性别的类型也不会有很多,分区数就会很少。也就导致我们做分区聚合的时候,并发度也会非常少。
数据倾斜会导致数据分区和其他分区的运算结果产生较大差距,换句话说就是倾斜数据分区的计算任务与其cpu资源严重不匹配。最终会造成多等一的情况——多个小数据量的分区计算完毕后等待倾斜的大数据量分区,只有倾斜分区计算完毕才能输出结果。这对效率来说是巨大的灾难。比如说64核,每个分区单一处理,每个任务是20个核,时间就比较长。多个小数据分区完毕后需要等待大数据区分,只有倾斜分区计算完毕才能输出结果,性能是有限的。
数据倾斜有几个方案。比如说每个分区做一个(reduce),分区之间没有关系,我给数据分成128个分区,这样就可以把所有的CPU资源用满了,每个分区用完了以后做聚合就可以得到结果。
在机器学习的特征计算中,窗口计算下出现数据倾斜,某个分区数据过多,产生倾斜问题的时候,是不可以使用我们刚才说的传统的数据倾斜优化方案的。我们通过数据加一个前缀,前缀可以分出更多的分区,为什么不可以这样做呢?因为窗口的计算是依赖于前后数据的,是基于某一个数据的前后数据做聚合。如果我们把数据强行分成男性用户十个分区,第一个分区计算有可能是对的,但是第二个分区依赖于上一个分区的数据,所以在传统的实现上,无论是SparkSQL、FlinkSQL等等都没有对这个数据做优化。
OpenMLDB提出了一个基于Spark的窗口数据倾斜优化方案,对数据做一个扩充,如果不扩充直接分区的话,会导致不同数据计算的窗口不准,结果也不一致。我们在做完了数据扩充以后,再根据新的分区键及时间片做新的分区,并行度就会更高。
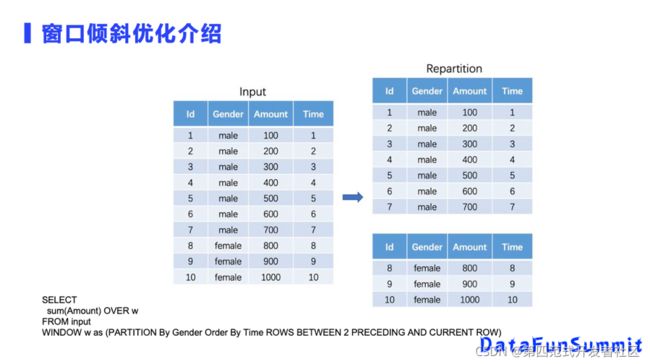
这是一个窗口倾斜的典型场景,在我们的训练数据里面,数据只有两个性别,男和女。在这个场景下,我们对男和女做一个Window特征的话,分区键只有两个值,实际上只有两个分区。也就是说这一个SQL场景,我们基于分区键来做聚合,实现上只会有两个分区,无论你的Hadoop集群有一百还是一千CPU,Spark任务只能分成两个Task去处理,整个任务耗时就在倾斜分区上了。
窗口数据倾斜优化方案,常见的是做重分区。这里也是类似的原理,如果分成四个分区以后,并行度就会更高。我们常见的方法是加前缀,比如说对所有男性,我们加不同的前缀1和2。加完前缀以后,我们对加完前缀的key再做分区,并行1的场景并行就可以变成2,这是传统的解决方案,但并不能解决窗口计算,也就是不能处理时序特征计算的倾斜问题。
假设这是一个时序特征,输入和输出都是四行,每一行假设它的窗口是某个用户前两条数据,到自己这一条数据,它的窗口数据先进行分区。第一条数据前面没有数据,计算是正确的。第二条数据它只有一条数据,而且在这个分区里面可以找到这个数据,前两条结果是一致的,第三条开始就不一致了。在原本的表里面,都是男性,前面有两条数据,应该在聚合计算的时候,应该要包含前两个数据。但是我们做了重分区以后,在这个分区里面前面是没有数据的,窗口计算只计算了单条,输出结果优化前后是不一致的。
OpenMLDB的解决方案是通过四步来实现。从最终的结果优化可以看到,优化前是并行度为2,优化后并行度为4,至少可以提升一倍。

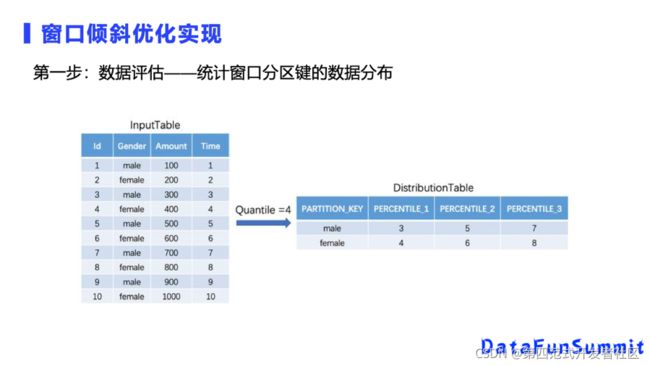
第一步是数据评估,首先统计一下这个数据是否有数据倾斜,假设有数据需要重新分区,我们把每个数据重新分成多块,这个例子就是先统计知道这四块里面在20%、50%、70%的数据是什么,然后可以把数据均匀分成多块,每一块的数据量都是接近的。而计算每一块的25%是多少,需要全量的数据统计,这里可以做一个近似的查询,查询到每一个数据的排序键25%的位置的值是多少就可以,近似计算性能也比全量统计好很多。
第二步是数据标记,拿到数据分布表以后就可以对数据打标记,这里使用的Join,做一个拼表的操作。把它加进去根据每一个数据针对它的PERCENTILE做分析。比如说男和女的数据,均匀分成四份,每一行和几个百分比值做比较,第一条分到第一个块,后面数据分别分到第二、第三、第四个块。有了新增的添加列,我知道每一行数据是第几块以后,就可以对每一块数据做扩充了。

第三步做数据扩充,第二个分区做窗口计算时,很可能需要用到第一个分区的数据,我们在扩充第一个分区的数据时,加一个筛选条件为ID小于2,把符合条件的列选出来,顺便设置一个标志位,原始数据不变并做一次Unicn,最后多次Unicn以后表数据量会变多,原来是十行,扩充后是二十行。

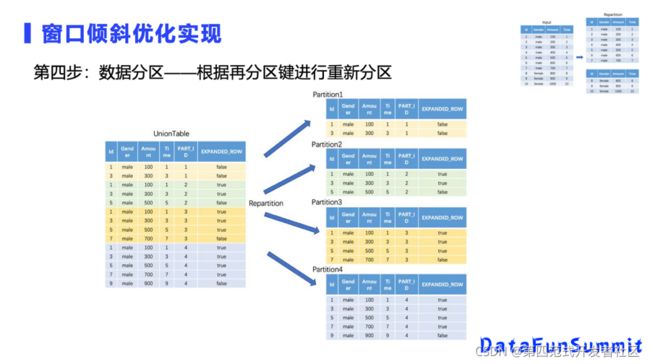
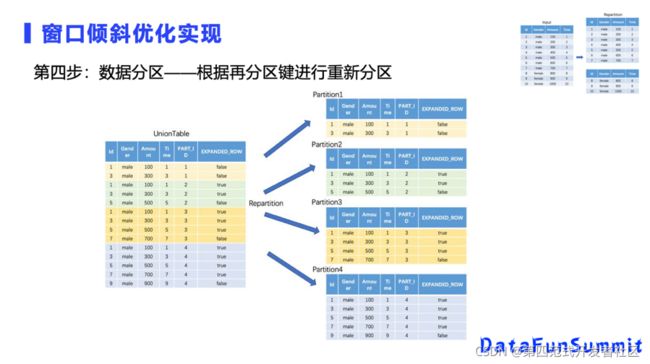
第四步是数据的重分区,很原来的不一样,原来我们只有男和女两个分区。我们以男性这个分区为例,假设说这里并行度为4的话,每个分区所做的窗口的聚合计算,它的数据都是足够的,不会漏数据。和原来的表相比,男性原来可以只分成一个分区,经过优化以后可以分成四个。
第五步做重分区后的滑窗计算。原本每个分区有多条数据,例如输入两条就应该输出两条,这里如果直接输出多条的话,最终的输出结果就跟原来优化前不一致了。因此我们做了一个Window计算的优化,经过数据扩充进来的数据,我们不让它输出结果,它只参与滑动窗口的计算,底层会加入窗口数据的队列中。前两条数据只是为了算第三条而存在的,本身不需要输出的。最终在执行的时候,会把前两条数据放在窗口里面,但是不输出,第三条数据做窗口计算的时候,可以拿到前面的结果,输出一个正确的结果。因此,才可以保证输出的结果数据,例如这里的男性分区一共是五条,跟优化前也是一样的。
经过窗口倾斜优化后,OpenMLDB对比了最新版本的SparkSQL,本身OpenMLDB相比Spark就已经有四倍的性能提升了。加上倾斜优化以后,相比Spark的倍数提升更多,相比于没有倾斜优化,提升也比较明显。此外,倾斜优化资源越多的话,性能提升也会更加明显。
四.计算优化汇总
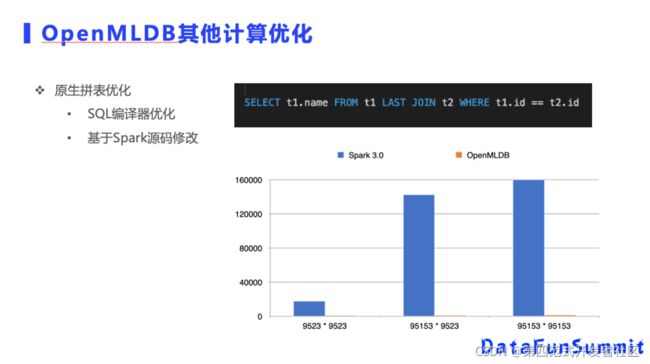
最后一部分给大家介绍一下其他的优化细节,汇总一下风控场景下的计算优化方案。第一个是原生的拼表实现,假设T1和T2这个表要做拼接,但是希望拼接后主表数据量不变,不会因为拼表后某个数据的样本量变多,这是一种特殊的拼表需求。我们可以基于Spark来实现,但是它的性能会比较差,OpenMLDB可以实现接近一百倍的性能提升,底层则是基于Spark源码修改支持的新型原生拼表实现。
第二个是内存ZeroCopy优化,OpenMLDB底层执行引擎是使用C++实现的,所有的函数计算都不用JAVA的实现了,但JAVA对象本身是没办法通过指针来获取数据的。
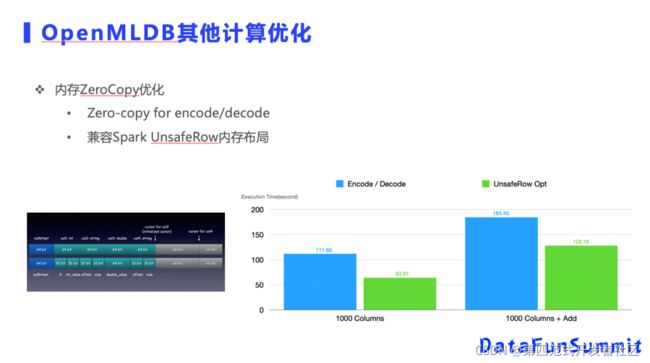
我们做得比较极致的对接了Spark UnsafeRow格式,虽然Spark是基于JAVA/Scala实现的,但是它内部有一种内存管理机制,我们实现了对Spak行对象内存布局的兼容。左边是Spark UnsafeRow的内存布局,每列的值都是按照特定的格式存储。我们做了一个内存的兼容接口,可以直接在往UnsafeRow的内存进行读写,每一列通过指针的偏移计算就可以得到列的值。实现了这个功能以后,我们就不需要对Spark的行做编解码转化了,性能提升也是很明显的。在一千列的Columns的时候,运行时间可以减少一半左右。
最后欢迎大家持续关注第四范式OpenMLDB:
OpenMLDB开源地址:https://github.com/4paradigm/OpenMLDB