MySQL 加锁规则
1、名词解释
1.1、快照读
快照读简单的来说就是简单的select 操作,没有加任何锁。在Innodb 存储引擎下执行简单的select操作时,会记录当前的快照读数据,之后的select 会沿用第一次快照读的数据,即使有其他事务提交也不会影响当前select 结果,因此通过快照读查询的数据虽然是一致的,但有可能不是最新的数据,而是历史数据。
1.2、当前读
使用select … for update 或者 update、delete 读取到的都是当前最新的数据。(update\delete 去修改数据的时候都是先查询出最新的数据)
2、next-key lock 加锁规则
前提:存储引擎支持行锁。
细节:
在MySQL 中,行级锁并不是直接锁记录,而是锁索引。InnoDB 行锁是通过给索引加锁实现的。
索引分为主键索引和非主键索引。
如果一条SQL 语句操作了主键索引,MySQL 就会锁定这条主键索引;
如果一条语句操作了非主键索引,MySQL 会先锁定该非主键索引,再锁定相关的主键索引。如果没有索引,InnoDB 会通过隐藏的聚簇索引来记录加锁。也就是说:如果不通过索引条件检索数据,那么InnoDB 将对表中所有数据加锁,实际和表记锁一样。
加锁的规则总结以下几点:
- 加锁的基本单位是next-key lock 左开右闭
- 查询过程中只要访问到的数据都会加锁
- 唯一索引等值查询时,需要访问到第一个不满足条件的值,如果匹配next-key lock 会退化为行锁。
- 索引等值查询时,需要访问到第一个不满足条件的值,此时的next-key lock会退化为间隙锁(GAP lock)
- 索引范围查询需要访问到不满足条件的第一个值为止
实例:
创建user 表,建表的初始化语句如下:
CREATE TABLE `user`
( `id` int(11) NOT NULL AUTO_INCREMENT,
`class` tinyint(4) NOT NULL,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
KEY `idx_class` (`class`) USING BTREE)
ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
插入数据:
INSERT INTO next_key_lock (`class`,`name`)
VALUES
(1,'咔咔'),
(3,'小刘'),
(8,'小张'),
(15,'小李'),
(20,'张但'),
(25,'王五'),
(25,'李四');
2.1、唯一索引等值查询
修改id 为 9 的记录

新增一条记录

修改id 为 7的记录

分析这条SQL 满足的规则:
规则一:查询过程中只要访问到的数据都会加锁,加锁的基本单位是next-key lock,左开右闭。
规则二:唯一索引等值查询,next-key lock 退化为行锁。
规则三:索引等值查询,需要访问到第一个不满足条件的值,此时的next-key lock 会退化为间隙锁。
根据规则一:加锁范围为(7,∞]
根据规则二:退化为行锁,但明显此条SQL 不满足条件,因为表里不存在id=9的这条记录,所以此规则不生效。
根据规则三:next-key lock 退化为间隙锁,加锁范围为(7,∞)
结论:
唯一索引等值查询时,行数据存在的时候是行锁,行数据不存在,那就是好间隙锁。
因此终端2的语句会一直处于等待状态,直到终端1执行完成。
2.2、普通索引等值查询
给class=8 这条记录加共享读锁

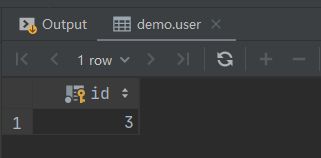
修改id = 3 这条记录的 name 值

新增一条记录 class = 9

分析这条SQL 满足哪些规则:
规则一:查询过程中只要访问到的数据都会加锁,加锁的基本单位next-key lock,左开右闭状态。
规则二:索引等值查询,需要访问到第一个不满足条件的值,此时的next-key lock 会退化伟间隙锁。
根据规则一:加锁范围是(3,8]
根据规则二:需要访问到第一个不满足的值,加锁的范围(8,15],又因为会退化为间隙锁,加锁范围变为(8,15)
结论:
三条SQL 执行后,第二个SQL执行成功,第三个SQL等待。
第三个SQL新增的值是9,在锁范围内需要等第一个SQL提交事务后才执行成功。
为什么第二个SQL会执行成功???
总结的加锁规则中,查询过程中访问到的数据都会加锁,但第二个SQL使用的是覆盖索引,所以并不需要回表查询主键索引,所以主键索引上是没有加任何锁的。
在B+tree中主键索引叶子节点存储的是整行数据,而普通索引叶子节点存储的是主键的值。
扩展
当前这个例子中,加的是lock in share mode 共享锁,锁的是覆盖索引,但是如果是for update就会给主键索引上满足条件的行加上行锁。所以使用覆盖所有是避免不了数据被热更新的,若要实现数据避免更新就需要绕过覆盖索引的优化。
使用for update 会给主键索引加锁,如果查询条件为普通索引但值存在多个相同的数据的,此时的加锁就会根据主键索引加锁。
2.3、主键索引范围锁
当前表记录:
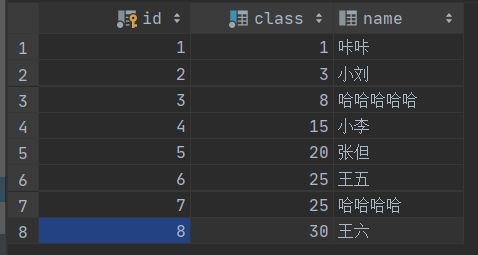
给id >= 8 and id < 10 加范围锁

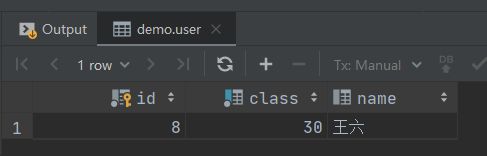
新增一条记录 class = 30,name = 李四1111111111111

修改id = 8 的记录的name值

从上面的案例得知:
第二个SQL和第三个SQL都处于等待第一个SQL执行中
分析上面案例的加锁规则:
规则一:访问到的数据都会加锁
规则二:唯一索引等值查询,next-key lock 会退化为行锁
根据规则一:加锁范围(7,8]
根据规则二:退化为行锁,加锁范围只是id=8 这一行
根据规则三:范围查询就往后找到第一个不满足条件的值,这里id=8后面没有记录,所以加锁的范围是(8,∞]
结论:
此条SQL加锁范围,行锁id=8,next-key lock (8,∞]
为什么从next-key lock 退化为行锁???
首先需要明白是等值判断还是范围判断,指这一行数据被查询选中的时候走的判断条件是通过a=b还是a>b 或a
从SQL执行结果可得知数据是根据id = 8来的,因此next-key lock 会退化为行锁。
2.4、普通索引范围锁
执行SQL为:
select * from user wehre class >= 8 and class < 10 for update;
可以看到这个SQL 和前面那个主键索引范围锁非常相似,唯一区别就是普通索引没有退化行锁的规则。
分析这条SQL 满足哪些规则:
规则一:索引等值查询需要访问到第一个不满足的值,next-key lock 退化为间隙锁
规则二:索引范围查询需要访问到不满足条件的第一个值为止
根据规则一:加锁范围(7,8]
根据规则二:加锁范围(8,15]
结论:
加锁的范围为(7,8],(8,15]
为什么没有退化为间隙锁???
仔细看规则得出,索引等值查询需要访问到不满足的值才会退化为间隙锁,此时是可以访问到8这个数据的,因此不会退化为间隙锁。
2.5、普通索引倒叙范围锁
在以上的所有案例中都是默认正序规则,接下来看倒叙的加锁规则是怎么样的。
执行SQL 为:
select * from next_key_lock where class >= 15 and class<=20 order by desc lock in share mode;
由于SQL加上了order by,因此第一个要定位class 索引最右边的值,也就是class = 20,因为class 是普通索引等值查询,因此会加上next-key lock 左开右闭 (15,20],普通索引等值查询会访问到不满足条件的值为止,所以还会继续扫描,直到遇到25,又会加上一个next-key lock (20,25],又因为25不满足查询条件,因此会退化为间隙锁(20,25)。
还有一个条件是class >= 15,向左扫描到class = 8 才会停下来知道了是小于15 了,加锁单位是next-key lock,左开右闭范围是(3,8]。
又因为查询是 * ,绕过了覆盖索引,需要回表查询,因此给主键ID也会加锁,加锁为id = 4,id = 5 两个行锁。
结论:
这条SQL 加锁范围是在索引class 是(3,25),主键索引上id = 4, 5 两个行锁。
3、总结
唯一索引等值查询,如果查询到数据,next-key lock 会退化为行锁,如果查询不到数据则依赖是间隙锁。
普通索引等值查询,next-key lock 退化为间隙锁。