k8s--基础--6.1--环境搭建--多master高可用集群
k8s–基础–6.1–环境搭建–多master高可用集群
前提
使用root用户
1、机器
| 主机名 | IP | 说明 |
|---|---|---|
| master1 | 192.168.187.154 | 2核4G,硬盘20G,核数最小要求是2 |
| master2 | 192.168.187.155 | 2核4G,硬盘20G,核数最小要求是2 |
| master3 | 192.168.187.156 | 2核4G,硬盘20G,核数最小要求是2 |
| node1 | 192.168.187.157 | 2核4G,硬盘20G,核数最小要求是2 |
2、公共配置
所有机器都要做
2.1、修改主机名
hostnamectl set-hostname master1
hostnamectl set-hostname master2
hostnamectl set-hostname master3
hostnamectl set-hostname node1
2.2、配置hosts文件
cat >> /etc/hosts <2.3、安装kubeadm和kubelet
# 安装kubeadm和kubelet,kubeadm和kubelet版本一定要一致
yum -y install kubelet-1.18.2 kubeadm-1.18.2 kubectl-1.18.2 --disableexcludes=kubernetes
# 查看版本
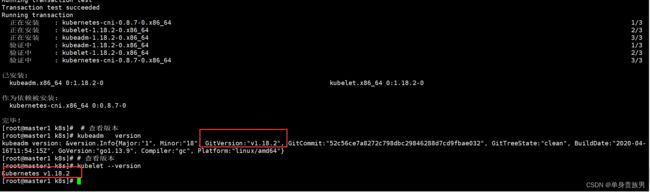
kubeadm version
# 查看版本
kubelet --version
# 开机启动
systemctl enable kubelet

2.3.1、解决kubeadm自动安装高版本问题

重新安装对应的kubelet版本
yum -y remove kubelet
yum -y install kubelet-1.18.2 kubeadm-1.18.2 kubectl-1.18.2 --disableexcludes=kubernetes
# 查看版本
kubeadm version
# 查看版本
kubelet --version
2.4、安装镜像
2.4.1、安装资料
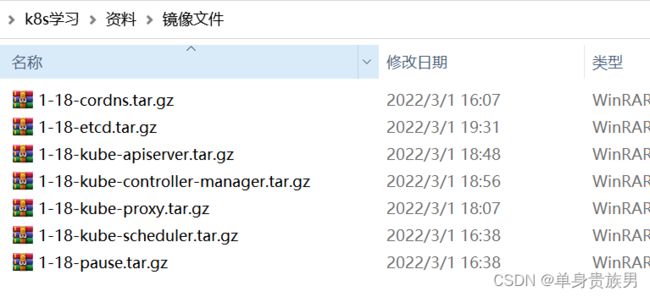
2.4.2、安装镜像
docker load -i 1-18-kube-apiserver.tar.gz
docker load -i 1-18-kube-scheduler.tar.gz
docker load -i 1-18-kube-controller-manager.tar.gz
docker load -i 1-18-pause.tar.gz
docker load -i 1-18-cordns.tar.gz
docker load -i 1-18-etcd.tar.gz
docker load -i 1-18-kube-proxy.tar.gz

2.4.3、镜像版本
k8s.gcr.io/pause:3.2
k8s.gcr.io/etcd:3.4.3-0
k8s.gcr.io/coredns:1.6.7
k8s.gcr.io/kube-apiserver:v1.18.2
k8s.gcr.io/kube-controller-manager:v1.18.2
k8s.gcr.io/kube-scheduler:v1.18.2
k8s.gcr.io/kube-proxy:v1.18.2
3、部署keepalived+lvs
在各master节点操作
3.1、下载keepalived
yum install libnl* popt* -y
yum install -y socat keepalived ipvsadm conntrack
3.2、修改配置文件
vim /etc/keepalived/keepalived.conf
3.2.1、master1 配置
# 全局定义块
global_defs {
# 路由器标识,可以改,默认为本地主机名。故障发生时,邮件通知会用到。
# 在局域网内应该是唯一的,注意和backup节点区分开。
router_id LVS_DEVEL
}
# 定义一个虚拟路由器的实例,实例名称VI_1
vrrp_instance VI_1 {
# 状态只有MASTER和BACKUP两种,并且要大写,MASTER为工作状态,BACKUP是备用状态。
state BACKUP
# 工作模式,nopreempt表示工作在非抢占模式,默认是抢占模式 preempt
nopreempt
# 对外提供服务的网卡接口,即VIP绑定的网卡接口。如:eth0,eth1。当前主流的服务器都有2个或2个以上的接口(分别对应外网和内网),在选择网卡接口时,一定要核实清楚。
interface ens32
# 虚拟路由ID,如果是一组虚拟路由就定义一个ID,如果是多组就要定义多个,
# 而且这个虚拟ID还是虚拟MAC最后一段地址的信息,取值范围0-255
# 同一个vrrp_instance的MASTER和BACKUP的vitrual_router_id 是一致的。
virtual_router_id 80
# 优先级,同一个vrrp_instance的MASTER优先级必须比BACKUP高。
priority 100
# MASTER 与BACKUP 负载均衡器之间同步检查的时间间隔,单位为秒。
advert_int 1
# 验证authentication。包含验证类型和验证密码。类型主要有PASS、AH 两种,通常使用的类型为PASS.
# auth_pass 1111 验证密码为明文,同一vrrp 实例MASTER 与BACKUP 使用相同的密码才能正常通信。
authentication {
auth_type PASS
auth_pass 1111
}
# 虚拟VIP地址,可以有多个地址,每个地址占一行,不需要子网掩码
# 同时这个ip 必须与我们在lvs 客户端设定的vip 相一致!
virtual_ipaddress {
# IP/掩码 dev 配置在哪个网卡
192.168.187.160
}
}
# 定义LVS集群服务,名称可以是IP+PORT,也可以是fwmark 数字,也就是防火墙规则
virtual_server 192.168.187.160 6443 {
# 健康检查时间间隔,单位:秒
delay_loop 6
# 负载均衡调度算法,互联网应用常用方式为wlc或rr
lb_algo loadbalance
# 负载均衡转发规则。包括DR、NAT、TUN 3种,一般使用路由(DR)转发规则。
lb_kind DR
# 子网掩码,这个掩码是VIP的掩码
net_mask 255.255.255.0
# http服务会话保持时间,单位:秒
persistence_timeout 0
# 转发协议,分为TCP和UDP两种
protocol TCP
# 真实服务器IP和端口,可以定义多个
real_server 192.168.187.154 6443 {
# 负载权重,值越大,转发的优先级越高
weight 1
# SSL_GET方法去健康检查
SSL_GET {
# 检测URL
url {
# 具体检测哪一个URL
path /healthz
# 除了检测哈希值还可以检测状态码,比如HTTP的200 表示正常,两种方法二选一即可
status_code 200
}
# 连接超时时间
connect_timeout 3
# 服务连接失败重试次数
nb_get_retry 3
# 重试连接间隔,单位:秒
delay_before_retry 3
}
}
real_server 192.168.187.155 6443 {
weight 1
SSL_GET {
url {
path /healthz
status_code 200
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
real_server 192.168.187.156 6443 {
weight 1
SSL_GET {
url {
path /healthz
status_code 200
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
}
3.2.2、master2 配置
global_defs {
router_id LVS_DEVEL
}
vrrp_instance VI_1 {
state BACKUP
nopreempt
interface ens32
virtual_router_id 80
priority 50
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.187.160
}
}
virtual_server 192.168.187.160 6443 {
delay_loop 6
lb_algo loadbalance
lb_kind DR net_mask 255.255.255.0
persistence_timeout 0
protocol TCP
real_server 192.168.187.154 6443 {
weight 1
SSL_GET {
url {
path /healthz
status_code 200
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
real_server 192.168.187.155 6443 {
weight 1
SSL_GET {
url {
path /healthz
status_code 200
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
real_server 192.168.187.156 6443 {
weight 1
SSL_GET {
url {
path /healthz
status_code 200
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
}
3.2.3、master3 配置
global_defs {
router_id LVS_DEVEL
}
vrrp_instance VI_1 {
state BACKUP
nopreempt
interface ens32
virtual_router_id 80
priority 30
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.187.160
}
}
virtual_server 192.168.187.160 6443 {
delay_loop 6
lb_algo loadbalance
lb_kind DR
net_mask 255.255.255.0
persistence_timeout 0
protocol TCP
real_server 192.168.187.154 6443 {
weight 1
SSL_GET {
url {
path /healthz
status_code 200
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
real_server 192.168.187.155 6443 {
weight 1
SSL_GET {
url {
path /healthz
status_code 200
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
real_server 192.168.187.156 6443 {
weight 1
SSL_GET {
url {
path /healthz
status_code 200
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
}
3.3、启动keepalived
3.3.1、顺序master1->master2->master3 启动keepalived
# 加入开机启动 keepalived
systemctl enable keepalived
# 启动
systemctl start keepalived
# 状态
systemctl status keepalived
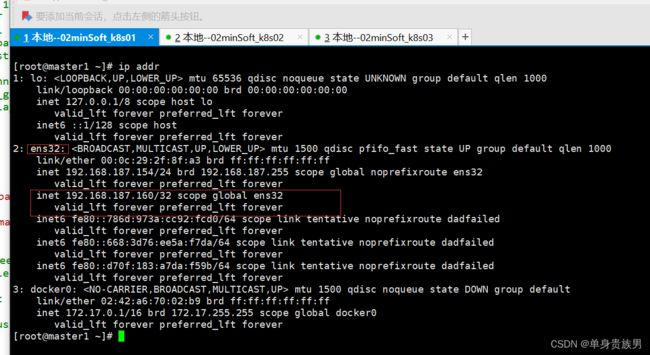
3.3.2、查看是否成功
ip addr
4、初始化k8s集群
在master1节点初始化k8s集群。
4.1、创建初始化配置文件
mkdir -p /root/k8s/
vim /root/k8s/kubeadm-config.yaml
内容
# api版本
apiVersion: kubeadm.k8s.io/v1beta2
# 资源类型
kind: ClusterConfiguration
# 资源版本
kubernetesVersion: v1.18.2
# 虚拟IP
controlPlaneEndpoint: 192.168.187.160:6443
apiServer:
# 哪些IP生成证书
certSANs:
- 192.168.187.154
- 192.168.187.155
- 192.168.187.156
- 192.168.187.157
- 192.168.187.160
networking:
# pod 的网段
podSubnet: 10.244.0.0/16
---
# api版本
apiVersion: kubeproxy.config.k8s.io/v1alpha1
# 资源类型
kind: KubeProxyConfiguration
# 模式
mode: ipvs
4.2、初始化k8s集群
kubeadm init --config /root/k8s/kubeadm-config.yaml
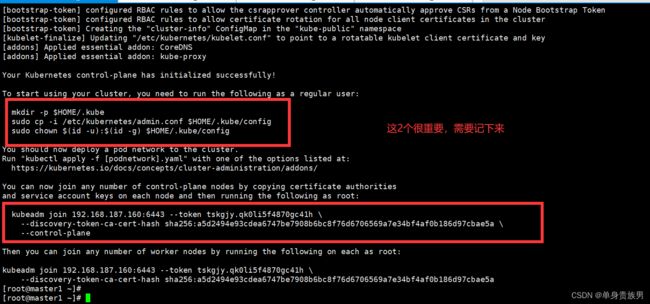
kubeadm join … 这条命令需要记住,我们把k8s的master2、master3,node1节点加入到集群需要输入这条命令。
4.3、在master1节点执行如下,这样才能有权限操作k8s资源
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
4.4、检测上面命令是否成功
只有成功,下面的命令才有权限执行
4.4.1、获取节点
kubectl get nodes

4.4.2、获取pod
kubectl get pods -n kube-system
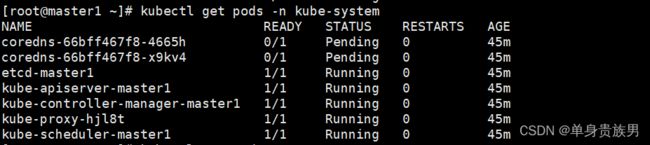
4.4.3、问题
上面可以看到master1的STATUS状态是NotReady,pods的cordns是pending。
这是因为没有安装网络插件,需要安装calico或者flannel。
5、安装网络插件:calico
在master1节点安装calico网络插件
5.1、安装镜像
在master1,master2,master3,node1上安装
5.1.1、安装资料
5.1.2、安装镜像
docker load -i cni.tar.gz
docker load -i calico-node.tar.gz
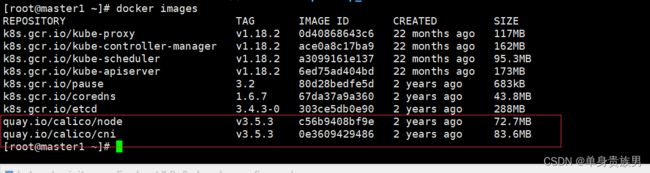
5.1.3、镜像版本
quay.io/calico/node:v3.5.3
quay.io/calico/cni:v3.5.3
5.2、上传配置文件
在master1执行


5.2.1、修改内容
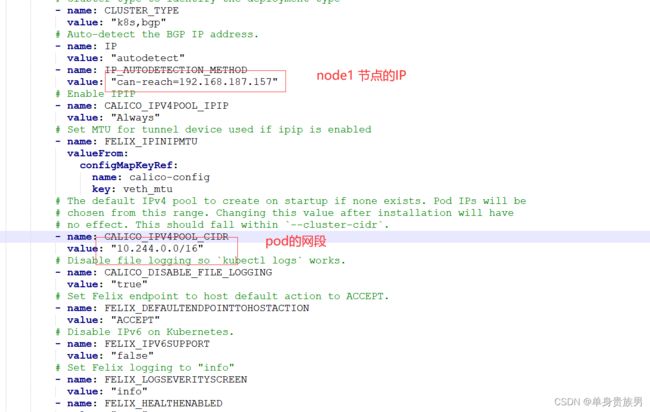
5.3、执行操作
在master1执行
kubectl apply -f /root/k8s/calico.yaml
5.4、检测
在master1执行
kubectl get nodes
kubectl get pods -n kube-system
# 显示节点信息
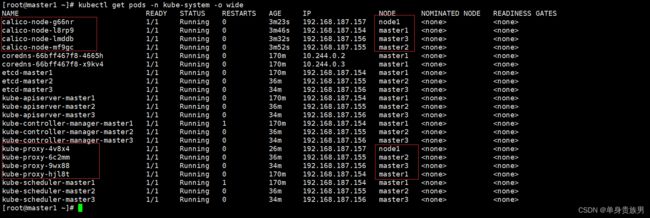
kubectl get pods -n kube-system -o wide
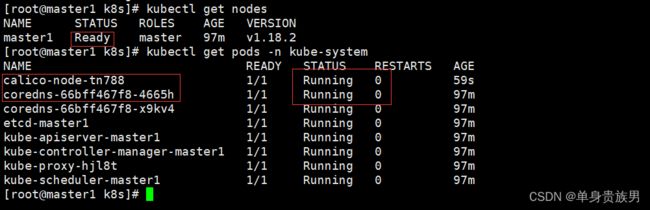
上面可以看到master1的STATUS状态是Ready,pods的cordns是running
说明master1节点的calico安装完成
6、配置master1到各个机器的无密码登陆
- 目的方便复制文件
- 在master1操作
6.1、生成证书
cd
ssh-keygen -t rsa
一直回车就可以
6.2、将公钥复制到对应的节点上
ssh-copy-id -i .ssh/id_rsa.pub root@master2
ssh-copy-id -i .ssh/id_rsa.pub root@master3
ssh-copy-id -i .ssh/id_rsa.pub root@node1
7、拷贝证书
把master1节点的证书拷贝到master2和master3上
7.1、 在master2和master3上创建证书存放目录
cd
mkdir -p /etc/kubernetes/pki/etcd
mkdir -p ~/.kube/
7.2、在master1节点上把证书拷贝到master2和master3
在master1上操作
scp /etc/kubernetes/pki/ca.crt master2:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/ca.key master2:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/sa.key master2:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/sa.pub master2:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/front-proxy-ca.crt master2:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/front-proxy-ca.key master2:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/etcd/ca.crt master2:/etc/kubernetes/pki/etcd/
scp /etc/kubernetes/pki/etcd/ca.key master2:/etc/kubernetes/pki/etcd/
scp /etc/kubernetes/pki/ca.crt master3:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/ca.key master3:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/sa.key master3:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/sa.pub master3:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/front-proxy-ca.crt master3:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/front-proxy-ca.key master3:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/etcd/ca.crt master3:/etc/kubernetes/pki/etcd/
scp /etc/kubernetes/pki/etcd/ca.key master3:/etc/kubernetes/pki/etcd/
8、master2和master3加入到集群
master2和master3都要执行以下操作
8.1、加入集群
kubeadm join 192.168.187.160:6443 --token tskgjy.qk0li5f4870gc41h \
--discovery-token-ca-cert-hash sha256:a5d2494e93cdea6747be7908b6bc8f76d6706569a7e34bf4af0b186d97cbae5a \
--control-plane
–control-plane:表示加入到k8s集群的是master节点
8.2、在节点上执行如下,这样才能有权限操作k8s资源
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
8.3、查看节点信息
kubectl get nodes
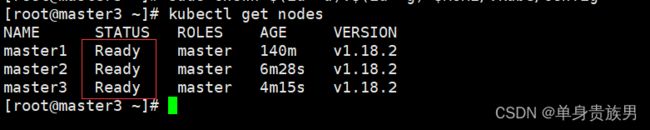
上面图片说明master2和master3已经加入到集群
9、node1节点加入到k8s集群
在node1节点操作
9.1、加入集群
kubeadm join 192.168.187.160:6443 --token tskgjy.qk0li5f4870gc41h \
--discovery-token-ca-cert-hash sha256:a5d2494e93cdea6747be7908b6bc8f76d6706569a7e34bf4af0b186d97cbae5a
9.2、查看节点信息
在master1上执行
kubectl get nodes
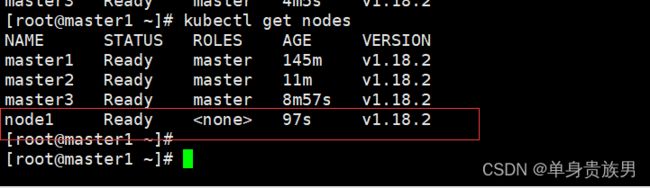
说明node1节点也加入到k8s集群了
通过以上就完成了k8s多master高可用集群的搭建
10、最终节点状态
kubectl get pods -n kube-system -o wide