广告行业中那些趣事系列16:NLPer一定要知道的BERT文本分类优化策略及原理
本篇一共7100个字

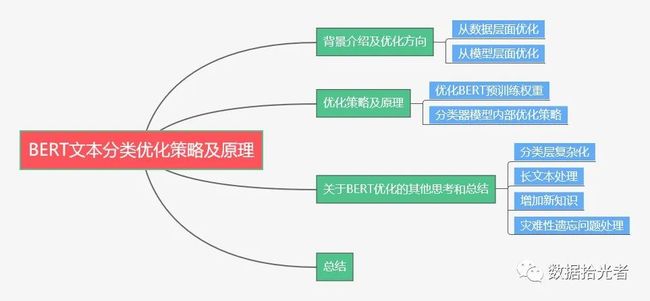
摘要:本篇主要分享了项目实践中的BERT文本分类优化策略和原理。首先是背景介绍及优化方向,其中优化方向主要分成从数据层面优化和模型层面优化;然后通过实验的方式重点分析了分类器优化策略和原理,主要从优化BERT预训练权重和分类器模型内部优化策略优化分类器效果;最后分享了一些关于BERT优化的思考和总结,包括分类层是否应该复杂化、长文本处理、增加新知识和灾难性遗忘问题的处理。优化永无止境,本篇内容也会持续更新,把项目实践中有价值的优化技巧通过文章及时固化,也希望更多的小伙伴一起分享文本分类优化技巧。
下面主要按照如下思维导图进行学习分享:
![]()
01 背景介绍及优化方向
还是老规矩,介绍下写这篇文章的背景。笔者从事文本分类项目实践已经有一段时间了,其间也积累了很多实用的优化策略。这里的优化策略不仅仅是书面上的“纸上谈兵”,而是真正在实际业务中能有巨大提升的“奇淫巧计”,所以权当笔记总结分享出来,和大家一起交流探讨。
关于文本分类,总的来说主要有两大优化方向,一个是从数据层面优化,另一个是从模型层面优化。下面分别从这两个方面说明:
1.1 数据层面优化
从数据层面优化文本分类器,也就是获得更多更好的训练语料。因为实际项目中主要使用的是目前NLP领域大火的BERT模型,实质是借助迁移学习把提前学习到的海量的语言学知识应用到下游实际项目中,所以整体来看模型效果是有保障的,这也是BERT在工业界尤其在各大厂都大受欢迎的原因。在这样的前提下,我们只需要根据实际的业务去想办法搞到更多更好的训练语料。
目前项目中主要通过人工标注和关键词匹配相结合的方式获取训练语料,在获得一定的训练语料之后想进一步获得更多更好的语料就要从以下两方面开展工作了:一方面,在一定的语料基础上想要获得更多的语料就需要借助样本增强技术,之前也写过一篇文章
《广告行业中那些趣事系列13:NLP中超实用的样本增强技术》因为通过人工标注或者关键词匹配的方法得到的语料或多或少都会有错误样本存在,这些错误数据会降低模型的识别能力,所以提升语料的质量也至关重要。关于置信学习寻找错误标注样本的文章正在酝酿当中,感兴趣的小伙伴可以关注下。从数据层面优化文本分类模型不是本篇的重点,一笔带过。
1.2 模型层面优化
上面说过,BERT模型效果是比较好的,那么在原生BERT模型的基础上能否进一步优化?答案是肯定的。总体来说,基于BERT模型的优化主要包括预训练权重优化、是否微调、分类层优化、NLP任务优化等等。下面会重点通过实验的方式对这些优化策略进行说明,同时会附上效果提升与否的原理分析。
![]()
02 优化策略及原理
在进行优化实验前,先对文本分类器测试流程和实验进行说明。实际项目中建立机器学习模型之前重中之重是确定模型的评估方式,只有结合业务确定了模型的评估方式,才有模型优化的方向。
实际项目中文本分类器效果评估主要分成两步,第一步是在测试集评估,评估指标是精度、召回率和F1得分。将训练语料按照8:2划分成训练集和测试集,所以测试集和训练集是同分布的。测试集主要用来评估模型在同分布下的识别效果,这是分类器效果评估的第一步;第二步是在真实分布数据集评估。线上真实分布数据集是获取线上头部query数据进行人工标注得到的测试集,和训练集的分布有一定差别。这部分数据集主要用来评估模型在线上的识别效果,同时还可以辅助有效的扩充训练语料。
通常情况下,模型在测试集上表现效果较好,在真实分布数据集上会有所下降,主要原因是测试集和训练集同分布,这样使得在测试集上预测的也较好。而真实分布数据集合训练集语料空间差别很大,有很多训练集从没出现过的样本,可以理解成“特征不足”。通过分析线上真实分布数据集的错误样本可以有效提升模型的线上识别能力,这也是线上真实分布数据集可以辅助模型有效的扩充训练语料的原因。这里一定要明确,我们分类器的最终目标是在线上真实分布数据集上有很好的效果。
本次实验主要选择汽车标签作为参考,有以下两个原因:一方面,汽车是我们类目体系中的一级类目,优先级较高;另一方面,我们有足够的汽车训练语料和真实分布数据。这是分别基于业务和实验可靠性的角度考虑最终选择汽车二分类器。
因为是实际项目,不便给出实际的测试集评估数据,所以这里给出各个实验组相比对照组的指标提升比例,通过指标提升比例也能很好的看出各个优化策略给模型带来的提升情况。指标提升的计算公式为:提升比例=(实验组-对照组)/对照组。对照组是使用谷歌原生态的BERT-Base, Chinese,这个预训练权重主要使用中文语料学习得到。分词器使用中文、英文等单个字符切分,主要原因是减少未登录词(OOV)的影响。同时模型不进行微调。这里不进行微调主要是基于模型线上性能和分类效果的双重考虑,这里因为暂时申请了专利,所以不便细讲。等专利确定好了以后我会出一篇文章详细讲下我们在复杂类目体系下构建分类器的线上方案。总结下来对照组是如下操作:
对照组:使用谷歌原生态BERT-Base,Chinese预训练模型,单个字符分词,不微调。
模型层面优化主要通过优化BERT预训练权重和分类器模型内部优化策略两方面进行。
2.1优化BERT预训练权重
优化BERT预训练权重主要分成谷歌原生态预训练权重和BERT-wwm预训练权重。
2.1.1 BERT原生预训练权重优化
这组实验主要对比谷歌原生预训练权重对分类器的效果影响。下图是BERT原生模型提供的预训练权重,其中红色是我们线上正在使用的预训练权重,也是对照组正在使用的中文预训练权重,实验组分别对比绿色的两个预训练权重,其中BERT-Large,Cased是使用更多英文语料并且模型更加复杂的Large版本,使用了24层Transformer作为特征抽取器(基础base版本使用了12层Transformer作为特征抽取器),这个主要想看看复杂模型对于分类器的影响,这里暂且设置为实验组1(这里需要说明下,其实对比复杂模型对于分类器的影响最好使用中文语料训练的Large版本,但是目前是没有的,所以这里只能退而求其次使用英文语料训练的Large版本);
同时对比多语言版本BERT-Base,Multilingual Cased,该预训练权重使用多语言文本进行训练,使用12层Transformer作为特征抽取器。进行这组实验主要原因是我们的query中包含中英文两种语言,所以想看看多语言预训练权重能否提升分类器效果,这里设置为实验组2。

图1 谷歌原生BERT预训练权重
总结下来就是对比如下实验:
对照组:使用谷歌原生态BERT-Base, Chinese预训练模型,单个字符分词,不微调;
实验组1:使用谷歌原生态BERT-Large,Cased,单个字符分词,不微调;
实验组2:使用谷歌原生态BERT-Base,MultilingualCased,单个字符分词,不微调。
实验结论及原理分析:
表1 谷歌原生BERT预训练权重效果提升表
指标 |
对照组 |
lab1 |
lab2 |
|
测试集 |
精度 |
a |
-36.73% |
-2.04% |
召回率 |
b |
-47.25% |
-45.05% |
|
F1得分 |
c |
-42.55% |
-29.79% |
|
真实分布数据集 |
精度 |
d |
-85.19% |
-85.19% |
召回率 |
e |
-71.25% |
12.50% |
|
F1得分 |
f |
-85.00% |
-82.50% |
从上面的实验数据可以看出,对于业务场景中主要是中文的搜索的情况下谷歌Large版本复杂预训练权重和多语言版本权重对于分类器的识别效果有很大的下降。这个实验结论其实很好理解,因为对照组使用的是中文语料进行训练,而我们实际业务场景也主要是中文的搜索query,所以使用BERT-Base, Chinese版本更加合理一些。
2.1.2 BERT-wwm预训练权重优化
上面对比了谷歌原生BERT预训练权重,下面对比下哈工大讯飞联合实验室发布的BERT-wwm预训练模型。因为谷歌发布的BERT-Base, Chinese模型里中文是以字为粒度进行切分,在BERT预训练过程中基于掩码的Masked Language Model(MLM)任务中也以字粒度进行Mask操作。BERT-wwm针对这个问题进行一系列中文式的改造,充分考虑传统NLP中的中文分词操作,以词为粒度进行Mask操作,也就是Whole Word Masking(wwm)操作。下面直接通过一个样本示例进行说明:
表2 全词Mask操作样本说明
说明 |
样例 |
原始文本 |
我喜欢吃西瓜,还喜欢跑步 |
原始Mask |
我喜欢吃Mask瓜,还喜欢跑Mask |
分词文本 |
我 喜欢 吃 西瓜 ,还 喜欢 跑步 |
全词Mask |
我喜欢吃Mask Mask,还喜欢Mask Mask |
假如原始Mask将文本中的“西”和“步”进行了Mask操作,全词Mask则考虑分词结果将“西瓜”和“跑步”都进行Mask操作。这种操作其实和百度的Ernie模型有异曲同工之妙,主要是结合中文的实际应用场景,应用知识图谱加入更多中文语义的信息。下图是BERT-wwm官网提供的预训练权重版本,本组实验主要对比绿色框中的预训练权重。
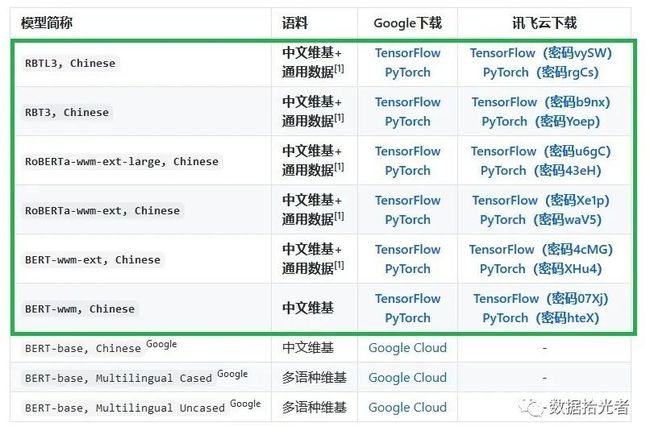
图2 BERT-wwm预训练权重
根据上图进行说明,设置实验组3使用BERT-wwm,Chinese预训练权重,主要使用中文维基语料和全词掩码的方式进行训练;
设置实验组4使用BERT-wwm-ext,Chinese预训练权重,和实验组3相比增加了通用数据,这里通用数据包括:百科、新闻、问答等数据,总词数达5.4B,处理后的文本大小约10G;
设置实验组5使用RoBERTa-wwm-ext,Chinese预训练权重。RoBERTa权重是Facebook提出的预训练模型,刷新了很多英文数据集的最好成绩,所以该预训练权重是基于RoBERTa模型和全词掩码的方式进行训练得到的;
设置实验组6使用RoBERTa-wwm-ext-large,Chinese预训练权重,和实验组5的区别是使用了更复杂的24层Transformer(基础版本使用12层Transformer)模型;
设置实验组7和实验组8分别使用RBT3,Chinese和RBTL3,Chinese和,分别使用了三层RoBERTa-wwm-ext-base/large,其实就是小参数量模型。
总结下来就是对比如下实验:
对照组:使用谷歌原生态BERT-Base, Chinese预训练权重,单个字符分词,不微调。
实验组3:使用哈工大讯飞实验室BERT-wwm,Chinese,单个字符分词,不微调。
实验组4:使用哈工大讯飞实验室BERT-wwm-ext,Chinese,单个字符分词,不微调。
实验组5:使用哈工大讯飞实验室RoBERTa-wwm-ext,Chinese,单个字符分词,不微调。
实验组6:使用哈工大讯飞实验室RoBERTa-wwm-ext-large,Chinese,单个字符分词,不微调。
实验组7:使用哈工大讯飞实验室RBT3,Chinese,单个字符分词,不微调。
实验组8:使用哈工大讯飞实验室RBTL3,Chinese,单个字符分词,不微调。
实验结论及分析:
表3 BERT-wwm预训练权重效果提升表
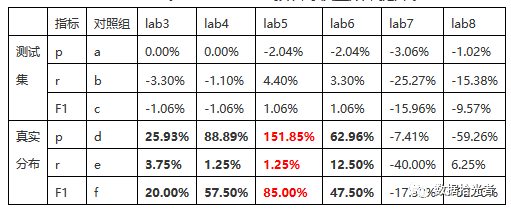
从上面实验数据可以看出,BERT-wwm相比于原生BERT模型分类效果是有明显提升的。这里需要说明下,实际项目中发现测试集效果指标一般比较好,对比中丁点的变化基本可以忽略,而真实分布数据集则一般效果较差,所以我们需要重点对比在真实分布数据集下的指标提升。先说说实验组7和实验组8,相比于对照组均有很大下降,主要原因是仅使用了三层RoBERTa-wwm-ext,还没有微调,自然效果是不理想的。这种小参数模型其实更多的是使用到线上推理流程,重点满足时效性。
其他实验组3到6在真实分布数据集上均有不同的提升,其中最亮眼的是实验组5的RoBERTa-wwm-ext,Chinese预训练模型,提升非常明显。RoBERTa从模型上来说没有多少创新,主要在以下几点进行了调整:(1)训练时间更长,batch size更大,训练数据更多;(2)移除了next predict loss;(3)训练序列更长;(4)动态调整了Masking机制。通过上面这些优化调整在很多公开数据集上相比于原生BERT有较大提升。单纯从我们目前复杂的文本分类系统来看,工程角度最简单有效的就是修改一下预训练模型即可有效提升分类器效果。这里比较意外的是实验组6的效果竟然不如实验组5提升的明显,如果从本次实验结果来看也间接说明了模型不一定越复杂越好。
总体来看,基于全词掩码的BERT-wwm权重相比于谷歌原生权重有较大的效果提升,提升的原因主要在于通过知识图谱的方法加入了更多的中文语义信息。为了排除单个分类器实验偶然性的风险,我除了在汽车分类器上进行实验,同时挑选了其他几个分类器进行实验,最终实验结论是一致的,在真实分布数据集上均有比较明显的提升。
2.2 分类器模型内部优化策略
上面主要从BERT预训练权重进行优化,下面是实际项目中总结的分类器模型内部优化策略。因为对照组没有对BERT模型进行微调,所以这里需要对比下微调对分类器效果的影响,这里设置为实验组9;
在实际项目中进行badcase分析时发现很多纯英文样本识别错误,对照组中不论中文还是英文都使用单个字符进行切分,所以这里使用BERT原生的分词器进行实验。原生分词器对于中文使用单个字符分词,英文使用wordpiece进行分词。通过这组实验想查看英文分词对于分类器效果的影响,设置为实验组10;
这里同时考虑将文本分类任务转化为句子对关系任务来查看分类器效果。对照组是对一条query进行分类,是典型的文本分类任务,由于label是0或者1,所以没有很好的利用标签本身的描述信息。这里思考能否将标签描述信息也添加到文本识别任务中,具体做法是将query作为句子1,将标签描述信息转换为句子2,让BERT模型去识别句子1和句子2是否有相似关系。这种改造在项目工程中只需要在分词操作时统一对训练集添加second=‘句子2’即可,也就是tokenizer.encode(first=text,second='句子2')。为了方便起见,我这里将句子2设置为简单的“汽车”,相当于把任务改成了query和“汽车”是不是相似语句,样本中标签为1的就变成了相似的样本,为0则代表不相似。这里设置为实验组11。
总结下来就是对比如下实验:
对照组:使用谷歌原生态BERT-Base, Chinese预训练模型,单个字符分词,不微调。
实验组9:使用谷歌原生态BERT-Base, Chinese预训练模型,单个字符分词,微调。
实验组10:使用谷歌原生态BERT-Base, Chinese预训练模型,中文根据单个字符切分,英文通过wordpiece切分,不微调。
实验组11:使用谷歌原生态BERT-Base, Chinese预训练模型,中文根据单个字符切分,英文通过wordpiece切分,同时添加second=‘汽车’,将任务改造为句子对关系任务,不微调。
实验结论及分析:
表4 一些其他模型优化操作效果提升表
实验指标 |
对照组 |
lab9 |
lab10 |
lab11 |
|
测试集 |
精度 |
a |
-2.04% |
0.00% |
-2.04% |
召回率 |
b |
6.59% |
0.00% |
3.30% |
|
F1得分 |
c |
2.13% |
0.00% |
1.06% |
|
真实分布 |
精度 |
d |
66.67% |
7.41% |
151.85% |
召回率 |
e |
17.50% |
-2.50% |
2.50% |
|
F1得分 |
f |
52.50% |
7.50% |
85.00% |
从上面实验结果可以看出,实验组9测试集精度有一定下降,召回有一定提升,整体变化不明显。但是在真实分布数据集效果有较大提升,所以证明使用BERT微调可以有效提升分类器的效果。这个实验结论比较好理解,在同分布下BERT是否微调对于分类器效果影响不大。但是在线上真实分布数据集中因为语料空间变化很大,需要模型有更强的识别能力,所以需要微调来进一步提升模型的识别能力;
实验组10在真实分布数据集上效果有轻微提升,所以对于英文使用wordpiece也可以提升分类器效果;
最后实验组11效果有较大提升,将文本分类任务转化成句子对关系任务可以很好的利用标签描述信息,有效提升分类效果。这里还仅仅使用了“汽车”一个词。如果可以挖掘到更多能代表汽车标签的关键词,拼接之后作为句子2应该可以带来更多的效果提升。目前这块打算通过BERT构建实体识别任务,获取汽车标签的实体信息,然后选择pv较高query的实体信息进行拼接。
小结下,本节主要从优化BERT预训练权重和分类器模型内部优化策略来提升分类器效果,主要有以下重要结论:首先,因为用户搜索主要是中文query,所以在谷歌原生BERT预训练权重里中文版本的预训练权重效果最好;然后,BERT-wwm使用基于全词Mask的预训练权重,通过知识图谱可以获取到更多表达中文语义的语言学知识,可以有效提升分类器效果,尤其是基于RoBERTa-wwm-ext,Chinese预训练权重表现出色;最后,对比了一些分类器模型内部优化策略带来的提升,基于BERT微调的确能提升模型的分类效果,基于wordpiece的英文分词可以提升模型的分类效果。将文本分类任务转化成句子对关系任务可以将标签描述信息提供给模型,可以有效提升分类器的识别效果。
![]()
03 关于BERT优化的思考和总结
上面从预训练权重和分类器模型内部优化策略来提升分类器识别效果。对于模型来说,优化永无止境。关于BERT分类器优化的其他思考和总结如下:
1.分类层是否使用更加复杂的结构。目前分类层是使用一层全连接层,可以考虑添加全连接层数。这个优化方案其实有做过尝试,在测试集和真实分布数据集上效果没有太大变化。关于分类层优化问题,网上也查了很多资料,主要的看法是建议BERT后面添加的层越少越好,主要原因有两个:一个原因是BERT本身就足够复杂,它有足够能力应对你要做的很多任务;另一个原因是加的层都是随即初始化的,加太多会对BERT的预训练权重造成剧烈扰动,容易降低效果甚至造成模型不收敛。关于分类层是否使用复杂的结构需要结合实际项目进行详细实验论证;
2.长文本的处理。BERT处理的最大文本长度是512,除去开始CLS和结束SEP标志,也就剩下510了。对于长度大于510的文本主要有三种方式:取头部510,取尾部510,取头部和尾部一共510。实验证明取头部和尾部一共510的方式效果更好,这个其实也容易理解。对于一篇长文,文章的重点一般会出现在头部和尾部,所以取头部和尾部也就可以理解文章的核心内容了;
3.新知识的学习。一些大厂会基于BERT原生预训练权重训练自己的预训练模型,比如前面分享的文章里《广告行业中那些趣事系列15:超实用的基于BERT美团搜索实践》美团会使用自己的数据去训练MT-BERT,构建自己的BERT预训练模型可以有效提升模型在特定领域的效果。可以这么理解,谷歌使用通用文本得到的预训练权重会具有更好的普适性,但是缺点也很明显。很好的普适性反面就是特有领域的效果会打一定折扣。针对这种情况很多大厂会使用自己特有领域的数据来让BERT学习新知识,这样的预训练权重也会更加适合特有领域的下游任务。这个在美团的实践中也有论证;
4.灾难性遗忘问题的处理。迁移学习中容易出现学习新知识时可能会忘记以前很重要的旧知识,这就是灾难性遗忘。针对这个问题,可以使用较低的学习率克服这个问题。
![]()
总结
本篇主要分享了BERT文本分类优化策略和原理。首先介绍了业务背景和文本分类优化方向,优化方向主要包括从数据层面优化和模型层面优化;然后通过实验的方式重点分析了分类器优化策略和原理,主要从优化预训练权重和分类器模型内部优化策略来提升分类器效果;最后分享了一些关于BERT优化的其他思考和总结,包括分类层是否应该复杂化、长文本处理、增加新知识以及灾难性遗忘问题的处理。优化永无止境,本篇内容也会持续更新,把项目实践中有价值的优化策略及时固化,也希望更多的小伙伴一起分享文本分类优化技巧。
![]()
参考资料
[1]https://github.com/google-research/bert
[2]https://github.com/ymcui/Chinese-BERT-wwm
[3]https://github.com/brightmart/roberta_zh