广告行业中那些趣事系列39:实战广告场景中的图片相似度识别任务
导读:本文是“数据拾光者”专栏的第三十九篇文章,这个系列将介绍在广告行业中自然语言处理和推荐系统实践。本篇从理论到实践介绍了广告场景中的图片相似度识别任务,对于希望解决图片相似度识别任务的小伙伴可能有所帮助。
欢迎转载,转载请注明出处以及链接,更多关于自然语言处理、推荐系统优质内容请关注如下频道。
知乎专栏:数据拾光者
公众号:数据拾光者
摘要:本篇从理论到实践介绍了广告场景中的图片相似度识别任务。首先介绍了背景,通过用户连续曝光相似广告素材图片的广告会影响用户体验引出图片相似度任务,同时介绍了google提供的“相似图片搜索”服务;然后介绍了基于phash算法的图片相似度识别,包括当前的基于phash算法获取图片素材指纹、phash算法实现流程、phash算法效果展示图以及源码实践、phash算法的优点和不足和通过聚类解决部分素材图片裁剪相似度低的问题;最后介绍了微软开源的cv-recipes项目实现图片相似度识别,作为图像类任务的百宝箱开源项目可以解决各类图像机器学习问题,重点介绍了其中的图片相似度识别子模块。对于希望解决图片相似度识别任务的小伙伴可能有所帮助。
下面主要按照如下思维导图进行学习分享:
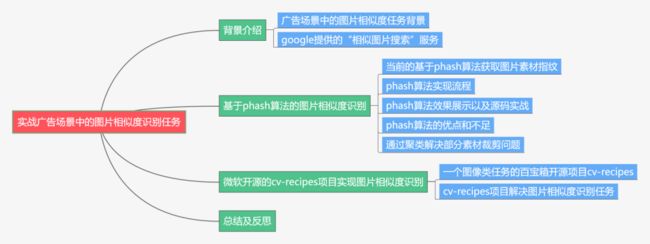
01
背景介绍
还是按照惯例介绍下业务背景,当我们搜索“传奇游戏”时浏览器会曝光对应的广告,可能会存在连续曝光的两个广告图片素材是一样或者是非常相似的,这样会影响用户的体验。针对这种情况,需要识别广告素材图片的相似度,从而给用户曝光的广告素材图片有一定的多样性,提升品控。下面是用户连续曝光相似广告素材图片实例图:
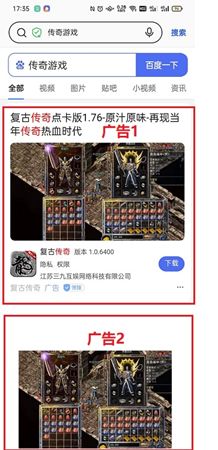
图1 用户连续曝光相似广告素材图片
将业务问题抽象成机器学习任务就是相似图片识别任务。除了上面广告场景中的应用,图片相似度识别任务还出现在很多应用场景中,比如google提供的“相似图片搜索”服务。google支持用户输入一张图片或者图片地址,返回和这张图片相似的图片。下面是google相似图片搜索任务示例图:

图2 google相似图片搜索服务
小结下,本节主要介绍了我们广告场景中遇到的因为用户连续曝光相似广告图片素材所以导致用户体验降低场景。还介绍了图片相似识别任务被应用到google提供的“相似图片搜索”服务中。
02
基于phash算法的图片相似度识别
2.1 当前的基于phash算法获取图片素材指纹
当前我们解决图片相似度识别任务主要是基于phash(感知哈希算法,Perceptual hash algorithm)算法,基本原理就是对每张图片生成一个“指纹”字符串,通过对比不同图片的指纹从而计算图片之间的相似度。
2.2 phash算法实现流程
phash算法计算图片相似度主要有以下几个流程:
首先将图片统一转化为小图,一般为(64X64)。这个操作的目的是去除图片的细节,只保留结构、明暗等基本信息,摒弃图片尺寸、比例等带来的图片差异;
然后对图片进行灰度处理,简化色彩。将原来三通道RGB图片转化成黑白图,减少下游计算量;
接着对图片进行DCT离散余弦变换,得到DCT系数矩阵;
然后缩小DCT,将原来标准大小(64X64)的图片使用左上部分(一般设置为16X16)的图片替代,从而进一步提升计算速度;
接着计算DCT中间值,也就是计算缩小之后的256个像素点的中间值;
然后比较像素的灰度。将DCT得到的256个像素点和中间值进行比较,如果大于等于中间值则设置为1,否则设置为0;
最后计算哈希值,并通过哈希值判断是否相似。上一步得到的256位就是图片的素材指纹,对比两张图片的相似度时只需要查看256位相同的个数即可。
2.3 phash算法效果展示以及源码实战
展示phash算法效果之前先介绍下测试图片集。从广告素材中先选择三张不同的图片1.jpg、2.jpg和3.jpg。因为广告素材中经常会加入文案,想查看phash算法对于同一张广告素材中添加文案语料的相似度打分,所以在2.jpg中添加一句中文文案得到22.jpg。广告主在使用图片素材时会对图片进行等比例缩小,所以将22.jpg图片进行缩放得到222.jpg。广告主还会对广告素材图片进行裁剪,这里先在2.jpg中获取中间的部分得到4.jpg,然后对4.jpg进行部分裁剪得到41.jpg。下面是构建的图片测试集示例图:

图3 构建的图片测试集示例图
下面是通过phash算法计算两张图片的相似度效果图:

图4 通过phash算法计算两张图片的相似度
使用phash算法计算两张图片的相似度,先得到每张图片的phash值,然后计算相似度的公式=1-(编码一样的个数)/总个数。下面是各种不同的情况相似度得分:
当两张图片完全一样时(image_1=image_2=22.jpg)相似度为1,因为是完全相同的图片,所以得分是最高的;
当两张完全不同的素材图片时(image_1=22.jpg,image_2=1.jpg)相似度仅为0.53125;
当在一张素材图片中添加文案语料时(image_1=22.jpg,image_2=2.jpg)相似度为0.984375,相似度比较高,说明phash算法对于素材图片中添加文案语料的情况相似度得分比较高;
当对一张图片进行缩放操作时(image_1=22.jpg,image_2=222.jpg)相似度为0.9375;
当对一张图片进行部分裁剪操作时(image_1=4.jpg,image_2=41.jpg)相似度仅为0.53125。
从上面的效果展示示例中可以看出phash算法对于图片中添加文案语料、图片缩放的情况得到的相似度得分比较高,均在0.9分以上,但是对于图片部分裁剪相似度得分会非常低。
下面给出phash算法的源码:
# func:根据phash算法获取哈希值
# PIL:Python Imaging Library,已经是Python平台事实上的图像处理标准库了。PIL功能非常强大,但API却非常简单易用
from PIL import Image
from PIL import ImageFilter
from PIL import ImageOps
import math
def get_matrix(image):
matrix = []
size = image.size
for height in range(0,size[1]):
pixel = []
for width in range(0,size[0]):
# getpixel函数是用来获取图像中某一点的像素的RGB颜色值
pixel_value = image.getpixel((width,height))
pixel.append(pixel_value)
matrix.append(pixel)
return matrix
def get_coefficient(n):
matrix = []
PI = math.pi
sqr = math.sqrt(1/n)
value = []
for i in range(0,n):
value.append(sqr)
matrix.append(value)
for i in range(1,n):
value=[]
for j in range (0,n):
data = math.sqrt(2.0/n) * math.cos(i*PI*(j+0.5)/n);
value.append(data)
matrix.append(value)
return matrix
def get_transposing(matrix):
new_matrix = []
for i in range(0,len(matrix)):
value = []
for j in range(0,len(matrix[i])):
value.append(matrix[j][i])
new_matrix.append(value)
return new_matrix
def get_mult(matrix1,matrix2):
new_matrix = []
for i in range(0,len(matrix1)):
value_list = []
for j in range(0,len(matrix1)):
t = 0.0
for k in range(0,len(matrix1)):
t += matrix1[i][k] * matrix2[k][j]
value_list.append(t)
new_matrix.append(value_list)
return new_matrix
def DCT(double_matrix):
# DCT,即离散余弦变换,常用图像压缩算法
n = len(double_matrix)
A = get_coefficient(n)
AT = get_transposing(A)
temp = get_mult(double_matrix, A)
DCT_matrix = get_mult(temp, AT)
return DCT_matrix
def sub_matrix_to_list(DCT_matrix, part_size):
# 缩小DCT,将原来size大小的图片使用左上部分part_size大小的图片来替代
# 然后将matrix转化成list
# 这里是为了进一步提升计算速度
w, h = part_size
List = []
for i in range(0,h):
for j in range(0,w):
List.append(DCT_matrix[i][j])
return List
def get_middle(List):
# 取中间值
li = List.copy()
li.sort()
value = 0
if len(li)%2!=0:
index = int((len(li)/2))
value = li[index]
else:
index = int((len(li)/2))
value = (li[index]+li[index-1])/2
return value
def get_code(List, middle):
# 计算phash值
result = []
for index in range(0,len(List)):
if List[index] > middle:
result.append("1")
else:
result.append("0")
return result
if __name__ == "__main__":
# 图片地址
image_path = " /image_data/22.jpg"
# 将图片转化成统一大小
standard_size = (32, 32)
# 对图片进行压缩之后的尺寸的大小,主要目的是提升速度
part_size = (16, 16)
# 打开一张图片
img = Image.open(image_path)
# step1:首先获取统一大小的图片,设置尺寸一般为小图;然后对图片灰度化处理,简化色彩
# 主要目的是可以减少下游DCT的计算量
# 这里图片的像素点会从原来的三通道(16,15,13)变成黑白点14
gray_img = img.resize(standard_size).convert('L').filter(ImageFilter.BLUR)
# 均衡直方图,使用一个非线性映射到输入图像,为了产生灰色值均匀分布的输出图像。
gray_img = ImageOps.equalize(gray_img)
# step2:将图片转换成一个standard_size的矩阵
img_matrix = get_matrix(gray_img)
# step2: 对图片进行离散余弦变换DCT变化,得到的DCT系数矩阵
img_DCT_matrix = DCT(img_matrix)
# step3:缩小DCT,将原来standard_size大小的图片使用左上部分part_size大小的图片来替代
# 主要目的是进一步提升计算速度
img_DCT_list = sub_matrix_to_list(img_DCT_matrix, part_size)
# step4:获取DCT中间值
img_DCT_middle = get_middle(img_DCT_list)
# step5:计算phash值,如果大于中间值则为1,否则为0
phash_code = get_code(img_DCT_list, img_DCT_middle)
print(phash_code)
感兴趣的小伙伴可以亲自尝试下phash算法。
2.4 phash算法的优点和不足
从上面phash算法的效果展示图和源码实践可以看出phash算法的优点在于简单容易实现,计算速度也比较快,可以识别出广告素材图片添加文案语料以及缩放的情况,可以作为一个很好的baseline使用。但是phash算法也存在一个问题,对于部分裁剪的图片得到的相似度得分非常低,如果用户连续曝光的广告素材图片是部分裁剪的操作,那么phash算法是无法识别出的。
2.5 通过聚类解决部分素材裁剪问题
为了解决phash算法对于部分裁剪图片得到的相似度得分很低问题,可以对广告素材图片进行聚类操作。下面是基于phash算法和kmeans算法相结合对广告素材图片进行聚类的效果图:

图5 对广告素材图片进行聚类的效果图
使用phash算法得到图片的哈希值作为embedding,然后使用kmeans算法进行图片聚类操作。当设置聚类数为2时,41.jpg、4.jpg、2.jpg、22.jpg和222.jpg会聚为1类,1.jpg、11.jpg(和1.jpg一样)、3.jpg会聚为1类。当聚类数为3时,41.jpg和4.jpg会聚为1类,2.jpg、22.jpg和222.jpg会聚为1类,1.jpg、11.jpg和3.jpg会聚为1类。可以发现通过聚类的方法可以将部分裁剪的图片聚为一类。
小结下,本节主要介绍了phash算法解决广告素材图片相似度任务,包括phash算法的原理、实现流程、效果展示以及源码实践,总结了phash算法的优点和不足,最后介绍了通过聚类算法可以将部分裁剪的广告素材图片聚到一类。
03
微软开源的cv项目实现图片相似度识别
3.1 一个图像类任务的百宝箱开源项目cv-recipes
上面主要是通过phash算法得到图片的哈希值作为embedding向量,然后进行相似度计算得分或者聚类操作。为了得到图片更高质量的embedding向量特征,调研了很多开源项目,感觉最靠谱实用的是微软开源的cv-recipes,开源项目地址如下:
https://github.com/microsoft/computervision-recipes
微软开源的cv-recipes项目是一个非常好用的图像类任务的百宝箱,目前已经有8K的star,支持的图像类任务也非常多,包括图片分类、图片相似识别、目标检测、关键点检测、图片分割、动作识别以及图片追踪等任务,对于想快速上手并且落地图像类任务的小伙伴可能会有帮助,下面是微软开源的cv-recipes项目支持的图片任务汇总图:
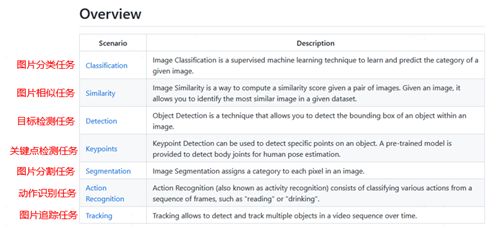
图6 微软开源的cv-recipes项目支持的图片任务汇总
3.2 cv-recipes项目解决图片相似度识别任务
解决图片相似度识别任务主要是通过开源项目中的similarity子任务,下面是github地址:
https://github.com/microsoft/computervision-recipes/tree/master/scenarios/similarity
对图片使用ResNet-18模型提取特征得到512维embedding向量,进行L2归一化后计算相似度距离作为图片的相似度得分。下面是模型结构图:
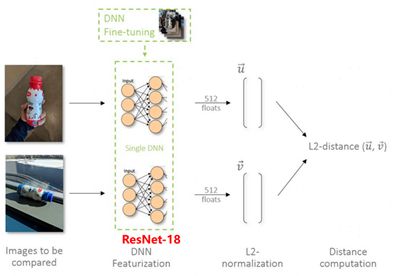
图7 cv-recipes的图片相似度模型结构图
下图中第一张是目标图片,从候选图片集中识别出相似度最高的6张图片,下面是cv-recipes的图片相似度识别项目效果图:

图8 cv-recipes的图片相似度识别项目效果图
小结下,本节主要介绍了微软开源的cv-recipes开源项目,这是一个支持多种图像类任务的百宝箱项目,重点介绍了其中的图片相似识别任务。
03
总结及反思
本篇从理论到实践介绍了广告场景中的图片相似度识别任务。首先介绍了背景,通过用户连续曝光相似广告素材图片的广告会影响用户体验引出图片相似度任务,同时介绍了google提供的“相似图片搜索”服务;然后介绍了基于phash算法的图片相似度识别,包括当前的基于phash算法获取图片素材指纹、phash算法实现流程、phash算法效果展示图以及源码实践、phash算法的优点和不足和通过聚类解决部分素材图片裁剪相似度低的问题;最后介绍了微软开源的cv-recipes项目实现图片相似度识别,作为图像类任务的百宝箱开源项目可以解决各类图像机器学习问题,重点介绍了其中的图片相似度识别子模块。对于希望解决图片相似度识别任务的小伙伴可能有所帮助。
04
参考资料
【1】https://github.com/microsoft/computervision-recipes
最新最全的文章请关注我的微信公众号或者知乎专栏:数据拾光者。

码字不易,欢迎小伙伴们点赞和分享。