广告行业中那些趣事系列40:广告场景文本分类任务样本优化实践汇总
导读:本文是“数据拾光者”专栏的第四十篇文章,这个系列将介绍在广告行业中自然语言处理和推荐系统实践。本篇介绍了我们实际项目文本分类任务样本优化实践汇总,
对于希望提升文本分类任务线上效果的小伙伴可能有所帮助。
欢迎转载,转载请注明出处以及链接,更多关于自然语言处理、推荐系统优质内容请关注如下频道。
知乎专栏:数据拾光者
公众号:数据拾光者
摘要:本篇介绍了我们实际项目文本分类任务样本优化实践汇总。首先样本层面优化文本分类任务需要解决如何又快又好的获取人工标注数据集、如何解决样本不均衡问题和如何获取更多的训练样本三个问题;然后通过主动学习可以又快又好的获取人工标注数据集以及通过损失函数解决样本不均衡问题;最后重点介绍了我们的半监督和自训练流程项目,主要包括半监督项目的目标以及基本流程。对于希望提升文本分类任务线上效果的小伙伴可能有所帮助。
下面主要按照如下思维导图进行学习分享:

01
样本层面优化文本分类任务需要解决的问题
之前写过一篇在实际工作中总结的文本分类项目模型层面的优化实践《广告行业中那些趣事系列37:广告场景中的超详细的文本分类项目实践汇总》,本篇总结下样本层面的优化实践。样本层面优化文本分类任务需要解决三个主要问题:
如何又快又好的获取人工标注数据集?NLP文本分类任务属于有监督学习任务,需要一定数量的人工标注数据集。如何在一定时间内利用有限的标注人力获取更多更高质量的标注样本对于分类器效果的影响至关重要;
如何解决样本不均衡问题?很多机器学习任务中都会遇到样本不均衡问题,尤其在多层级复杂标签体系的广告场景中,实际上我们广告体系是4级标签多达几百个标签,样本不均衡问题更加严重;
如何获取更多的训练样本?在机器学习尤其是深度学习场景中,训练样本的数量会直接影响分类器效果。通常情况下,训练样本的数量越多得到的模型效果越好,尤其在NLP文本分类任务中大家主流使用的模型都是BERT预训练类模型,也就是说模型的差异基本上已经很小了,那么决定模型最终效果的主要就是训练样本的多少和好坏了。
02
通过主动学习又快又好获取人工标注数据集
2.1 主动学习的作用
上面也说过NLP文本分类任务属于有监督学习,需要一定数量的人工标注数据作为训练集。如果不使用主动学习的话,一般是随机选择一定数量的样本进行标注。实际工作中可能还会结合一定的业务场景,比如在搜索场景中选择用户搜索量级较大的query进行标注。这种方法的好处是简单,但是缺点也很明显,随机选择的样本可能多样性较差(选出的样本可能有很多是部分重复的),而且是模型易于识别的简单样本。通过一个简单的中学生做习题的例子来说明,小明要完成100道数学题,如果使用随机选择策略的话只需要从练习簿中随机选择100道题即可。但是如果使用主动学习的策略,我们会选择习题种类更多(多样性较好),同时小明容易做错(模型难于识别的样本)的100道习题。虽然都是完成100道习题,但是最终的学习效果确差别很大。这里小伙伴们可能要纠结一个问题,难的数学题小明可能要花费更多的时间,但是在NLP场景对于一个熟练的标注员来说单条文本标注的时间基本上是相同的。
从上面的例子中可以看出,标注一定数量的文本,采用不同的样本选择策略得到的样本质量是不同的,从而最终得到的分类器效果也是不同的。不仅如此,标注成本是非常昂贵的。总结下来主动学习的作用就是在标注人力有限的情况下标注高质量样本从而使模型效果更好。
2.2 主动学习基本流程
主动学习主要包括无标签数据池、样本选择策略、标注者、标签数据集和机器学习模型五个核心部件,基本流程有以下几个步骤:
A从无标签数据池中根据一定的策略选择标注样本交给标注专家标注;
B标注专家对样本进行标注并将标注样本保存到标签数据集中;
C构建机器学习模型,使用标签数据集作为训练集进行模型训练。
主动学习就是不断的进行上述三个流程,直到分类器效果达到线上要求。主动学习最重要的核心在于样本选择策略,也就是如何选择高价值样本进行标注。下面是主动学习基本流程图:

图1 主动学习基本流程
2.3 主动学习查询策略的设计原则
主动学习最重要的是如何选择高价值样本进行标注,这里选择策略的设计主要有两个原则:不确定性原则和差异性原则。不确定性原则很好理解,就是选择那些模型不容易判别的样本提交给人工去标注,比如中学生做数学题选一些比较难并且易错的题来完成,这样可以学到更多的知识,相反的长期做简单题带来的提升很有限。差异性原则主要是选择的样本要具有一定的差异性,比如做的数学题尽量覆盖不同的章节和知识点,这样才能学到更全面的知识,相反的如果长期做某一章节某部分知识点的习题能力提升也很有限。总结下来主动学习查询策略的设计原则是尽量选择模型难于识别并且多样性较好的样本。
2.4 线上使用的主动学习策略
为了选择多样性较好的文本数据可以从聚类的角度进行。先获取文本的语义向量embedding表示,然后对语义向量进行聚类操作,最后选择的样本尽量覆盖多个聚类后的类别,通过这种方式可以得到多样性较好的文本数据。这里重点是获取高质量的文本语义向量embedding表示。如果直接用google原生BERT获取语义向量,会发现任意两个句子的向量相似度比较高,也就是说文本之间的区分度很差,那么聚类效果也比较差,主要原因是向量分布的非线性和奇异性使得BERT句向量并没有均匀的分布在向量空间中,对应的信息熵比较低。针对这个问题BERT-flow通过normalizing flow把语义向量映射到规整的高斯分布中,从而语义向量可以分布在相对均匀的空间中。还可以使用BERT-whitening对语义向量分布进行PCA降维操作去除冗余信息,也可以把语义向量映射到更均匀的向量空间中从而提升聚类效果。除此之外,我们还可以使用NLP场景中的对比学习模型SimCSE获取分布更均匀的语义向量。关于对比学习模型SimCSE的详细介绍小伙伴可以参考我之前写的一篇文章《广告行业中那些趣事系列35:NLP场景中的对比学习模型SimCSE》。
通过上述方法可以获得多样性较好的文本数据,接下来是获得模型难以识别的样本数据,主要使用不确定性策略。不确定性策略的重点是如何衡量样本难以识别的程度。主动学习中主要通过置信度最低策略、熵策略、基于委员会的策略等方法来衡量样本难以识别的程度。
首先说下置信度最低策略,也就是选择模型认为置信度最低的样本。这里以二分类任务为例,假如我们已经有一个初步训练好的模型,可以用这个模型去给样本打分,A样本得分为0.55,B样本得分为0.9分,那么可以认为模型对于B样本预测为正例的置信度很高,而对于A样本来说置信度很低,模型并不能很好的识别A样本,所以相比于B样本来说A样本的标注价值更高,可能给模型带来的效果提升也更好;
然后是熵策略,熵策略主要是利用信息论中的熵来判定样本的识别难度,因为信息论中熵是对不确定性的测量。感觉和置信度最低策略类似,主要是从不同的维度来衡量样本的不确定性;
最后是基于委员会的策略。从样本训练集不同或者模型不同构建多个分类器,选择分歧比较大的样本进行标注。比如我们会用google原生中文版BERT、RoBERTa和ernie模型训练三个分类器,让三个分类器去预测同一条样本,如果A样本模型分类是[1,1,1],B样本分类是[0,1,1],因为A样本中三个分类器一致预测为正例,而B样本中两个分类器预测为正例,一个分类器预测为负例,说明B样本的“分歧”比较大,模型难以识别,所以相比于A样本来说B样本的标注价值更高。我们线上也主要使用基于委员会的策略来选择不确定性高的样本进行标注。
小结下,本节主要通过主动学习从而又快又好的获取人工标注数据集,主要介绍了主动学习的作用、基本流程、查询策略的设计原则以及线上使用的主动学习策略。关于主动学习更详细的内容小伙伴们可以查看我之前写过的一篇文章《广告行业中那些趣事系列22:当文本分类遇上了主动学习》。
03
解决样本不均衡问题
我们文本分类项目中还遇到一个棘手问题就是样本不均衡问题,尤其在多层级复杂标签体系的广告场景中,实际上我们广告兴趣类目体系是4级类目多达几百个标签,样本不均衡问题更加严重。为了解决样本不均衡问题,我们线上主要对损失函数进行优化,使用Focal loss和GHM loss来缓解样本不均衡问题,取得不错的线上效果。关于样本不均衡问题的介绍之前也写过一篇文章进行了详细说明,感兴趣的小伙伴可以查看《广告行业中那些趣事系列24:从理论到实践解决文本分类中的样本不均衡问题》
04
半监督和自训练流程项目
4.1 半监督和自训练流程项目目标
为了提升分类器效果,我们线上构建了半监督和自训练流程项目框架。项目目标是使用少量的标注数据集就可以得到很好的分类器模型,整个系统的输入是带标签数据集和业务相关的海量无标签数据集,输出是一个很好的分类器模型。系统的核心思想是利用少量的带标签数据集从海量的无标签数据集中扩展伪标签数据加入到训练样本中,通过自训练流程不断的提升分类器效果。
4.2 半监督和自训练项目基本流程
半监督和自训练项目的基本流程图如下所示:
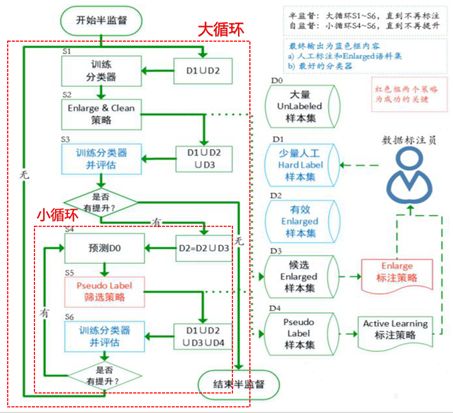
图2 半监督和自训练流程项目基本流程图
整体来看半监督和自训练流程项目基本流程如下:
S1使用少量带标签数据集D1和有效enlarged样本集D2合并得到训练集来训练一个初始分类器f0,这里需要注意的是第一轮训练时D2为空。训练完分类器之后记录模型效果;
S2使用enlarge&clean策略扩展伪标签样本并纠正错误样本。这是半监督项目的核心,通过各种enlarge策略来增加伪标签样本。线上使用的enlarge策略有利用simbert模型基于语义相似度来检索相似文本从而给无标签数据集D0打上伪标签。还可以使用初始分类器f0预测D0来打上伪标签。还可以通过对比学习模型SimCSE打上伪标签。这里enlarge策略非常丰富,可以说enlarge策略的好坏直接影响半监督流程的效果。因为标注的样本中可能存在误标的情况,所以需要对错误样本进行修正,也就是clean策略,实际工作中主要使用置信学习等方式来修正错误样本。这里enlarge&clean策略还会选择置信度较低的样本提交给标注人员标注,标注完成之后会添加到D1中;
S3将D1、D2和经过enlarge策略打上伪标签的候选enlarged样本集D3合并作为训练集用于训练新的分类器fi并评估模型效果。评估完成之后将fi和f0进行对比,如果没有提升则说明enlarge策略得到的D3数据集无效,直接结束半监督流程。如果有提升则说明D3有效,将D3加入到D2中,并进入后续流程;
S4使用新的分类器fi去预测D0数据集,这里进入了小循环自训练流程;
S5将S4得到的伪标签数据集使用PseudoLabel筛选策略得到Pseudo Label样本集D4。目前线上使用的筛选策略是根据模型预测得分选择伪标签样本,第一轮自训练流程会选择大于0.95分的正样本。这里得到D4有不同的策略,可以只选正样本,也可以正负样本都选。这里Pseudo label筛选策略会使用主动学习流程选择标注价值高的样本进行标注;
S6将D1、D2、D3和D4合并得到最新的训练数据集,然后训练新的分类器f(i+1)并进行评估。和之前的分类器进行对比,如果有提升,则说明D4有效,接下来进入到S4流程。如果没有提升则在第二轮自训练流程降低阈值选择得分大于0.9分的作为D4,继续训练新的分类器并评估。如果连续N次选出的D4都无效则退出当前的小循环并进入到S1开启下一次大循环流程。这里N的次数可以进行设置。
整个半监督流程重点是大循环和小循环的进入条件。当enlarge策略得到的D2无效时退出半监督流程,否则进入小循环。当连续N次D4无效时则退出小循环。明确了大循环和小循环的进入条件理解整个流程就变得容易了。半监督流程通过少量人工标注数据集提供的信息去获取更多的训练样本数据集,从而得到好的分类器。整个半监督流程可以应用到更广泛的分类任务中,包括NLP场景、CV场景等等,我们将模型训练、评估和预测流程通过脚本进行定制化,对于使用方来说仅仅需要关注数据流转过程即可。当前我们已经使用半监督流程优化线上文本分类器并取得不错的效果,正在向更简单易用的方向努力,后续可能会做到开源。还需要说明的是,半监督流程不仅仅是从样本层面对分类任务进行优化,模型训练、评估和预测流程中会将之前积累的模型层面的优化添加进来,对于样本不均衡问题也使用了Focal loss和GHM loss等。
05
总结及反思
本篇介绍了我们实际项目文本分类任务样本优化实践汇总。首先样本层面优化文本分类任务需要解决如何又快又好的获取人工标注数据集、如何解决样本不均衡问题和如何获取更多的训练样本三个问题;然后通过主动学习可以又快又好的获取人工标注数据集以及通过损失函数解决样本不均衡问题;最后重点介绍了我们的半监督和自训练流程项目,主要包括半监督项目的目标以及基本流程。对于希望提升文本分类任务线上效果的小伙伴可能有所帮助。
最新最全的文章请关注我的微信公众号或者知乎专栏:数据拾光者。

码字不易,欢迎小伙伴们点赞和分享。