【李宏毅HW3】
李宏毅机器学习HW3
- 二、torch的基本功能
- 三、PIL
- 四、torch.backends.cudnn.benchmark
- 五、transforms
- 六、nn.Conv2d
- 七、MaxPool2d
- 八、BatchNorm2d
-
-
- 输入参数:
-
- 九、torch.nn.Linear
- 十、torch.optim.Adam
代码解读
import numpy as np # linear algebra线性代数
import pandas as pd # data processing数据处理, CSV file I/O (e.g. pd.read_csv)
import os
import numpy as np # 提供操作矩阵功能
import torch
import os
import torch.nn as nn
import torchvision.transforms as transforms
import random
#“串联数据集”和“子集”在进行半监督学习时可能有用。"ConcatDataset" and "Subset" are possibly useful when doing semi-supervised learning.
from PIL import Image #图像处理库
from torch.utils.data import ConcatDataset, DataLoader, Subset, Dataset
from torchvision.datasets import DatasetFolder, VisionDataset
from tqdm.auto import tqdm # This is for the progress bar.这是进度条。
for dirname, _, filenames in os.walk('/kaggle/input'): # 输入数据文件在只读的../input/"目录
for filename in filenames:
pass
# print(os.path.join(dirname, filename))
myseed = 6666 # set a random seed for reproducibility为再现性设置随机种子
torch.backends.cudnn.deterministic = True 将这个 flag 置为True的话,每次返回的卷积算法将是确定的,即默认算法。如果配合上设置 Torch 的随机种子(seed)为固定值的话,应该可以保证每次运行网络的时候相同输入的输出是固定的。
torch.backends.cudnn.benchmark = False
#torch.backends.cudnn.benchmark设置这个 flag 可以让内置的 cuDNN 的 auto-tuner 自动寻找最适合当前配置的高效算法,来达到优化运行效率的问题。
np.random.seed(myseed) # 生成指定随机数,每次调用都seed()一下
torch.manual_seed(myseed)#设置 CPU 生成随机数的 种子
if torch.cuda.is_available(): #可以使用GPU
torch.cuda.manual_seed_all(myseed) #为所有GPU设置种子,生成随机数
#Torchvision为图像预处理、数据包装以及数据扩充提供了许多有用的工具。
#通常,我们在测试和验证中不需要增强。
#这里我们所需要的是调整PIL图像的大小并将其转换成张量。
test_tfm = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
])
#但是,也可以在测试阶段使用增强功能augmentation。transform专门负责图像预处理、实现图像增强的模块
#您可以使用train_tfm生成各种图像,然后使用集成方法进行测试。
#torchvision.transforms是pytorch中的图像预处理包,一般用Compose把多个步骤整合到一起。
train_tfm = transforms.Compose([
# 将图像调整为固定的形状(height = width = 128)
transforms.Resize((128, 128)),#图片统一缩放到128*128
# 你可以在这里添加一些变换。
# ToTensor()应该是最后一个转换。
transforms.ToTensor(),#把灰度范围从0-255变换到0-1之间
])
#数据由名称标记,因此我们在调用“getitem”时加载图像和标签
class FoodDataset(Dataset):
def __init__(self,path,tfm=test_tfm,files = None):
super(FoodDataset).__init__()
self.path = path
#os.listdir(path)中有一个参数,就是传入相应的路径,将会返回那个目录下的所有文件名。
#sorted() 函数对所有可迭代的对象进行排序操作
#os.path.join()函数用于路径拼接文件路径,可以传入多个路径
self.files = sorted([os.path.join(path,x) for x in os.listdir(path) if x.endswith(".jpg")])
if files != None:
self.files = files
print(f"One {path} sample",self.files[0])
self.transform = tfm
def __len__(self):
return len(self.files)
def __getitem__(self,idx):
fname = self.files[idx]
im = Image.open(fname)
im = self.transform(im)#在重写__getitem__的时候,会将数据增强的的代码也放在里面
#im = self.data[idx]
try: #把可能发生错误的语句放在try模块里,用except来处理异常。
label = int(fname.split("/")[-1].split("_")[0])
except:
label = -1 # test has no label
return im,label
class Classifier(nn.Module):
def __init__(self):
super(Classifier, self).__init__()
# torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
# nn.Conv2d:对由多个输入平面组成的输入信号进行二维卷积
# torch.nn.MaxPool2d(kernel_size, stride, padding)
# MaxPool最大池化层,池化层在卷积神经网络中的作用在于特征融合和降维。
# input 維度 [3, 128, 128]
# nn.Sequential是一个有序的容器,神经网络模块将按照在传入构造器的顺序依次被添加到计算图中执行,同时以神经网络模块为元素的有序字典也可以作为传入参数。
# BatchNorm2d()对输入的四维数组channel进行批量标准化处理
self.cnn = nn.Sequential(
nn.Conv2d(3, 64, 3, 1, 1), # [64, 128, 128]
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [64, 64, 64]池化,相当于128/2=64
nn.Conv2d(64, 128, 3, 1, 1), # [128, 64, 64]
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [128, 32, 32]
nn.Conv2d(128, 256, 3, 1, 1), # [256, 32, 32]
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [256, 16, 16]
nn.Conv2d(256, 512, 3, 1, 1), # [512, 16, 16]
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [512, 8, 8]
nn.Conv2d(512, 512, 3, 1, 1), # [512, 8, 8]
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [512, 4, 4]
)
self.fc = nn.Sequential(
nn.Linear(512*4*4, 1024), #(input_data, hidden_layer)做从输入层到隐藏层的线性变换
nn.ReLU(),# 非线性激活函数
nn.Linear(1024, 512),
nn.ReLU(),
nn.Linear(512, 11)
)
def forward(self, x):
out = self.cnn(x)
out = out.view(out.size()[0], -1) #将多维的的数据如(none,36,2,2)平铺为一维如(none,144)
return self.fc(out)
batch_size = 64
_dataset_dir = "../input/ml2022spring-hw3b/food11"
# 构建数据集。
# 参数“loader”说明torchvision如何读取数据。
train_set = FoodDataset(os.path.join(_dataset_dir,"training"), tfm=train_tfm)
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True)
valid_set = FoodDataset(os.path.join(_dataset_dir,"validation"), tfm=test_tfm)
valid_loader = DataLoader(valid_set, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True)
# "cuda" 仅当GPU可用时。
device = "cuda" if torch.cuda.is_available() else "cpu"
# 训练次数epochs和耐心patience。
n_epochs = 4
patience = 300 # 如果'patience' epochs没有改善,尽早停止
# 初始化一个模型,并把它放在指定的设备上。
model = Classifier().to(device)
# 对于分类任务,我们使用交叉熵作为性能的度量。
criterion = nn.CrossEntropyLoss()
# 初始化优化器optimizer,你可以自己微调一些超参数,如学习率。
optimizer = torch.optim.Adam(model.parameters(), lr=0.0003, weight_decay=1e-5)
# 初始化跟踪器trackers,这些不是参数,不应更改
stale = 0
best_acc = 0
for epoch in range(n_epochs):
# ---------- Training ----------
# 确保模型在训练前处于训练模式。
model.train()
# 这些用于记录训练中的信息。
train_loss = []
train_accs = []
for batch in tqdm(train_loader):
# 一个batch包括图像数据和相应的标签。
imgs, labels = batch
#imgs = imgs.half()
#print(imgs.shape,labels.shape)
# 转发 Forward数据。(确保数据和模型在同一个设备上。)
logits = model(imgs.to(device))
# 计算交叉熵损失。如上
# 我们不需要在计算交叉熵之前应用softmax,因为它是自动完成的。
loss = criterion(logits, labels.to(device))
# 应首先清除前一步骤中存储在参数中的梯度。
optimizer.zero_grad()# 梯度清零
# 如果没有进行tensor.backward()的话,梯度值将会是None
# 反向传播计算得到每个参数的梯度值gradients。
loss.backward()
# 修剪稳定训练的梯度标准。
grad_norm = nn.utils.clip_grad_norm_(model.parameters(), max_norm=10)
# 梯度下降执行一步参数更新。
optimizer.step()
# 计算当前批次batch的准确度。
acc = (logits.argmax(dim=-1) == labels.to(device)).float().mean()
# 记录损耗和准确度 loss and accuracy。
train_loss.append(loss.item())# loss.item()取出 单元素张量 的元素值并返回该值,保持原元素类型不变。一般运用在 神经网络 中用 loss.item()取loss值。
train_accs.append(acc)
train_loss = sum(train_loss) / len(train_loss)
train_acc = sum(train_accs) / len(train_accs)
# 打印信息。
print(f"[ Train | {epoch + 1:03d}/{n_epochs:03d} ] loss = {train_loss:.5f}, acc = {train_acc:.5f}")
# ---------- Validation ----------
# Make sure the model is in eval mode so that some modules like dropout are disabled and work normally.
model.eval()
# 这些用于记录验证中的信息。
valid_loss = []
valid_accs = []
# 分批batch迭代验证集。
for batch in tqdm(valid_loader):
# A batch consists of image data and corresponding labels.
imgs, labels = batch
#imgs = imgs.half()
# We don't need gradient in validation.
# Using torch.no_grad() accelerates the forward process.
with torch.no_grad():
logits = model(imgs.to(device))
# We can still compute the loss (but not the gradient).
loss = criterion(logits, labels.to(device))
# Compute the accuracy for current batch.
acc = (logits.argmax(dim=-1) == labels.to(device)).float().mean()
# Record the loss and accuracy.
valid_loss.append(loss.item())
valid_accs.append(acc)
#break
# 整个验证集的平均损失和准确度是记录值的平均值。
valid_loss = sum(valid_loss) / len(valid_loss)
valid_acc = sum(valid_accs) / len(valid_accs)
# Print the information.
print(f"[ Valid | {epoch + 1:03d}/{n_epochs:03d} ] loss = {valid_loss:.5f}, acc = {valid_acc:.5f}")
# 更新日志
if valid_acc > best_acc:
with open(f"./{_exp_name}_log.txt","a"):
print(f"[ Valid | {epoch + 1:03d}/{n_epochs:03d} ] loss = {valid_loss:.5f}, acc = {valid_acc:.5f} -> best")
else:
with open(f"./{_exp_name}_log.txt","a"):
print(f"[ Valid | {epoch + 1:03d}/{n_epochs:03d} ] loss = {valid_loss:.5f}, acc = {valid_acc:.5f}")
# 保存模型
if valid_acc > best_acc:
print(f"Best model found at epoch {epoch}, saving model")
torch.save(model.state_dict(), f"{_exp_name}_best.ckpt") #只保存最好的,以防止输出内存超出错误
best_acc = valid_acc
stale = 0
else:
stale += 1
if stale > patience:
print(f"No improvment {patience} consecutive epochs, early stopping")
break
test_set = FoodDataset(os.path.join(_dataset_dir,"test"), tfm=test_tfm)
test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=False, num_workers=0, pin_memory=True)
#测试并生成预测CSV
model_best = Classifier().to(device)
model_best.load_state_dict(torch.load(f"{_exp_name}_best.ckpt"))
model_best.eval()
prediction = []
with torch.no_grad():
for data,_ in test_loader:
test_pred = model_best(data.to(device))
test_label = np.argmax(test_pred.cpu().data.numpy(), axis=1)
prediction += test_label.squeeze().tolist() #.squeeze()去掉维度为1
#创建测试 csv
def pad4(i):
return "0"*(4-len(str(i)))+str(i)
df = pd.DataFrame()
df["Id"] = [pad4(i) for i in range(1,len(test_set)+1)]
df["Category"] = prediction
df.to_csv("submission.csv",index = False)
一、numpy
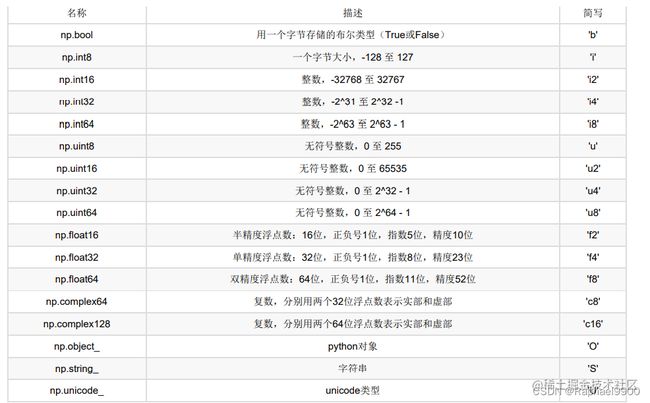
a = np.array([[1, 2, 3],[4, 5, 6]], dtype=np.float32)
a.dtype
#dtype(‘float32’)
ones = np.ones([4,8]) #生成0数组
zero=np.zeros((2,3))#生成1数组
a1=np.array([[1,2,3],[4,5,6]])
a2=np.array(a)#拷贝
a3=np.arrange(10,50,2) #创建等差数组,默认步长1
a4=np.random.normal(loc=0.0, scale=1.0, size=None) # 创建正态分布
loc:float此概率分布的均值(对应着整个分布的中心centre)
scale:float 此概率分布的标准差(对应于分布的宽度,scale越大越矮胖,scale越小,越瘦高)
size:int or tuple of ints 输出的shape,默认为None,只输出一个值
np.random.standard_normal(size=None) 返回指定形状的标准正态分布的数组。
a3.shape#返回形状
a3.T#求转置
np.reshape(shape)#形状修改
np.where(temp > 60, 1, 0)#三元运算
np.dot(A,B)#矩阵相乘
np.linalg.inv(a)#求逆矩
#求伴随
det_a=np.linalg.det(a)
ni=det_a*np.linalg.inv(a)
二、torch的基本功能
torch.nn:包含搭建网络层的模块(modules)和一系列的loss函数。eg.全连接、卷积、池化、BN分批处理、dropout、CrossEntropyLoss、MSLoss等。
torch.autograd:提供Tensor所有操作的自动求导方法。
torch.nn.functional:常用的激活函数relu、leaky_relu、sigmoid等。
torch.optim:各种参数优化方法,例如SGD、AdaGrad、RMSProp、Adam等。
torch.nn.init:可以用它更改nn.Module的默认参数初始化方式。
torch.utils.data:用于加载数据。
Torchvision基本功能
torchvision.datasets:常用数据集,MNIST、COCO、CIFAR10等。
torchvision.models:常用模型AlextNet、VGG、ResNet、DenseNet等。
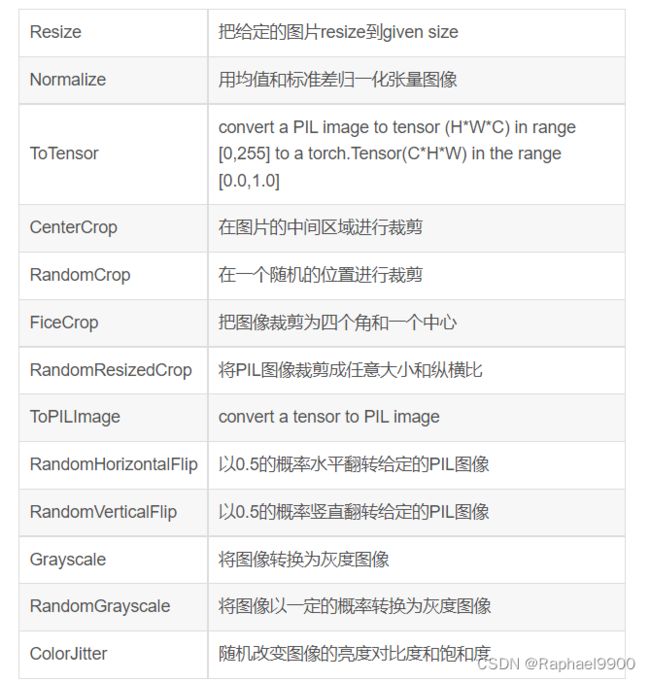
torchvision.transforms:图片相关处理。裁剪、尺寸缩放、归一化等。
torchvision.utils:将给定的Tensor保存成image文件。
三、PIL
pip install pillow # 安装Pillow
# 导入
import PIL
from PIL import Image
#打开本地图片
# coding=utf-8
from PIL import Image
image = Image.open("yazi.jpg")
image.show()
#创建一张新图片
from PIL import Image
image = Image.new('RGB', (160, 90), (0, 0, 255)) #new(mode, size, color=0)
image.show()
from PIL import Image
image = Image.open("yazi.jpg")
print('width: ', image.width)
print('height: ', image.height)
print('size: ', image.size)
print('mode: ', image.mode)
print('format: ', image.format)
print('category: ', image.category)
print('readonly: ', image.readonly)
print('info: ', image.info)
#图片的模式转换
image = Image.open("yazi.jpg")
print(image.mode)
image1 = image.convert('1')

四、torch.backends.cudnn.benchmark
torch.backends.cudnn.benchmark 这个 GPU 相关的 flag,可能有人会感到比较陌生。在一般场景下,只要简单地在 PyTorch 程序开头将其值设置为 True,就可以大大提升卷积神经网络的运行速度。既然如此神奇,为什么 PyTorch 不将其默认设置为 True?设置 torch.backends.cudnn.benchmark=True 将会让程序在开始时花费一点额外时间,为整个网络的每个卷积层搜索最适合它的卷积实现算法,进而实现网络的加速。适用场景是网络结构固定(不是动态变化的),网络的输入形状(包括 batch size,图片大小,输入的通道)是不变的,其实也就是一般情况下都比较适用。反之,如果卷积层的设置一直变化,将会导致程序不停地做优化,反而会耗费更多的时间。在说 torch.backends.cudnn.benchmark 之前,我们首先简单介绍一下 cuDNN。cuDNN 是英伟达专门为深度神经网络所开发出来的 GPU 加速库,针对卷积、池化等等常见操作做了非常多的底层优化,比一般的 GPU 程序要快很多。大多数主流深度学习框架都支持 cuDNN,PyTorch 自然也不例外。在使用 GPU 的时候,PyTorch 会默认使用 cuDNN 加速。但是,在使用 cuDNN 的时候,torch.backends.cudnn.benchmark 模式是为 False。所以就意味着,我们的程序有可能还可以继续提速!说了这么多背景知识,但和 cudnn.benchmark 有何联系呢?实际上,设置这个 flag 为 True,我们就可以在 PyTorch 中对模型里的卷积层进行预先的优化,也就是在每一个卷积层中测试 cuDNN 提供的所有卷积实现算法,然后选择最快的那个。这样在模型启动的时候,只要额外多花一点点预处理时间,就可以较大幅度地减少训练时间。
到底哪些因素会影响到卷积层的运行时间。
1、首先,当然是卷积层本身的参数,常见的包括卷积核大小,stride,dilation,padding 等;
2、其次,是输入的相关参数,包括输入的宽和高,输入通道的个数,输出通道的个数等;
3、最后,还有一些其他的因素,比如硬件平台,输入输出精度、布局等等。
五、transforms
六、nn.Conv2d

七、MaxPool2d
kernel_size :表示做最大池化的窗口大小,可以是单个值,也可以是tuple元组。这里的 kernel_size 跟卷积核不是一个东西。 kernel_size 可以看做是一个滑动窗口,这个窗口的大小由自己指定,如果输入是单个值,例如 3 33 ,那么窗口的大小就是 3 × 3 3 \times 33×3 ,还可以输入元组,例如 (3, 2) ,那么窗口大小就是 3 × 2 3 \times 23×2 。最大池化的方法就是取这个窗口覆盖元素中的最大值。
stride :步长,可以是单个值,也可以是tuple元组。上一个参数我们确定了滑动窗口的大小,现在我们来确定这个窗口如何进行滑动。如果不指定这个参数,那么默认步长跟最大池化窗口大小一致。如果指定了参数,那么将按照我们指定的参数进行滑动。例如 stride=(2,3) , 那么窗口将每次向右滑动三个元素位置,或者向下滑动两个元素位置。
padding :填充,可以是单个值,也可以是tuple元组。这参数控制如何进行填充,填充值默认为0。如果是单个值,例如 1,那么将在周围填充一圈0。还可以用元组指定如何填充,例如 p a d d i n g = ( 2 , 1 ) padding=(2, 1)padding=(2,1) ,表示在上下两个方向个填充两行0,在左右两个方向各填充一列0。
dilation :控制窗口中元素步幅
return_indices :布尔类型,返回最大值位置索引
ceil_mode :布尔类型,为True,用向上取整的方法,计算输出形状;默认是向下取整。
八、BatchNorm2d
torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True, device=None, dtype=None)
功能:对输入的四维数组进行批量标准化处理,具体计算公式如下:
![]()
![]()
对于所有的batch中样本的同一个channel的数据元素进行标准化处理,即如果有C个通道,无论batch中有多少个样本,都会在通道维度上进行标准化处理,一共进行C次。
输入参数:
num_features:输入图像的通道数量-C。
eps:稳定系数,防止分母出现0。
momentum:BatchNorm2d里面存储均值(running_mean)和方差(running_var)更新时的参数。
![]()
xold为BatchNorm2d里面的均值(running_mean)和方差(running_var),xobser为当前观测值(样本)的均值或方差,xnew为更新后的均值或方差(最后需要重新存储到BatchNorm2d中),momentum为更新参数。
affine:代表gamma,beta是否可学。如果设为True,代表两个参数是通过学习得到的;如果设为False,代表两个参数是固定值,默认情况下,gamma是1,beta是0。
track_running_stats:BatchNorm2d中存储的的均值和方差是否需要更新,若为True,表示需要更新;反之不需要更新。更新公式参考momentum参数介绍 。
目标有两个:
在训练阶段和测试阶段:样本如何标准化处理。
在训练阶段和测试阶段:模型BatchNorm2d中自身存储的均值(running_mean)和方差(running_var)如何更新。
九、torch.nn.Linear
torch.nn.Linear 类用于定义模型的线性层,即完成前面提到的不同的层之间的线性变换。
torch.nn.Linear 类接收的参数有三个,分别是输入特征数、输出特征数和是否使用偏置,设置是否使用偏置的参数是一个布尔值,默认为 True ,即使用偏置。
在实际使用的过程中,我们只需将输入的特征数和输出的特征数传递给 torch.nn.Linear 类,就会自动生成对应维度的权重参数和偏置,对于生成的权重参数和偏置,我们的模型默认使用了一种比之前的简单随机方式更好的参数初始化方法。
根据我们搭建模型的输入、输出和层次结构需求,它的输入是在一个批次中包含 100 个特征数为 1000 的数据,最后得到 100 个特征数为 10 的输出数据,中间需要经过两次线性变换,所以要使用两个线性层,两个线性层的代码分别是
torch.nn.Linear(input_data,hidden_layer)
torch.nn.Linear(hidden_layer, output_data)
可看到,其代替了之前使用矩阵乘法方式的实现,代码更精炼、简洁。
十、torch.optim.Adam
为了使用torch.optim,需先构造一个优化器对象Optimizer,用来保存当前的状态,并能够根据计算得到的梯度来更新参数。
lr 是Adam算法里面的α,代表学习率。
betas ,一个元组(tuple)是Adam算法里面的β1和β2,代表历史积累动量在新求的动量里面的权重比。
eps,是Adam算法里面的e,避免分母为零用的,不会影响结果的小tip。
weight_decay,就是第12行里面的入,就是weight参数的衰减因子,因为和都大于0,每次update weight参数。
那么为什么要抑制weight参数不要变得过大呢?
从模型的复杂度上解释:更小的权值w,从某种意义上说,表示网络的复杂度更低,对数据的拟合更好(这个法则也叫做奥卡姆剃刀)
其实控制weight参数在一个值范围内,也在一定程度上减小了function set的选择范围,不会让我们选择一个过于偏冷复杂的function如下图,训练时我们选择简单的黑线就挺好,不必找到最合适但很复杂的绿线。
