Trilevel Neural Architecture Search for Efficient Single Image Super-Resolution
Trilevel Neural Architecture Search for Efficient Single Image Super-Resolution
高效单幅图像超分辨率的三层神经架构搜索

摘要
使用深度神经网络的单图像超分辨率(SISR)问题的现代解决方案不仅以更好的性能精度为目标,而且以更轻且计算效率高的模型为目标。为此,最近,神经架构搜索(NAS)方法显示出一些巨大的潜力。遵循相同的基础,在本文中,我们提出了一种新的三层NAS方法,该方法在不同的效率指标和性能之间提供了更好的平衡,以解决SISR问题。与现有的NAS不同,我们的搜索更加完整,因此它带来了一个高效、优化和压缩的体系结构。我们创新性地引入了三层搜索空间建模,即网络、细胞和内核级结构的分层建模。为了使在三层空间上的搜索可微且有效,我们开发了一种新的稀疏最大化技术,该技术在生成单个神经架构候选的稀疏分布方面非常出色,使得它们可以更好地从扩大的搜索空间中被分离出来用于最终选择。为了更好的网络级压缩,我们进一步将排序技术引入到稀疏最大松弛中。建议的NAS优化还可以在单个阶段同时进行搜索和训练,从而减少搜索时间和训练时间。对基准数据集的综合评估表明,我们的方法在模型大小、性能和效率之间取得了良好的平衡,明显优于最先进的NAS。
一:引言
单图像超分辨率(SISR)旨在将单个低分辨率图像上采样到其高分辨率描述。众所周知,图像随机共振是一个不适定的问题,最近出现了许多基于深度学习的方法来解决它[6,13,31,5,30,19,15,16]。尽管基于学习的方法获得了良好的性能,但计算和内存需求极大地影响了其在设备上的使用。受此启发,我们的论文重点研究用神经架构搜索的方法学习高效SISR。我们的方法旨在保持峰值信噪比(PSNR)、每秒浮点运算(FLOPS)、参数大小、使用的GPU数量和神经架构的搜索时间之间的良好性能效率平衡。
如图1所示,已经出现了一些基于NAS的高效SISR方法。一般来说,它们旨在搜索以下三级神经体系结构中的一个或两个,即(I)网络级优化,以正确定位上采样层[20,12]。(二)细胞水平优化,以提高编码或放大能力[21,4]。(iii)内核级优化,针对压缩模型18,7,在操作员的能力和宽度(即输入/输出通道的数量)之间进行权衡。特别是,AutoGAN-Distiller (AGD) [7]开发了一种可区分的NAS方法来搜索细胞和内核级别的最佳架构。由于这种方法忽略了网络级的压缩,所学习的神经体系结构仍然具有大的模型尺寸和慢的FLOPS。AutoDeepLab [20]提出了一种可区分的NAS算法来寻求有效的网络和单元级架构。缺少内核级搜索使得该方法仍然受到模型压缩不理想的困扰和FLOPS减少。相比之下,微小感知SR (TPSR)方法[16]利用基于强化学习(RL)的NAS方法来搜索最佳细胞级架构,从而最终发现微小SR架构。像大多数基于RL的NAS算法一样,TPSR的成功需要过高的搜索成本:40个NVIDIA GeForce GTX1080 Ti服务器GPU,12天的搜索时间。

图1:根据我们关注的五个指标:逆PSNR、FLOPS、参数大小、使用的GPU数量和搜索时间,建议的TrilevelNAS和三种最先进的基于NAS的SR方法,即AutoGAN-Distiller (AGD) [7]、AutoDeepLab [20]和微小感知SR (TPSR) [16]的雷达图(覆盖区域越小,方法越好)。最小的覆盖区域表明,我们的TrilevelNAS方法明显比其他方法工作得更好(即,在五个指标之间保持最佳平衡)。

为了克服上述缺点,本文引入了一种新的三层NAS算法。我们的方法利用设备上的计算资源有效地解决了SR问题1,并给出了与最佳可用方法相当的性能精度(见图1)。它自动化了整个三层神经架构的设计优化,并且没有明确地使用基础事实的例子进行监督。为此,我们首先定义不同层次的离散搜索空间及其建模如下。
(a)搜索空间。我们在三个不同的层次上定义搜索空间(见图2)。网络级搜索空间由所有候选网络路径组成。单元级搜索空间包含所有可能的候选操作的混合。最后,核级搜索空间是具有卷积核维数3的定义子集的单个卷积核。
(b) 搜索空间的建模。我们对定义的离散搜索空间进行连续松弛,以便以可微的方式有效地进行优化。我们遵循可微体系结构搜索(DARTS)[21]和AGD[7]分别使用超单元和超内核对单元级和内核级搜索空间进行建模。然而,它们都忽略了网络级搜索空间的建模,这对于网络级优化和压缩至关重要。一种方法是采用AutoDeepLab[20]图3(a)中的网格状超网建模。在网格超网中,任何可能路径的信息流都是高度纠缠的,因此导出的路径和单元结构可能不是最优的。此外,我们还可以从中获得固定的网络路径长度。为了克服这些问题,我们引入了一种类似树的超网,其中路径是独立枚举的,因此,一旦路径对超网做出了合理的贡献,就可以更容易地进行修剪(见图3(b))。直观地,我们可以从图3中观察到,我们的树状超网解开了顺序网络路径依赖性,并在内存消耗、跨层单元共享和搜索时间之间提供了更好的权衡 。

图3:(a)2个残差内残差(RiR)块和2个上采样块上的网格超网建模[20]。垂直轴和水平轴分别显示上采样比例和层数。每个中间要素图(蓝色)有两条路径要遍历:水平(RiR块)和垂直(×2上采样层)。从节点起点到终点的可行路径遍历。(b) 建议的树超网建模具有2个RiR和2个上采样层。与网格一样,每个中间要素贴图有2条路径。但是,每个路径都是独立的,不合并。任何从根开始的路径都是可行的路径。
对于搜索空间的连续松弛,可微NAS方法通常使用softmax[21]。但是,softmax可能不会为最佳架构设计的选择提供明确的主导操作。因此,我们利用SparseTmax策略[26]来持续松弛单元级搜索空间。sparsestmax生成稀疏分布并保留softmax的重要属性(例如,可微性和凸性)。对于网络级搜索空间,我们利用排序的稀疏度最大值,其中网络级路径稀疏度按降序排列。建议的排序稀疏最大值有助于修剪网络路径的尾部,以实现显著的模型压缩。我们提出将SparseTmax及其变体用于网络级建模,这为新的NAS培训方案提供了支持。使用它,我们可以从搜索而不是像大多数NAS算法那样从头开始进行训练。
为了评估和比较我们的方法,我们使用了标准Set5[1]、Set14[32]和AIM 2020 SR数据集[34]。在本文中,我们做出以下贡献:
为了实现更完整的神经结构优化和压缩,我们提出了一种新的三层NAS算法,用于同时搜索网络级、细胞级和核级神经结构,这在NAS文献中很少研究为了使三层空间上的搜索可微且高效,我们开发了一种新的松弛技术,该技术能够在候选神经结构之间产生更好的解纠缠。此外,它还支持网络级压缩以及搜索和训练阶段之间的连续合并与最先进的方法相比,我们的方法在Set5、Set14和AIM 2020数据集的性能和效率之间取得了良好的平衡,在真实世界SR任务的培训过程中不使用地面真实数据。
二:相关工作
最近出现了许多基于一级和两级NAS核心的SISR问题解决方案。为了更好地理解,我们对它们进行了相应的讨论。
(One-level NAS methods.)一级NAS方法。进化算法(如[24,25])和基于强化学习的NAS方法(如[35,36,16])将输入/输出通道号引入其搜索空间进行优化。Zhang等人[33]提出了一种可微宽度级架构搜索方法。他们的目标是通过在每一层保持相同的内核宽度、一半的内核宽度和两倍的内核宽度来选择最优策略。最近,Lee等人[16]提出了一种小型SR方法,该方法集成了基于强化学习的NAS和GANs,但需要大量计算资源和搜索时间。另一个变体是Liu等人[21]的DART,它使用有向无环图(DAG)对网络的基本单元进行建模。它通过对每条边上所有候选操作的softmax组合,将给定的离散搜索空间松弛为连续搜索空间,构成一个超网。这种松弛使得超网的可微优化成为可能。虽然有效,但它也存在一些问题,例如:超级网与独立体系结构之间的差距过大[3],skipconnections的聚合[4]和内存消耗过大[2]。
(Bi-level NAS methods.)双级NAS方法。Stamoulis等人[28]将候选单元级操作和内核级扩展编码为一次NAS超级网每一层的单个超级内核。它们将NAS问题简化为在每个ConvNet层中查找内核权重的子集。Fu等人提出AGD[7]通过NAS压缩GAN基SR发生器。AGD不是从头开始搜索GAN架构[10,9],而是利用预先训练的SR模型中的知识,通过DART搜索每个单元的最佳操作(称为单元级架构搜索)并修剪每个操作的输入/输出通道(即内核级架构搜索)[21]。
AGD忽略了网络级搜索,并将上采样操作固定在网络头部分。虽然后上采样网络设计是有效的,但缺乏网络级优化可能会限制其性能。相反,Auto DeepLab[20]提出了网络级搜索和单元级搜索,形成了一个分层结构的搜索空间。具体地说,它使用一个类似网格的超网对网络级搜索进行建模,其中节点表示中间特征映射,节点之间的箭头表示相应的单元。网格状设计允许该方法探索一般网络级搜索空间。类似地,Guo等人[12]将分层NAS思想用于SR问题。显著的区别在于,它利用强化学习进行单元级和网络级架构设计。但是,该方法并不针对核宽度修剪。此外,基于强化学习的NAS的使用增加了实际挑战。
在本文的剩余部分,我们首先解释我们的三层搜索空间,然后对其进行连续建模和优化,最后给出实验结果。
三:三层搜索空间及其建模
我们建议在内核级、单元级和网络级结构上进行搜索。我们提出了一种新的网络级搜索空间策略,其中所有候选网络路径都以树结构枚举。对于单元级和内核级搜索,我们利用了DART[21]和AGD[7]。
网络级搜索空间。在AGD[7]和SRResNet[14]之后,我们定义了我们的网络级搜索空间。这是因为他们的超网为了提高计算效率,在低分辨率特征空间中进行了大部分计算。通过固定网络的干(第一个卷积层)和头(最后一个卷积层),我们搜索剩余的五个剩余剩余剩余(RiR)块和两个上采样块的路径。我们将RiR模块中的密集块替换为包含可搜索单元级运算符和内核级宽度的五个连续层(参见图4(A)中的TrilevelNAS-A)。为了高效的上采样块设计,我们将两个上采样块[7]替换为一个PixelShuffel块,其中包含一个卷积层(输出通道号为n×n×3)[34],以及一个PixelShuffel层,以达到目标分辨率,放大因子为n。由于PixelShuffle块固定在网络的尾部,我们将两个常规卷积层添加到网络级搜索空间中,以仅关注堆叠的5个RiR块和2个标准卷积层,用于网络路径搜索(参见图4(B)中的TrilevelNAS-B)。
网络级搜索空间建模。我们避免使用类似网格的结构来建模网络级搜索空间,因为网格建模的目的是遍历所有网络块的顺序路径。如图3所示,每条路径从第一个节点开始,沿着一组箭头到达目标。显然,所有路径共享大部分节点和箭头。这导致网络路径、单元和内核之间存在许多冗余共享。虽然架构共享策略节省了训练内存,但它极大地限制了搜索空间。此外,紧密纠缠可能会影响对每条路径的贡献的学习和对不必要路径的修剪。因此,我们提出了一种树结构的灵活的网络级路径搜索建模。如图3所示,每个节点仅连接到其父节点(如果适用)和子节点;因此,依赖关系非常轻松。尽管如此,我们必须在训练时保持关联,以降低内存消耗。放松不同路径之间的关联可以实现灵活的网络级搜索空间。对路径依赖性较低可能导致单元和内核之间的可靠关联,因为它们具有层次结构。此外,引入的树模型能够更好地分离路径,允许我们对冗余路径执行修剪。此外,它还支持在候选路径对超级网有贡献时删除它们。
单元级和内核级搜索空间。为了在单元级和内核级定义搜索空间,我们遵循AGD工作[7]。在单元级别,我们搜索五个RiR块,每个块包含五个可搜索单元,即总共25个可搜索单元。对于每个单元格,我们选择以下候选操作之一:
• (i) Conv 1×1, (ii) Residual Block (2 layers of Conv 3×3 with a skip-connection), (iii) Conv 3×3, (iv) Depthwise Block (Conv 1×1 + Depthwise Conv3×3 + Conv 1×1).
单元级和内核级搜索空间建模。对于单元级搜索空间建模,我们遵循DARTS单元建模过程。为了对内核级搜索空间建模,我们遵循AGD[7]超内核框架。对于每个卷积核,我们设置了一个具有完整通道的超核。为了修剪超核的通道数,定义了一组可搜索的扩展比φ=[1/3,1/2,4/5,5/6,1],并优化了表示选择第i个扩展比的概率的参数γi。
四:提出的办法
我们的方法的关键思想是将离散三层搜索空间的显式选择放宽为隐式选择,从搜索空间中所有相关候选对象的分层混合。连续松弛使我们能够以完全可微的方式选择对超网贡献最大的候选。为此,我们提出SparseTmax及其变体来执行定义搜索空间的连续松弛。我们的建模策略可以提供很好的稀疏性,并且可以在保持softmax的凸性和可微性的同时寻找占优势的候选体系结构。
为了更好地进行路径修剪,我们在网络级引入了一种新的稀疏最大排序约束。排序约束使候选路径具有较重的头部(即,对路径的贡献较大)和较轻的尾部(即,对路径的贡献较小),因此尾部可以很容易地移除。因此,当所有候选网络的混合上都有有序的SparseTmax时,我们的超网通常会收敛到一个合理的稀疏网络。作为一个好处,直接选择SparseTmax激活给出的候选体系结构来设计最佳体系结构。搜索的体系结构和经过训练的体系结构之间的差异大大减少,使我们能够从搜索阶段学习的参数开始训练网络,而不是从头开始。
具有排序稀疏最大值的Supernet建模。在我们介绍的网络主干§3中,由于上采样层在网络级搜索空间之外,树模型中的每个特征映射(即节点)都可以用作其相应路径的输出。然后,可以将输出馈入上采样层以获得所需的分辨率。因此,所有路径上的聚合被简化为所有相关特征映射上的融合。特别是,我们基于我们建议的树模型(图3),为涉及的网络路径的所有特征映射定义了一组贡献权重β。因此,超级网的输出是所有中间特征映射的加权组合。给定网络级搜索空间的树模型,其中N条路径为P={P1,…,PN},其中Pi具有Mi特征映射,整个超网的输出(即所有候选路径的混合)定义为:

其中,fi,j是Pi的第j层的特征映射,FN(βi,j;β)表示特征映射fi,j上的归一化组合权重。如前所述,我们不应用softmax(β),而是使用如下的sparsestmax[27]来归一化组合权重,这使得候选对混合的贡献稀疏,

∆K−1r:={q∈ RK | 1T q=1,kq− uk2≥ r、 q≥ 0}表示具有循环约束1T q=1,kq的单纯形− uk2≥ r、 u=1K1是单纯形的中心,1是1的向量,r是圆的半径。Sparsestmax返回输入向量β在概率单纯形上的欧几里德投影。该投影可能会触及单纯形边界,在这种情况下,SparseTmax产生稀疏分布。为了获得更好的稀疏性,SparseTmax进一步引入了一个循环约束,该约束通过将r从零线性增加到rc来逐步产生稀疏性,其中rc是单纯形的外接圆半径。有关SparseTmax优于softmax和sparsemax的详细评估[22,23],请读者参考邵等人的工作[27]。
虽然sparsestmax提供稀疏分布,但它与我们的顺序设置不一致。给定由Mi节点(即特征映射)组成的路径Pi,SparseTmax在节点上产生无序的非零组合权重(极端情况是所有节点都分布在奇偶节点)。在这种情况下,除非稀疏性是有序的,否则我们不能很好地修剪路径。我们可以执行网络级修剪,前提是非零组合权重沿路径递减,以便所有零权重出现在路径的尾部。因此,我们利用了排序的SparseTmax,它对每个路径Pi内的权重βi施加了排序约束。它有助于较浅层的输出特征映射共享对超级网的更多贡献。我们将排序的sparsestmax表示为

超单元和超内核建模。由于单元级网络没有序列性质,我们直接应用SparseTmax将离散搜索空间松弛为连续搜索空间。我们定义了一组操作的贡献权重α,使得输出是所有候选操作的归一化加权组合。第i个单元格Ci的输出是来自4个候选操作的4个特征映射的加权和,即。,

其中FN对应于SparseTmax,o(Ci−1) 是否从Ci上的单元级空间O中选择一个操作Ci−1.
对于核级搜索空间的连续松弛,一种解决方案是应用sparsestmax组合所有相关的核展开。然而,由于内核的数量巨大,它可能导致指数级的组合。因此,我们坚持采用可微Gumbel softmax采样,以保持设置与AGD一致[7]。对于膨胀比参数γ的优化,我们采用基于AGD[7]抽样的策略。主要是在优化的每个步骤中,我们只对一个基于γ的扩展比进行采样,并使用选定的子核对模型进行训练。在这里,我们引入Gumbelsoftmax[11]来近似采样过程。借助可微Gumbel softmax,可以在可微框架内优化比率参数γ。
代理任务和优化。对于我们的三层NAS任务,我们不是从头开始训练模型,而是通过知识提炼利用预先训练的最先进的图像SR模型中的知识[7]。具体地说,我们采用ESRGAN[31]的预训练生成器作为我们的教师模型。因此,搜索阶段的代理任务旨在通过最小化模型G和教师模型G0的输出之间的知识提取距离d来搜索模型G。此外,一个有效的模型总是有利于图像SR任务,所以我们考虑在我们的目标中涉及模型效率项H。拟议三层结构的培训目标如下:

这里α,β,γ是三层结构搜索空间的连续松弛参数,d(G,G0)是 图像SR任务的距离,H是基于搜索架构的计算预算约束。根据AGD[7],我们结合内容损失Lc(避免颜色偏移)、感知损失Lp(保留视觉和语义细节)计算d(G,G0),并使用模型触发器作为模型效率的度量。

我们的连续松弛能够优化G的网络参数,以及所有超网结构权重α、β、γ。由于架构参数的数量远小于网络参数的数量,因此在单个训练集上联合优化它们可能会过拟合。因此,我们在双层优化框架下交替优化网络权重和结构参数[21]。我们将数据集分为训练集和验证集,其中网络权重和架构参数分别在这两组独立的数据集上进行优化。此外,由于聚合体系结构和最终选择的体系结构由于稀疏的基于tmax的超网松弛而接近,因此我们选择新的NAS训练方案(即搜索训练),而不是传统培训计划(即从头开始的培训)。算法(1)中提供了我们实现的伪代码。

表1:比例因子为4的可视化SR模型的定量结果。对于列出的路径结果,我们使用“0”表示RiR块,“1”分别是TrilevelNAS-a/TrilevelNAS-B中的上采样块/Conv层。†通过正式设置和实施复制AGD。统计数据清楚地表明,我们的方法可以提供更轻的模型和可管理的计算资源,其PSNR性能优于最佳方法。因此,结合所有评估指标,所提出的方法具有更好的性能。

表2:比例因子为4的面向峰值信噪比的SR模型的定量结果。对于列出的路径结果,我们使用“0”表示RiR块,“1”表示UpConv层。此处,以下符号表示*为面向PSNR的×4 SR任务复制的HNA,———通过AGD官方设置和实施复制,†从面向可视化的模型转移。显然,结合所有评估指标,我们的方法性能更好。
五:实验
我们对DIV2K和Flickr2K数据集进行了搜索和培训[29]。此外,我们在流行的基准测试(包括Set5[1]、Set14[32]和DIV2K有效集)上评估了搜索到的体系结构。我们使用PSNR作为报告结果的定量指标。此外,我们还记录了模型大小和FLOPS(在256×256图像上计算)作为模型效率的量化指标。我们使用两种主干实现了网络级搜索:(i)TrilevelNAS-A:与AGD[7]类似,我们搜索5个可搜索RiR块和2个上采样块的灵活路径(见图4(A));(ii)TrilevelNAS-B:为了更有效的SR模型,我们用单个像素混合块替换2个上采样层,并搜索5个RiR块和2个卷积层的路径(见图4(B))。
培训细节。在可区分的NAS框架中,优化过程通常包括三个步骤:搜索、模型离散化和从头开始训练。相比之下,由于sparsestmax的渐进稀疏性,我们提出了一种不需要离散化步骤的搜索框架,这有助于减少supernet和离散化体系结构之间的模型差异。
搜索:在AGD[7]之后,我们拆分了搜索过程 分为两个阶段:列车前阶段和搜索阶段。正如[7]所做的那样,在预训练阶段,我们使用一半的训练数据来更新100个时段的网络权重,而仅使用内容丢失Lc。然后在搜索阶段,我们在两个等分的训练数据上交替更新100个历元的网络权重和体系结构权重。在这个搜索阶段,对于面向PSNR的模型搜索,我们只使用内容损失Lc进行优化,而对于面向可视化的模型搜索,我们使用感知损失进行微调,以获得更好的视觉质量 。

图4:(a)具有5个RiR块和2个上采样层的图像SR supernet主干三层NAS-a。(b) Image SR supernet主干三层NAS-b,带有5个RiR块和一个像素混洗层。
从搜索训练(Train from Search):如前所述,我们不需要完全收敛超网的模型离散化步骤在整个搜索过程之后。因此,我们可以从搜索阶段继承预先训练好的网络权重作为良好的网络初始化,并继续训练融合体系结构。按照AGD[7]中的相同训练过程,对于面向PSNR的SR模型,我们仅使用内容丢失Lc训练900个历元。对于面向可视化的SR模型,我们继续对1800个时代进行精细调整,以减少感知损失Lp
面向可视化的SR模型搜索。我们采用ESRGAN[31]模型作为教师,寻找一个面向可视化的SR模型。我们将我们的方法与最先进的SR-GAN模型(ESRGAN[31]、修剪后的ESRGAN基线[17]和SRGAN[15])以及基于NAS的可视化导向SR模型(AGD[7]和TPSR[16])进行比较。请注意,我们使用AGD的官方代码和默认实验设置复制AGD搜索和培训结果。此外,与基于树超网的三层NAS相比,我们将AutoDeepLab的网格超网设计应用于AGD主干网,以实现图像SR任务的三层NAS。
表1显示了我们的方法与其他竞争方法的统计比较。我们还报告了导出的网络路径(“路径中的0”表示RiR块;“1”分别表示TrilevelNAS-A和TrilevelNAS-B中的上采样层和卷积层)。与基于AutoDeepLab的三层NAS(AGDAutoDeepLab)相比,我们的网格NAS可以修剪RiR块或卷积层,从而显著降低模型复杂性。在性能没有重大变化的情况下,TrelevelNAS-A删减了一个冗余RiR块,并衍生出一个更轻的模型,模型大小为0.34MB。即使型号更小,TrilevelNAS-A与AGD相比仍有相当的失败率。我们注意到,大多数触发器消耗来自在高维特征映射上操作的块。值得注意的是,我们新的主干TrilevelNAS-B(见图4(B))有潜力寻找模型尺寸小、GFLOP轻的灵活网络级路径。与原来的AGD和TrilevelNAS-A相比,TrilevelNAS-B的触发器消耗减少了4×。尽管TPSR采用了一种微型架构,但其搜索成本(TrilevelNAS搜索成本的60倍)非常昂贵,而且我们还看到这种微型模型的PSNR性能明显下降。此外,我们还比较了图5中各种SR模型的视觉质量,我们可以看到,我们的TrilevelNAS可以在视觉质量没有性能损失的情况下得出更有效的SR模型。
有关搜索和训练阶段的更详细实验设置,请参阅我们的补充材料。
面向PSNR的SR模型搜索。我们在DIV2K和Flickr2K数据集上实现了面向PSNR的SR模型搜索,并使用面向PSNR的ESRGAN模型作为我们的教师模型。在以前的实验中,我们观察到新主干(TrilevelNAS-B)比原始主干(TrilevelNAS-a)具有明显的FLOPs优势。在这里,我们将重点放在新主干上的三层搜索上,并致力于更高效的SR模型。在表2中,我们将我们的衍生模型与我们的竞争对手进行了比较。在性能相当的情况下,新主干上导出的面向PSNR的SR模型删减了卷积层,并且它在失败方面优于所有其他竞争对手。
此外,我们将我们的模型与获胜者和获胜者进行了比较 最近AIM挑战赛的亚军[34]。在挑战设置之后,我们分别使用800个DIV2K训练图像和100个有效图像3对我们的模型进行训练和验证。表3提供了我们的方法与竞争方法的定量结果,包括挑战冠军(NJU MCG)、亚军(AiriA CG)和基于NAS的SR模型。从统计数据可以推断,尽管我们的方法明显较轻,但PSNR值与竞争方法相当。

请注意,winner和runup方法使用额外的Flickr2K数据集进行训练,并获取地面真相HR图像以进行强有力的监督,这对于实际应用来说是不现实的。因此,我们坚持使用教师模型进行知识提炼。为此,我们遵循AGD,使用预训练的ESRGAN生成器进行监控。我们可以从表3中推断,TrilevelNAS模型更轻,可以提供与获胜方法相当的结果,这是移动设备所需要的。
消融研究。我们进行了消融研究,以比较SparseTmax和Softmax,并了解我们提出的分类SparseTmax的重要性。此外,我们还研究了从零开始训练和从搜索开始训练两种不同策略下的训练效果。
a) Softmax与Sparsestmax:我们分别研究了Softmax和Sparsestmax组合的超网优化问题,保持了相同的排序约束策略。从表4中,我们可以观察到,在权重排序约束下,softmax和sparsestmax可以修剪一个或两个RiR块,并且在峰值信噪比方面具有相当的性能。然而,SparseTmax收敛到一个更有效的模型,具有更小的模型尺寸和更少的触发器消耗。
b) 排序的SparseTmax:我们使用中间特征映射的排序的SparseTmax组合来鼓励一个浅层和高效的SR模型,而不会有太多性能损失。在等式3中,λ控制主约束和排序约束之间的权衡。大量ordering约束倾向于实施浅层网络。我们将λ分别设置为0、0.01和0.1,并检查其影响。表5显示了派生路径和相应的模型性能。我们看到,在没有权重排序约束(λ=0)的情况下,网格更喜欢具有5个RiR块和2个上采样块的完整网络路径。当我们施加λ=0.01,0.1的排序约束时,尾部RiR块被剪掉,从而产生更有效的SR模型,模型尺寸小,性能无损失。
c) 从搜索开始训练与从零开始训练:最后,我们研究了从搜索阶段继承权重的效果。图6分别显示了从搜索到训练和从零开始训练的有效PSNR演变。我们可以观察到从搜索阶段继承权重的明显优势。通过搜索策略的训练,我们可以在较少的时间内收敛到更好的PSNR性能。

六:结论
本文提出了一种新的三层NAS技术,该技术提供了更轻、更高效的SR体系结构和设备上的计算资源,与最先进的PSNR结果相比具有优势。建议的NAS探索了更完整的搜索空间,即网络级、单元级和内核级。通过引入所提出的三层搜索空间的连续松弛,我们对网络路径的分层混合进行了建模。我们不依赖于类似网格的网络建模,而是展示了使用SparseTmax和排序SparseTmax激活到NAS框架的树状超网建模的实用性。在我们建议的优化后获得的体系结构提供了更好的SISR结果——考虑到所有重要的评估指标,因此为竞争方法提供了更好的替代方案。
补充材料
在材料中,我们首先详细描述了主要论文中概述的三层NAS算法的编码实现,并提供了编码平台的细节,如实现中使用的硬件和软件。进行了一项关键的烧蚀研究并进行了讨论,以表明三层优化对具有稀疏最大约束的二层优化的重要性。此外,三层优化后获得的最佳架构的具体信息被制成表格。最后,我们提供了一些超分辨率图像的可视化结果,这表明了我们的方法的有效性。
A.实施细节
在本节中,我们将描述用于SR任务的三层NAS算法的实现细节。讨论了可视化搜索策略和面向峰值信噪比的教师模型,以及培训策略。代码是用Python 3.6和Pytorch 1.3.1开发的。在单个NVIDIA Tesla V100(16GB RAM)上完成搜索过程需要8 GPU天,面向PSNR和面向可视化的SR模型的培训分别需要0.5和1.5 GPU天。
A.1。搜索
我们使用DIV2K和Flickr2K数据集实现搜索阶段[29]。
(a) 面向可视化:在这里,我们将面向可视化的ESRGAN模型作为SR模型搜索任务的教师模型。随后,我们分两个阶段执行搜索任务:(a)预训练:使用一半的训练数据,在不更新架构参数的情况下优化内容损失Lc和训练超净权重。我们使用Adam optimizer训练100个时代,在每个优化步骤中,随机裁剪3块大小为32×32的补丁。对于架构参数,我们使用恒定的学习速率3×10−4,对于网络权重,我们将初始学习率设置为1×10−4,在第25、50、75纪元衰减0.5。(b) 搜索:优化内容损失Lc和感知损失Lp,我们在两个等分的训练数据上交替更新100个时代的网络权重和架构权重。优化器遵循与预训练阶段相同的设置。
b) 面向PSNR:为此,我们将面向PSNR的ESRGAN模型作为SR模型搜索的教师模型,并遵循类似的过程,即预训练和搜索,然而,我们在这两个阶段仅优化内容丢失Lc。
A.2。训练
我们从supernet继承权重,并在训练阶段使用DIV2K和Flickr2K数据集进行训练[29]。小块 大小32×32随机裁剪,批量大小设置为16。
面向可视化:SR模型培训分两步进行:(a)通过在900个时代内最小化内容损失来进行预训练。使用Adam优化器,初始学习率为1×10−4,学习率在第225、450、675个时期衰减0.5。(b) 1800个时代的感知损耗Lp微调。我们还使用Adam优化器进行训练,初始学习率为1×10−4,在第225、450、900、1350纪元衰减0.5。
面向PSNR:SR模型通过最小化900个时代的内容损失Lc进行训练,优化器遵循与面向可视化的模型训练中的预训练阶段相同的设置。注意,对于挑战设置,我们只使用DIV2K训练我们提出的模型(不使用额外的数据),并且只使用一名教师进行数据提炼,而不是使用基本事实进行强有力的监督,这可能会导致性能稍差。我们首先将DIV2K中的LR图像裁剪为大小为120×120的子图像。我们使用Adam训练300个阶段,其中学习率在第75、150、225个阶段下降0.5。

表6:两层(内核层和细胞层)和三层(内核层、细胞层和网络层)的定量结果比较。在这里∗ 指示路径是固定的而不是正在搜索的。
B.消融研究
我们使用SparseTmax连续松弛法进行了以下消融研究,比较了三层NAS与两层NAS的优势8。该实验装置将有助于理解穷举搜索的效用,从而在不牺牲性能的情况下获得轻质模型。
二层与三层:为了说明除了单元级和内核级搜索之外引入网络级搜索的必要性和优势,我们将具有固定网络级设计(即路径:[0,0,0,0,0,1,1])的二层与三层进行了比较。对于双层结构,我们使用AGD[8],为了公平比较,我们将AGD中原来的softmax组合替换为SparseTmax组合。从表6中,我们可以得出结论,TrilevelNAS中额外的网络级搜索使我们能够导出一个性能相当的更轻模型。从表6统计数据可以推断,我们方法中的参数数量明显小于双水平,而PSNR值略好于Set5和Set14上的可比GFLOP。

图7:Set5、Set14和DIV2K有效集上不同SR模型的可视化结果。我们的TrilevelNAS-A和TrilevelNAS-B可与非常轻的模型实现相当的视觉质量。
C.架构细节
表7-10显示了我们派生的网络级(路径)、单元级(每个RiR块中有5个可搜索操作)和内核级(输出通道号)架构。表7-8显示了在DIV2K和Flick2K数据集上使用面向可视化的搜索策略获得的SR架构模型,而表9-10提供了使用面向PSNR的搜索策略获得的SR架构。
获得的网络级路径显示在相应表的第一行中。路径索引行向量中的条目“0”和“1”分别表示RiR块和上采样/卷积层。此外,我们在表9-10中列出了单元级结构(即在每个RiR块中选择OP1-OP5中的操作)和内核级结构(即从完整的64个通道中选择输出通道)。对于每个操作,格式(A,B)指示选择内核宽度为B的操作A。关于不同操作的类型,DwsBlock、ResBlock、Conv分别表示深度卷积块、剩余块和卷积块。
D.更多可视化结果
图7显示了我们的方法与其他竞争方法的视觉比较。图中的最后两列显示了使用我们的方法分别使用TrilevelNAS-A和TrilevelNAS-B搜索策略获得的结果。显然,我们的方法提供了一个非常轻的模型,并提供了一个超级分辨率的图像,它在感知上与其他方法的结果一样好,甚至更好。

表7:使用原始AGD主干(TrilevelNAS-A)在DIV2K和Flickr2K数据集[29]上搜索的面向可视化的SR模型体系结构。我们介绍了网络级架构(即,堆叠RiR块和上采样层的路径)、单元级结构(即,在每个RiR块中选择OP1-OP5中的操作)和内核级结构(即,从完整的64个通道中选择输出通道)。在路径中,“0”表示RiR块,“1”表示上采样层。对于每个操作,格式(A,B)表示选择内核宽度为B的操作A。
表8:在DIV2K和Flickr2K数据集[29]上搜索的面向可视化的SR模型架构,以及我们提出的新主干(TrilevelNAS-B)。我们介绍了网络级架构(即,堆叠RiR块和卷积层的路径)、单元级结构(即,在每个RiR块中选择OP1-OP5中的操作)和内核级结构(即,从完整的64个通道中选择输出通道)。在路径中,“0”表示RiR块,“1”表示卷积层。对于每个操作,格式(A,B)表示选择内核宽度为B的操作A。
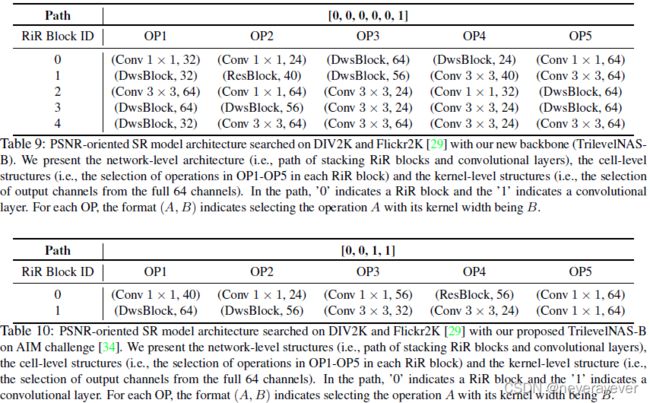
表9:在DIV2K和Flickr2K[29]上搜索到的以PSNR为导向的SR模型架构,以及我们的新主干(TrilevelNASB)。我们介绍了网络级架构(即,堆叠RiR块和卷积层的路径)、单元级结构(即,在每个RiR块中选择OP1-OP5中的操作)和内核级结构(即,从完整的64个通道中选择输出通道)。在路径中,“0”表示RiR块,“1”表示卷积层。对于每个操作,格式(A,B)表示选择内核宽度为B的操作A。
表10:DIV2K和Flickr2K[29]上搜索的面向PSNR的SR模型架构,以及我们在AIM挑战[34]上提出的TrilevelNAS-B。我们介绍了网络级结构(即,堆叠RiR块和卷积层的路径)、单元级结构(即,在每个RiR块中选择OP1-OP5中的操作)和内核级结构(即,从完整的64个通道中选择输出通道)。在路径中,“0”表示RiR块,“1”表示卷积层。对于每个操作,格式(A,B)表示选择内核宽度为B的操作A。