DPCM差分预测编码原理及实现
文章目录
- DPCM差分预测编码
-
- 算法原理
- 实现功能
- 实验代码
- 实验过程
- 实验结果
DPCM差分预测编码
算法原理
DPCM编解码的框图如下所示,可以很明显得发现这是一个带有负反馈的算法系统。
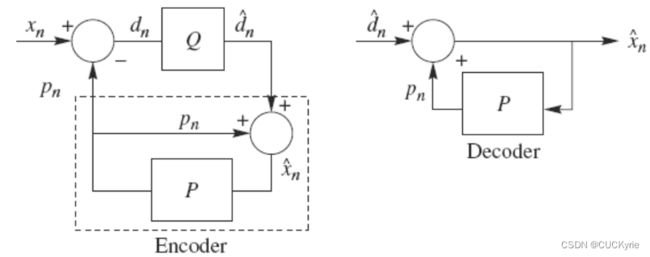
如上图所示,首先输入一个像素值,与上一个像素的预测值做差,将得到的差值进行编码,编码后的差值有两个去向:一个是直接输出,另一个是通过解码器反解出差值,和上一像素的预测值相加,就得到了当前像素的预测值,为下一个像素的到来做准备。
实现功能
本次采用左侧预测,并且默认最左侧像素前的真实值为均为128。并且实现了如下功能:
- 进行不同量化
bit数的差分预测编码 - 将编码结果进行输出并进行霍夫曼编码
- 分别计算原图像和量化后的图像进行概率分布
- 分别计算原图像经过熵编码和经过
DPCM+熵编码的图像的压缩比 - 比较二者压缩效率
- 计算重建图像的
PSNR
实验代码
#include 实验过程
通过运行上面的代码,我们可以得到8,4,2,1bit下的重建图像和量化误差图像。同时得到了每种bit量化下的编码概率分布及其PSNR值,下面我们来分别对原图和量化后的编码进行熵编码,本次实验采用Huffman编码。
使用以下bat指令:
huff_run.exe -i 8bitcode.yuv -o 8bitcode.huff -c -t 8bitcode.txt
huff_run.exe -i 4bitcode.yuv -o 4bitcode.huff -c -t 4bitcode.txt
huff_run.exe -i 2bitcode.yuv -o 2bitcode.huff -c -t 2bitcode.txt
huff_run.exe -i 1bitcode.yuv -o 1bitcode.huff -c -t 1bitcode.txt
huff_run.exe -i Lena256B.yuv -o standard.huff -c -t standard.txt
即可得到经过熵编码后的数据。
实验结果
注意:这里我们压缩比按照 A f t e r H u f f O r i g i n a l \frac{After_{Huff}}{Original} OriginalAfterHuff来计算。
| 8 bit | 4 bit | 2 bit | 1 bit | |
|---|---|---|---|---|
| 量化误差图 |  |
 |
 |
 |
| 重建图像 |  |
 |
 |
 |
| 概率分布图 |  |
 |
 |
 |
| 压缩比 | 51.055% | 29.075% | 25.709% | 25.017% |
| PSNR | 51.147 | 23.139 | 11.935 | 9.956 |
如果将原始图像直接进行熵编码,压缩比为71.09%。
可见经过熵编码之后,图像的大小会减小。
经过DCMP+熵编码之后,图像大小比直接使用熵编码减小的更多,随着量化比特数的减小,压缩效率越来越高,但是变化越来越缓慢;于此同时,图像质量,也就是PSNR的值迅速恶化,重建出的图像质量越来越差,到1bit是就已经很模糊了。
综上,量化应采用合适的量化比特数,使之既不至于太影响画面,又可以达到较高的压缩效率。