学习笔记(1) - RNN系列
都是从其他文章看到的,自己总结归纳一下,只是作为复习用,图片很多很多。
RNN
循环神经网络,是用来处理一些序列问题,翻译,曲线预测之类的,当然发展到现在,网络都是加夹在一起用的。
基本结构是这样的:

xt表示当前输入,h(t-1)为上一个的输出,h(t)是输出,h0需要自己初始化的,w表示权重,从表达式就可以看出当前的输出与之前的输出是由一定的关系。
如何训练的?
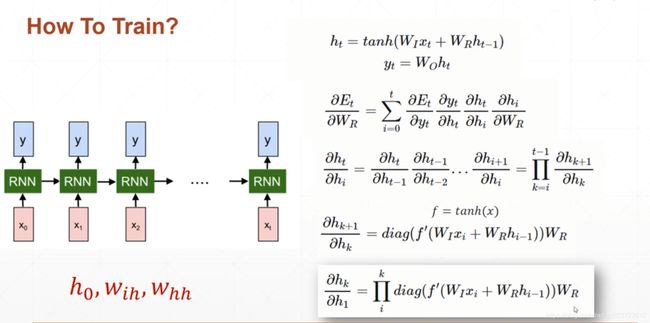
和CNN差不多,都是利用BP来更新W的权值,不同的是计算梯度是,与之前的所有输出都有关,因此称之为BPTT(Backpropation Through Time)
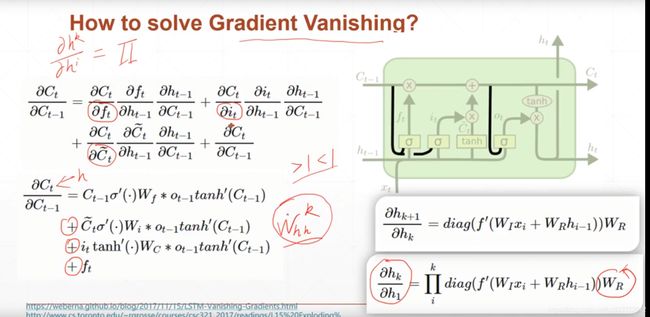
梯度推导到最后一步,得到一个累乘的式子,如果训练的timestep太长就会导致梯度消失,梯度爆炸等情况,LSTM就是为了解决这个问题而设计出来的,后面会讲。
现在看看pytorch中怎么如何搭建:
举个例子,下图是RNN中的矩阵的一些shape信息,这个要了解,方便自己初始化W和H:
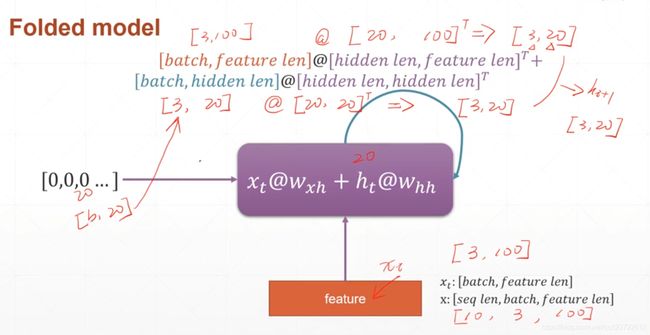
- 输入x [seq len , batch , feature len]
- 输出h [batch, hidden len ]
- 输入和输出之间的权值Wxh(hidden len, feature len )
- 上一个输出和当前输出之间的权值Whh[ hidden len , hidden len]
seq len 表示一个句子的长度,batch 表示传入句子的数量, feature len表示词向量的长度
比如由3个句子,一个句子10个单词,且一个单词由100维的向量表示
那么batch = 3 , seq len = 10, feature len =100 , hiddden len表示有多少隐藏节点
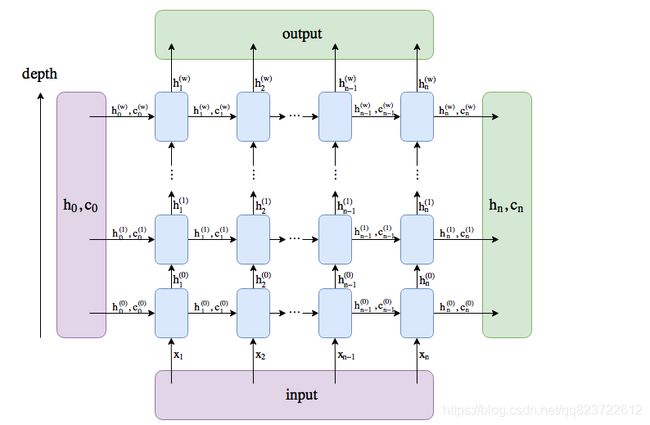
看看torch.nn.RNN

Input_size : 是你词向量的长度,上文提到的100
hidden_size :隐藏状态的个数,
num_layers: 表示有多少层RNN

在传入网络时,除了要传入输入数据,还有传入初始化h0,数据格式图里有。
其中的 out 和 ht 为方便理解,直接上图。
编程实例

这里搭建了一个4层,隐藏神经元为20的RNN,其中输入为【10,3,100】
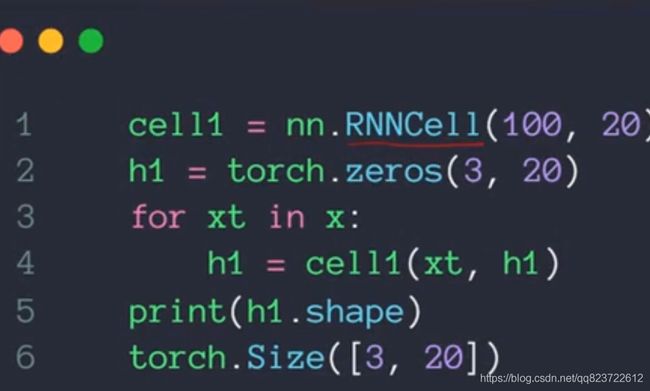
单个RNN细胞的创建
初始化定义没什么不同, 不同的是RNNCell只输出了ht

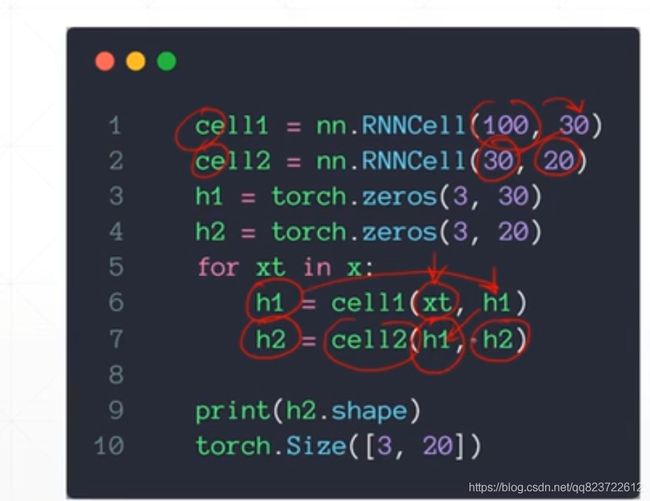
用RNNcell搭建一层RNN
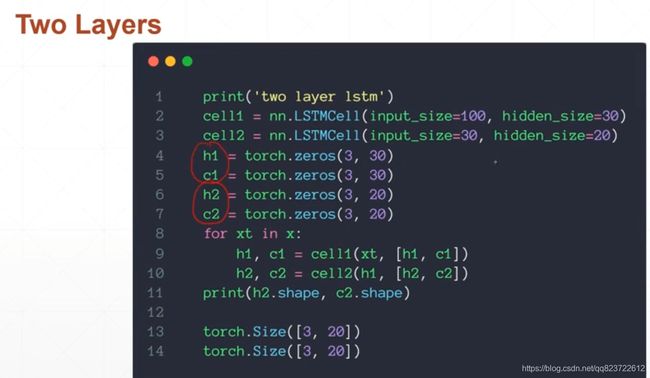
用RNNcell搭建两层RNN(也可以设置RNNcell里面的layer_num,不过两者有点不同,一个是100-30-20,一个是100-20)
梯度爆炸解决方案:设置一个阈值,大于这个阈值时用当前的梯度除于其本身的模

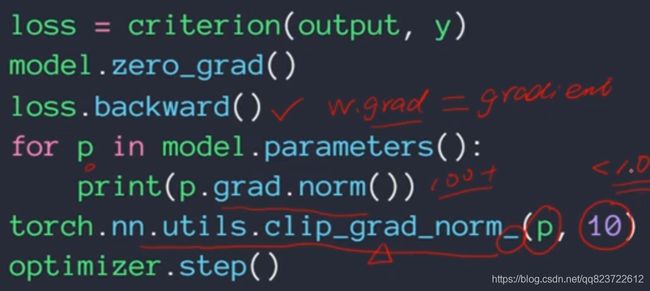
clip到小于10的范围,图片缩进有错误,倒数第二行应该是在for里面的,这方法有可以取的地方,不过现在为了避免这个问题都使用了LSTM。
LSTM

里面A就代表一个LSTMcell,这里有3个,从空间上讲,cell是同一个,但是时间上,cell_1表示输入x(1),隐状态h_1,cell_2表示输入x(2),隐状态h_2。所以就知道cell的数量是有序列或time_step决定,每个cell里神经元的个数就是hidden_size(或者叫num_units也行),因为通过上面分析的公式可知,有hidden_size和input_size超参数的设置,就确定了权重参数的大小,就确定了输出output大小,这与CNN的全连接是一样的。
下面来细致分析一下
LSTM主要包括遗忘门,输入门,输出门,解释的话,图片里面也说的很清楚
遗忘门:根据一定的概率[0,1]来对输入进行处理,1表示全保留,0表示舍弃
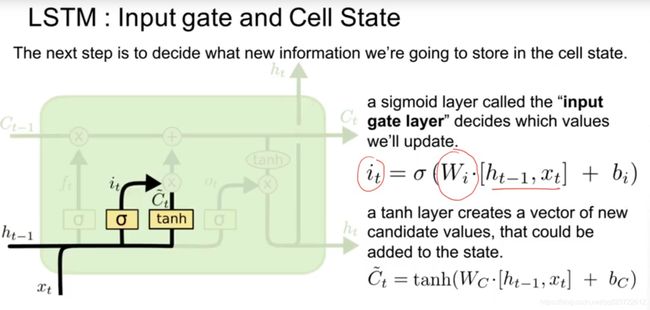
输入门用于更新细胞状态。首先将前一层隐藏状态的信息和当前输入的信息传递到 sigmoid 函数中去。将值调整到 0~1 之间来决定要更新哪些信息。0 表示不重要,1 表示重要。
其次还要将前一层隐藏状态的信息和当前输入的信息传递到 tanh 函数中去,创造一个新的侯选值向量。最后将 sigmoid 的输出值与 tanh 的输出值相乘,sigmoid 的输出值将决定 tanh 的输出值中哪些信息是重要且需要保留下来的。
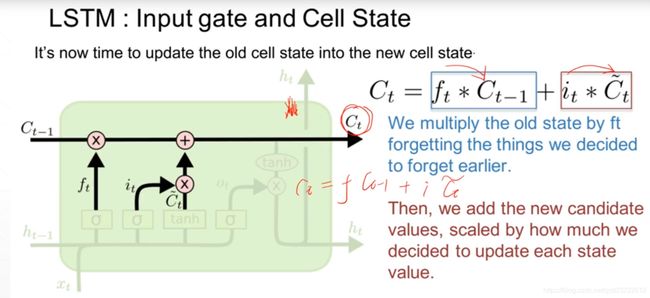
下一步,就是计算细胞状态。首先前一层的细胞状态与遗忘向量逐点相乘。如果它乘以接近 0 的值,意味着在新的细胞状态中,这些信息是需要丢弃掉的。然后再将该值与输入门的输出值逐点相加,将神经网络发现的新信息更新到细胞状态中去。至此,就得到了更新后的细胞状态。
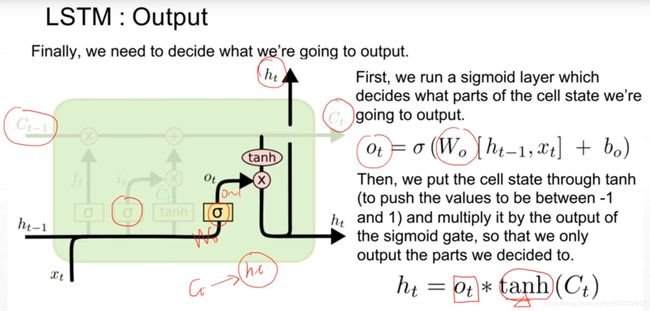
输出门用来确定下一个隐藏状态的值,隐藏状态包含了先前输入的信息。首先,我们将前一个隐藏状态和当前输入传递到 sigmoid 函数中,然后将新得到的细胞状态传递给 tanh 函数。
最后将 tanh 的输出与 sigmoid 的输出相乘,以确定隐藏状态应携带的信息。再将隐藏状态作为当前细胞的输出,把新的细胞状态和新的隐藏状态传递到下一个时间步长中去。
编程实例:LSTM是RNN的进化版,参数配置起来差不多



单个LSTMcell的创建


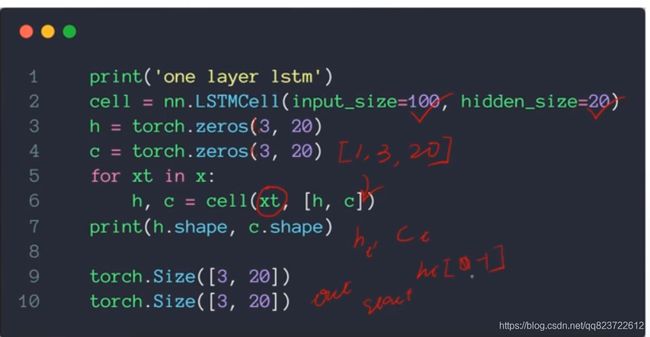
输出的话,可以是所有ht最后一个h【-1】,stack在一起。
https://blog.csdn.net/dQCFKyQDXYm3F8rB0/article/details/82922386?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522162830706216780261914379%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=162830706216780261914379&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_v2~hot_rank-1-82922386.first_rank_v2_pc_rank_v29&utm_term=GRU&spm=1018.2226.3001.4187
GRU
与LSTM一样,都是为了解决梯度弥散,爆炸而提出来的,相比GRU的计算效率更高。
网络结构:

重置门(第一个黄色块):对输入与前一个时刻状态h相乘,进行sigmoid处理,它决定了要忘记哪些信息以及哪些新信息需要被添加。
更新门(第二个黄色块):重置门用于决定遗忘先前信息的程度。
https://blog.csdn.net/wumian0123/article/details/110957464?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522162830663016780264060610%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=162830663016780264060610&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-2-110957464.first_rank_v2_pc_rank_v29&utm_term=GRU&spm=1018.2226.3001.4187
补充
在pytorch中没有string的类型,所以一般对输入都进行一些处理,ont-hot编码,word2vec(to vector),glove等。
word2vec:词转换为向量,通过学习向量的分布来对目标词进行分析,一般使用50或300维来表示一个单词。
embedding层就是用来做word2vec,先初始化语料库,如有100个词,进行初始化,再分配vertor,在训练时会更新改变。图片来自龙曲良老师的教学视频

或者用现成的包Glove
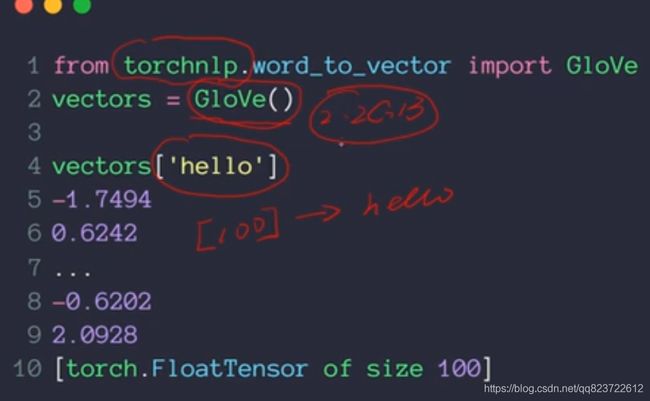
两者区别,可以去细致了解这个,本人也没看过:https://zhuanlan.zhihu.com/p/31023929