盲超分论文解读:Deep Constrained Least Squares for Blind Image Super-Resolution, CVPR 2022
ArXiv地址:Deep Constrained Least Squares for Blind Image Super-Resolution
代码和训练好的模型已经放出:https://github.com/megvii-research/DCLS-SR
一个经典的图像降质过程如下,其中y表示LR图像,x表示HR图像, k_h 表示模糊核, \downarrow_s 表示下采样操作,n表示噪声。

这里我们用 k_h 来表示模糊核(blur kernel)是因为这个blur kernel是应用在HR图像上的。在盲超分领域,大部分数据集都是根据这个公式合成而来(即都是先blur再下采样)。
相比于传统超分模型,盲超分的做法即是先估计kernel,再基于这个kernel去还原LR相应的SR图像。通常kernel估计的越准,还原的图像就越好,而估计的跟真实kernel有出入,则图像复原过程就会崩溃(各种artifacts)。个人以为这个其实就是从传统的盲去模糊算法引申而来的哈,通过这个kernel相当于给网络施加了一个额外约束,让网络更容易学习还原过程。如下图
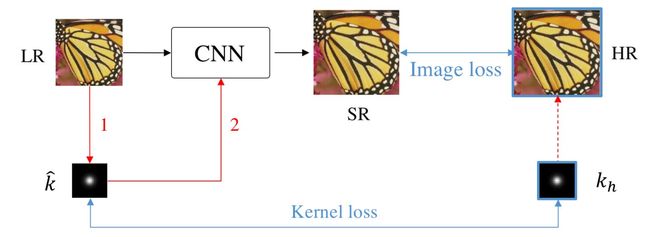
但这里主要有两个问题:
1)从LR上估计应用在HR图像的kernel k_h 是不合理的。首先因为LR是通过对HR模糊并下采样得到,关键就是下采样这步通常会发生信息混叠,使得LR与 k_h 之间的联系变得很模糊。因此很难从LR直接预测 k_h 。其次, 正如提到的k_h 是应用在HR图像上的,但在上图中,它却直接被送进网络去处理LR的特征。这也是不合理的。
2)在kernel的使用上,目前绝大多数的方法都还是采用Kai Zhang 的那一套kernel stretching策略。也就是先把kernel拉成一维,因为kernel比较稀疏,所以又用PCA对其降维,再concat上噪声水平,最后把1维向量拉成与输入LR图像相同尺寸的degradation maps,这样就可以把kernel与LR图像concat在一起送入网络了。这样动机就是把具有不同尺寸的图像和Kernel可以连在一起,但缺点也很明显,那就是破坏了kernel的内部空间关系,模糊先验信息得不到充分利用。如下图
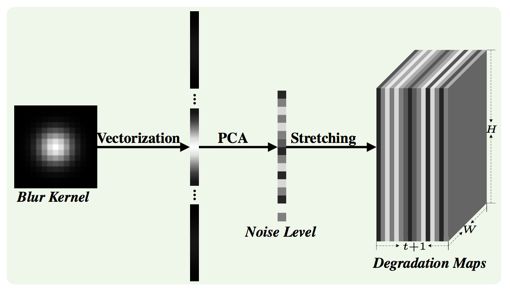
而我们希望的就是a)有一个专门针对LR特征的模糊核;b)可以妥善完美的利用这个kernel来对LR图像进行去模糊操作。
于是我们这篇文章的重点就是在经典降质模型的基础上重新构造一个可以应用到LR图像的kernel k_l 以及使用基于神经网络的约束最小二乘去卷积算法(Deep Constrained Least Squares Deconvolution)对模糊图像进行复原。
-
Degradation Model Reformulation
具体来说,先使用傅立叶变换对经典模型进行转换,将下采样操作与kernel分离开来

添加图片注释,不超过 140 字(可选)
令 k_l 表示应用于LR图像的kernel,其表示为

添加图片注释,不超过 140 字(可选)
用(3)替换(2)则可以得到新的降质模型:

之后我们的网络则是预测这个 k_l 而不是原始的 k_h ,而通过这种方式预测的kernel也会更加准确,更适合用在对LR特征的deblurring中。我们给一组Kernel Reformulation的例子如下

添加图片注释,不超过 140 字(可选)
-
Deep Constrained Least Squares (DCLS) Deconvolution
这里用 \hat k 来表示对低分辨率空间kernel k_l 的估计。考虑用一组线性网络层 \cal G_i 来提取LR的特征,则式(1)可以在特征空间中表示为

添加图片注释,不超过 140 字(可选)
而我们想要得到的是去模糊之后的特征 \hat {\cal R_i} (即是对 \cal G_i x_{\downarrow} 的一个估计)。
针对这个问题,可以将其转化为最小化如下方程:

添加图片注释,不超过 140 字(可选)
其中P一般是拉普拉斯算子, 最小化\cal C也就意味着使得图像趋近平滑,也就说明图像从模糊变清晰了。 而要解决式(7),自然而然可以想到使用拉格朗日乘数法来最小化如下方式:

添加图片注释,不超过 140 字(可选)
然后可以对式(8)求导,并令其导数为0,可以得到

添加图片注释,不超过 140 字(可选)
再通过引入傅立叶变换,可以得到最终的\hat {\cal R_i}

添加图片注释,不超过 140 字(可选)
这里我们观察到特征不同通道之间的表现形式是不一样的,比如有的通道特征比较sharpen,梯度比较大,而有的特征有比较平滑模糊。可以想像如果只用一个拉普拉斯算子以及一个拉格朗日乘数 \lambda 肯定是足以覆盖所有通道的。所以我们使用CNN来预测不同通道的平滑算子并隐式的包涵 \lambda 。最终可以得到:
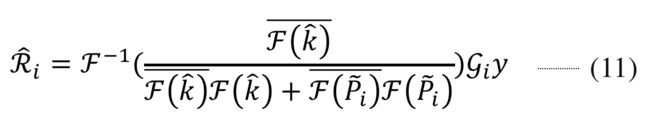
添加图片注释,不超过 140 字(可选)
这种方式的好处是可以充分利用整个kernel而不是暴力的在网络融入kernel。并且可以提供理论指导基于kernel进行显式的去模糊操作,此外还对噪声有一定的鲁棒性。整体框架如下图:
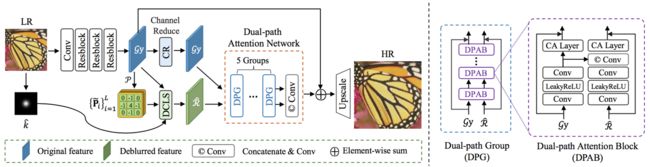
Overview of the network.
-
Dynamic Deep Linear Kernel
为了更好的估计kernel,这里也使用了一种动态参数估计的手段。主要目的就是把KernelGAN那种image-specific的深度线性网络转化为可用于处理多batch size的结构。如下:
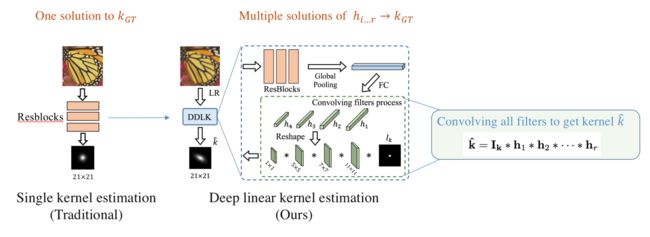
添加图片注释,不超过 140 字(可选)
-
实验
由于显式的使用了去模糊操作,该方法明显在边缘、细节等地方更加锐利清晰。此外,DCLS对噪声也更加鲁棒,在各个BlindSR的数据集都达到了SOTA性能。
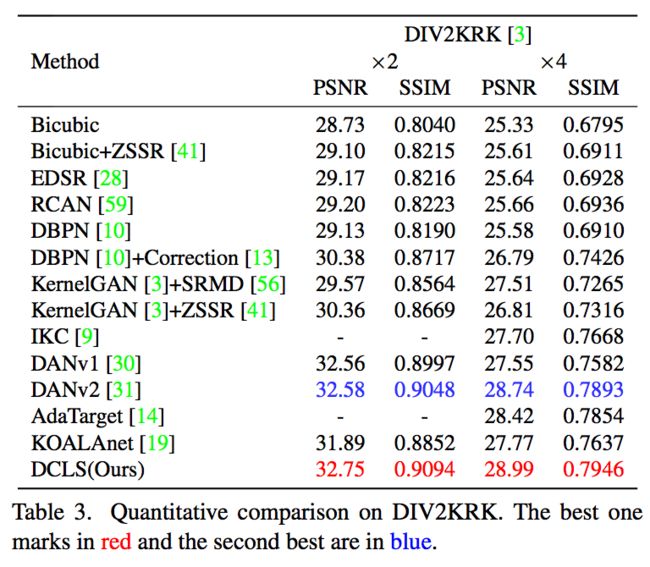
在DIV2KRK数据集上的表现
盲超分结果在视觉效果上的对比
======== 分割线 ============
同时我们今年NTIRE 2022多帧超分的真实赛道使用Transformer再次拿了个第一,感兴趣的同学也可以关注哦^_^
Paper:BSRT: Improving Burst Super-Resolution with Swin Transformer and Flow-Guided Deformable Alignment
代码和预训练模型也放出来了:
https://github.com/Algolzw/BSRT
------- 小分割 -------
去年(2021年)我们的多帧冠军模型在这里:
Paper: EBSR: Feature Enhanced Burst Super-Resolution With Deformable Alignment
代码和模型:
https://github.com/Algolzw/EBSR