MSN:用于小样本学习的掩码孪生网络
原文:Assran M, Caron M, Misra I, et al. Masked Siamese Networks for Label-Efficient Learning[J]. arXiv preprint arXiv:2204.07141, 2022.
源码:https://github.com/facebookresearch/msn
我们提出了掩码孪生网络(Masked Siamese Networks,MSN),这是一种用于图像表示学习的自监督框架。MSN将随机掩码图像的表示与未掩码图像的表示进行匹配。这种自监督预训练策略在应用于ViT编码器时具有很好的可扩展性,因为编码器只需处理未掩码的图像patches即可。因此,MSN提高了联合嵌入架构的可扩展性,同时产生了在小样本图像分类任务上具有竞争力的高语义级别的表示。例如,在ImageNet-1K小样本图像分类任务上,MSN_ViT_Base模型只需5000张有标签的图像就能达到72.4%的Top-1精度;而在1%的ImageNet-1K标签上,MSN_ViT_Base模型的Top-1精度达到了75.7%,为这个基准上的自监督学习设置了一个新的SOTA水平。
★ 相关工作
MAE(掩码自编码器)是可扩展的计算机视觉自监督学习方法
BEiT:图像Transformer的BERT式预训练
iBOT:使用在线Tokenizer对图像进行BERT式预训练
DINO:自监督ViT的新特性
BYOL:一种新的自监督学习方法
SimCLR:一个简单的视觉表示对比学习框架
SimCLR v2:大型自监督模型是强大的半监督学习者
★ 论文故事
自监督学习(Self-Supervised Learning,SSL)已成为图像表示无监督学习的有效策略,无需大量的人工标注数据。自监督学习利用无标签数据对大模型进行预训练,使其学习到可用于下游任务的有用表示。
SSL的核心思想之一是删除部分输入,并使模型预测被删除的内容。自回归模型和去噪自编码器通过预测像素级或token级的缺失,在视觉领域实例化了这一原理。掩码自编码器(Masked Auto-encoder,MAE)通过重建随机掩码的patches来学习图像的表示,已成功应用于视觉任务。然而,优化重建损失需要对低级图像细节进行建模,而这些细节对于涉及语义抽象的分类任务是不必要的。因此,掩码自编码器生成的表示通常需要针对语义识别任务进行微调,这可能导致小样本条件下的过拟合问题。尽管如此,MAE已使大模型的自监督预训练成为可能,并且在使用大型数据集微调模型时表现出先进性能。
另一方面,联合嵌入架构避免了重建。孪生网络(Siamese Network)等方法通过训练编码器为同一图像的两个不同视图生成相似嵌入来学习表示。这里的视图通常是通过对输入应用不同的图像变换来构建的,如随机缩放、裁剪和颜色抖动。这种基于不变性的预训练引入的归纳偏差通常会产生高语义级别的强大表示,但通常会忽略有助于建模的局部结构。
在这项工作中,我们提出了掩码孪生网络MSN,这是一种自监督的学习框架,它利用了掩码去噪的思想,同时避免了像素级和token级的重建。如图3所示,给定一幅图像的两个视图,MSN对锚定视图进行随机掩码,而目标视图保持不变。MSN的目标是训练一个神经网络编码器(例如ViT),为两个视图输出相似的嵌入。在这个过程中,MSN不会在输入层预测被掩码的patches,而是通过匹配掩码输入与未掩码输入的表示,在表示层隐式地执行去噪步骤。图2定性地展示了MSN去噪的有效性。

图3:掩码孪生网络MSN的架构。首先,使用随机数据增强生成图像的两个视图,称为锚定视图和目标视图。然后,对锚定视图进行随机掩码,而目标视图保持不变。接着,将掩码锚定视图的表示与未掩码目标视图的表示进行匹配。这里采用标准交叉熵损失作为优化准则。
图2:当掩码率为70%时,MSN预训练的ViT-L/7编码器表示的可视化结果。
从经验上看,MSN学到了强大的图像表示,在小样本预测任务上表现非常出色(参见图1)。MSN使用的标签量比当前基于掩码思想的自编码器少了100倍,却依然实现了良好的分类性能。在标准的1% ImageNet小样本分类任务中,MSN训练的ViT-B/4(使用4x4像素的patch)达到了75.7%的top-1精度,优于之前800M参数的SOTA卷积网络,同时使用的参数减少了10倍以上(参见图1a)。

图1:在ImageNet-1K上预训练的自监督模型的小样本评估结果。
学习一个良好的表示不应该依赖大量样本,因此,我们考虑采用更具挑战性的小样本分类基准,每类仅使用1到5张有标签的图像(参见表2)。MSN在这一领域也实现了SOTA性能。例如,当每类只使用5张有标签图像时,MSN在ImageNet-1K上预训练的ViT-L/7的top-1精度达到了72.1%,比之前的SOTA方法DINO高出8%。
与掩码自编码器类似,MSN也表现出良好的可扩展性,因为ViT编码器只需处理未掩码的patches即可。例如,通过随机掩码70%的patches,MSN使用的计算量和内存比未掩码的联合嵌入基线少了一半。实际上,我们仅在18台AWS p4d-24xlarge机器上对ViT-L/7进行了预训练。如果没有掩码,同样的工作需要超过42台机器。
我们还表明,在其他自监督基准上(例如使用大量的标签进行端到端微调、线性评估、迁移学习等),MSN相对于之前的工作也是有竞争力的。
★ 模型方法
如图3所示,掩码孪生网络MSN的训练过程结合了基于不变性的预训练和掩码去噪思想。MSN首先使用随机数据增强生成一张图像的两个视图,称为锚定视图和目标视图。然后,对锚定视图进行随机掩码,而目标视图保持不变。与基于聚类的SSL方法类似,学习是通过计算锚定视图和目标视图的一组聚类中心的软分布来实现的。接着,MSN将掩码锚定视图的表示与未掩码目标视图的表示进行比较,计算损失。我们使用标准交叉熵损失来优化这个过程。与先前关于掩码图像建模的工作相比,MSN中的掩码去噪过程是判别式的,而不是生成式的。MSN架构不会直接预测掩码patches的像素值(或token)。相反,我们将损失直接应用于与编码器的[CLS] token相对应的输出。
图3:掩码孪生网络MSN的架构。
如图4所示,我们研究了对锚定视图掩码的两种策略,即随机掩码和Focal掩码。在应用随机掩码时,我们在序列中随机丢弃可能不连续的patches。相反,在应用Focal掩码时,我们随机选择锚定视图的一个局部连续块,并丢弃它周围所有的patches。

图4:锚定视图的掩码策略。
★ 实验结果

表1:极小样本量的实验结果。
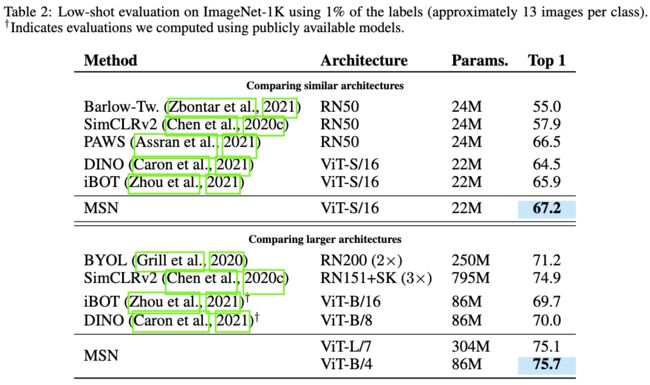
表2:使用1%的ImageNet-1K标签量(每类约13张)进行小样本评估的结果。
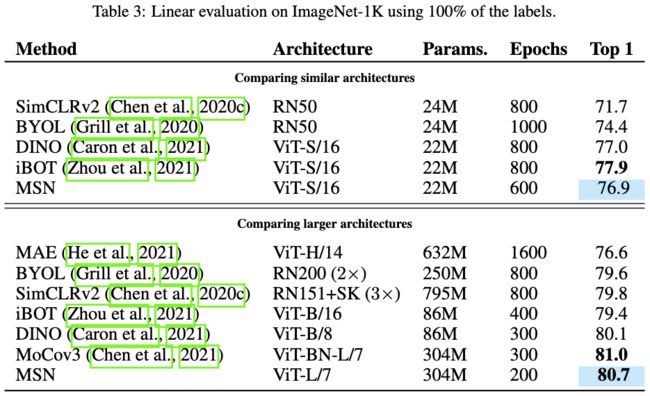
表3:使用100%的ImageNet-1K标签量(每类约1280张)进行线性评估的结果。
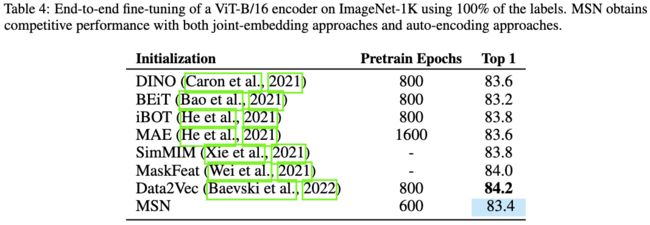
表4:使用100%的ImageNet-1K标签量对ViT-B/16编码器进行端到端微调。MSN通过联合嵌入方法和自编码方法获得了有竞争力的性能。

表5:端到端微调。使用在ImageNet-1K上预训练的ViT-Base/16进行迁移学习。

表6:线性评估。使用在ImageNet-1K上预训练的ViT-Base/16进行迁移学习。

表7:掩码策略对ViT-B/16小样本分类精度的影响。通过结合随机掩码和Focal掩码策略,MSN获得了最强性能。

表8:随机掩码率对ViT小样本分类精度的影响。

表9:锚定视图生成策略对ViT-B/16小样本分类精度的影响。
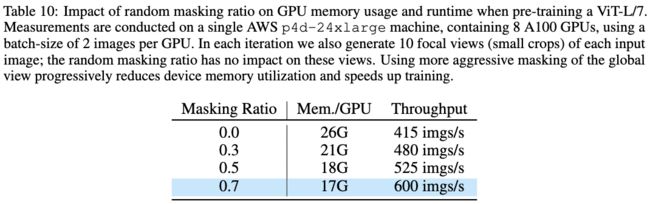
表10:随机掩码率对GPU显存使用率和处理速度的影响。

表11:Sinkhorn对ViT-S/16小样本分类精度的影响。

表12:聚类中心(prototypes)数量对ViT-B/16小样本分类精度的影响。使用更多的聚类中心对模型性能几乎没有影响,但使用更少的聚类中心会降低模型的性能。
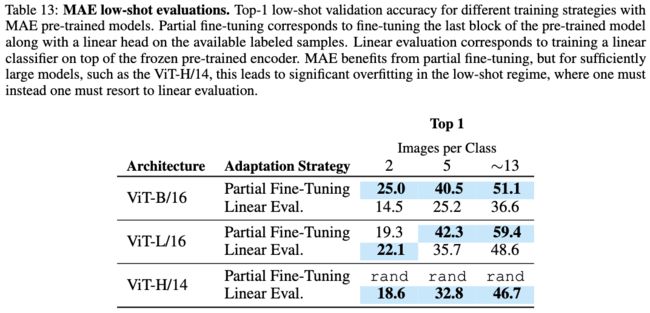
表13:MAE小样本评估结果。

表14:在ImageNet-A、ImageNet-R、ImageNet-Sketch和ImageNet-C上微调ViT-B/16的结果。
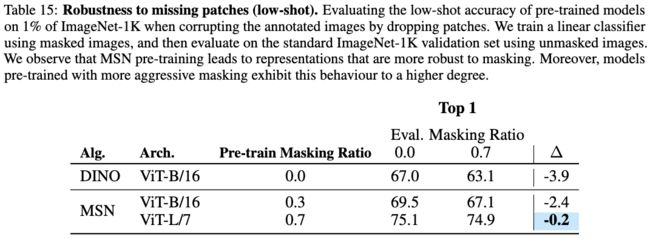
表15:在预训练和评估阶段进行掩码对模型性能的影响。

表16:掩码率对同一图像的掩码表示和原始表示之间的余弦相似度的影响。
图5:当掩码率为50%时,MSN预训练的ViT-B/8编码器表示的可视化结果。

图6:当掩码率为80%时,MSN预训练的ViT-B/8编码器表示的可视化结果。

图7:当不掩码时,MSN预训练的ViT-L/7编码器表示的可视化结果。

图8:当掩码率为70%时,MSN预训练的ViT-L/7编码器表示的可视化结果。

图9:当掩码率为90%时,MSN预训练的ViT-L/7编码器表示的可视化结果。
★ 总结讨论
我们提出了掩码孪生网络MSN,这是一种自监督学习框架,利用了掩码去噪的思想,同时避免了像素级和token级的重建。MSN能够学习强大的视觉表示,在小样本学习方面表现出色,同时提高了联合嵌入架构的可扩展性。
欢迎关注“多模态人工智能”公众号,一起进步^_^↑