论文: LeViT(Transformer 图像分类)
LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference
论文:https://arxiv.org/pdf/2104.01136.pdf
代码:https://github.com/facebookresearch/LeViT
预备知识:Transformer 、ViT 和 DeiT
架构
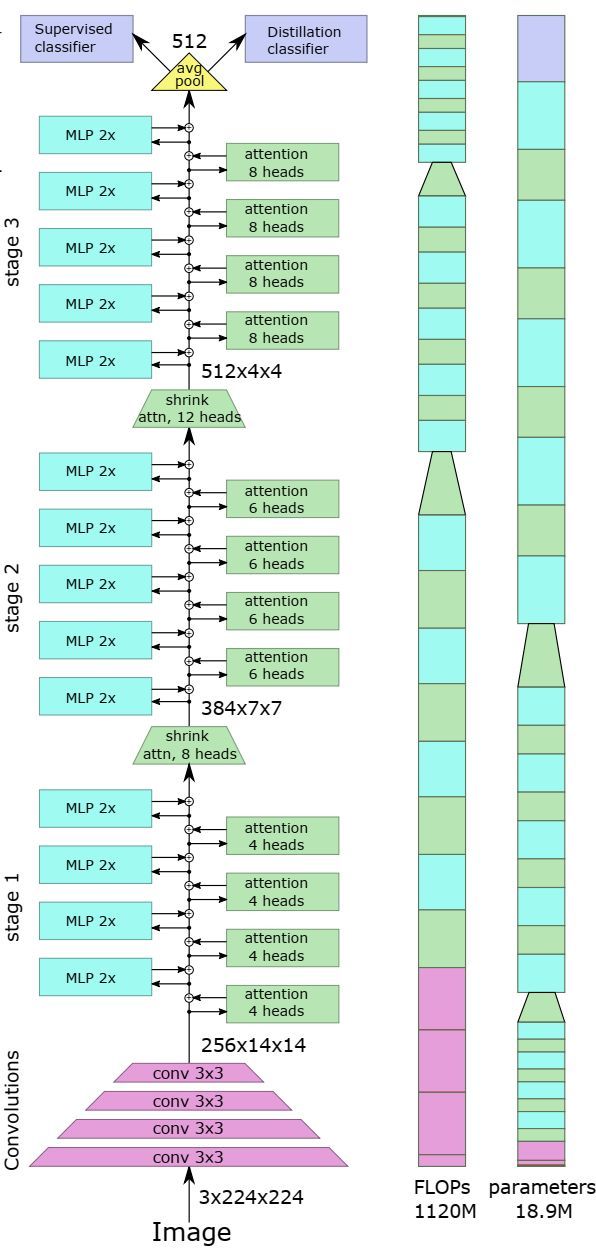
整体架构:
四层卷积、三个阶段
交替使用MLP和attention
| 模型\残差块 | attention head | 神经网络 |
|---|---|---|
| ViT | 8 | 两层MLP |
| LeViT | 4/6/8 | 两层MLP |
监督分类器和蒸馏分类器
主要贡献
- 重新设计的残差块:Attention和MLP
- Patch embedding 块嵌入
- 使用注意力作为下采样;
- 使用注意力偏置(attention bias)取代ViT的位置嵌入;
重新设计Attention和MLP

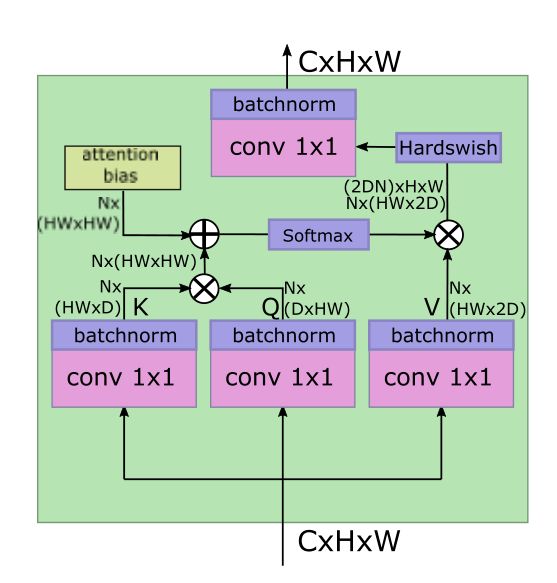
左图ViT编码器,右图Transformer编码器,第三图LeViT attention块
重新引入卷积组件。虽然许多工作旨在减少分类器和特征提取器的内存占用,但推理速度同样重要,高吞吐量对应更好的能效。在这项工作中,重新引入卷积组件来代替学习卷积特性的Transformer 组件。特别是,我们将Transformer 的统一结构替换为具有池的金字塔,类似于LeNet体系结构。
多分辨率金字塔。卷积堆叠形如金字塔(下3上1),在处理过程中,特征图的分辨率随着通道数量的增加而降低。使用ResNet-50级对进行预处理,然后作为Transformer的输入。
LeViT在Transformer架构是一个带有交替MLP和特征块的残差结构。特征块就是 attention 块。
Attention activation。在使用常规线性投影组合不同头部的输出之前,我们对结果 A h V A^hV AhV应用Hardswish激活, A A A为 Q K ⊤ + B QK^{\top}+B QK⊤+B,V是一个1 × 1卷积的输出, A h V A^hV AhV对应一个空间卷积,投影是另一个1 × 1卷积。
减少 MLP 块 。在ViT中,MLP残差块是一个线性层,它将嵌入维数增加了4倍,应用一个非线性,然后用另一个非线性将其还原到原来的嵌入维数。对于视觉架构,MLP通常在运行时间和参数方面比注意块更昂贵。对于LeViT,“MLP”是1×1卷积,然后是通常的批标准化。为了减少该相位的计算开销,我们将卷积的展开因子从4降低到2。一个设计目标是,注意力和MLP块消耗大约相同数量的FLOPs。
Patch embedding
上图(架构图),我们选择对输入应用4层3×3卷积(stride 2)来降低分辨率。特征图(通道)数量是 C = 3 , 32 , 64 , 128 , 256 C = 3,32,64,128,256 C=3,32,64,128,256。**这减少了较低层Transformer输入的特征图数量,而不丢失重要信息。
下采样
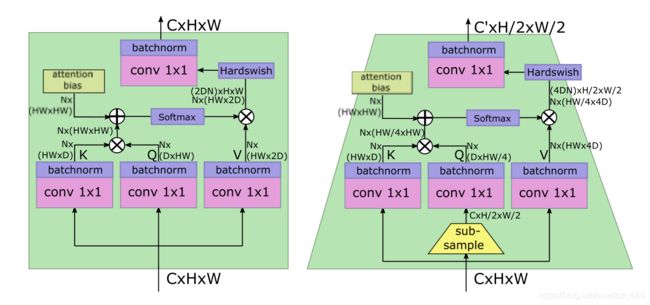
下图是两个attention块,左边的是普通的attention块,右边的是可以下采样的attention块。
右图,attention块 的输入为 ( C , H , W ) (C, H, W) (C,H,W),输出为 ( C ′ , H / 2 , W / 2 ) (C', H/2, W/2) (C′,H/2,W/2),其中 C ′ > C C'>C C′>C,因此 attention块 实现了下采样功能。由于特征图的大小的变化,这个注意块没有残差连接。为了防止信息丢失,我们把 attention head 的数量记为 C / D C/D C/D。值得注意的是,在查询Q之前先进行了subsample下采样。
注意力偏置替代位置嵌入
由于位置嵌入只包含在attention块的输入上,而位置编码对更高的层也很重要,因此在每个attention块中插入相对位置信息:只是在attention图中添加了attention bias(注意力偏置)。对于一个head h ∈ [ N ] h∈[N] h∈[N],两个像素 ( x , y ) (x, y) (x,y)和 ( x ′ , y ′ ) (x',y') (x′,y′)之间的标量attention值计算为
A ( x , y ) , ( x ′ , y ′ ) h = Q ( x , y ) , : • K ( x ′ , y ′ ) , : + B ∣ x − x ′ ∣ , ∣ y − y ′ ∣ h A_{(x,y),(x',y')}^h= Q_{(x,y),:}•K_{(x',y'),:}+B_{|x−x'|,|y−y'|}^h A(x,y),(x′,y′)h=Q(x,y),:•K(x′,y′),:+B∣x−x′∣,∣y−y′∣h
第一项 Q K QK QK是典型的attention。第二个是平移不变attention bias(注意力偏置)。每个头部有 H × W H×W H×W个参数对应不同的像素偏移量。
将 x − x ′ x−x' x−x′和 y − y ′ y−y' y−y′的差异对称,可以鼓励模型使用平移不变性进行训练。
更小的keys。偏置项减少了对keys进行位置信息编码的压力,所以我们减小keys矩阵相对于V矩阵的大小。如果keys的大小D∈{16,32},则V将拥有2D通道。限制keys的大小可以减少计算keys结果 Q K ⊤ QK^{\top} QK⊤。对于没有残差连接的下采样层,我们将V的维数设置为4D,以防止信息丢失。
LeViT组件
没有分类token。为了使用BCHW张量格式,我们删除了分类标记。类似于卷积网络,我们用最后一个激活映射上的平均池化来代替它,这将产生一个用于分类器的嵌入。对于蒸馏训练,我们分别训练分类和蒸馏任务的头。在测试时,平均两个头的输出。在实践中,levit可以使用BNC或BCHW张量格式,哪个更有效。
归一化层和激活。ViT架构中的FC层相当于1 × 1卷积。ViT在每个注意点和MLP单元之前使用层归一化。对于LeViT,每次卷积之后都要进行批处理归一化。在[54]之后,与残差连接连接的每个批标准化权重参数被初始化为零。批处理归一化可以与之前的卷积合并来进行推理,这比层归一化有运行时的优势(例如,在EfficientNet B0上,这种融合将GPU的推理速度提高了2倍)。而DeiT使用GELU函数,所有LeViT的非线性激活都是Hardswish。
Transformer 比卷积结构快的原因
对于给定的计算复杂度,Transformer 比卷积结构快的原因有很多。大多数硬件加速器(gpu、tpu)都经过优化,可以执行大型矩阵乘法。卷积需要复杂的数据访问模式,因此它们的操作通常是IO绑定的。