知识图谱-KGE-语义匹配-双线性模型(打分函数用到了双线性函数)-2011:RESCAL【双线性模型的开山之作】【把每个关系对应的邻接矩阵进行了矩阵的分解】
【paper】 A Three-Way Model for Collective Learning on Multi-Relational Data
【简介】 这篇文章应该算是双线性模型的开山之作。是德国的一个团队发表在 ICML 2011 上的工作,比较老了,主要思想是三维张量分解。
想研究啥,啥就很重要
Relational learning is becoming increasingly important in many areas of application.
直接本文做了啥(总)
Here, we present a novel approach to relational learning based on the factorization of a three-way tensor.
本文做了啥(分)
We show that unlike other tensor approaches, our method is able to perform collective learning via the latent components of the model and provide an efficient algorithm to compute the factorization.
实验怎么弄
We substantiate our theoretical considerations regarding the collective learning capabilities of our model by the means of experiments on both a new dataset and a dataset commonly used in entity resolution.
效果怎么样
Furthermore, we show on common benchmark datasets that our approach achieves better or on-par results, if compared to current state-of-the-art relational learning solutions, while it is significantly faster to compute.
模型
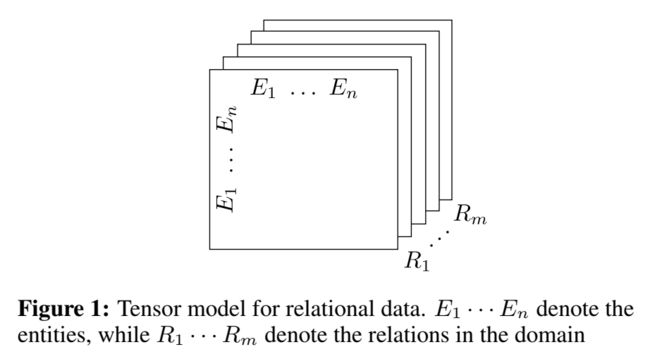
定义了一个 tensor,m 是关系数,n 是实体数,每个关系对应于 tensor 中的一个 slice,即一个矩阵,每个矩阵相当于表示图的邻接矩阵。位置元素为 1 代表两个实体之间存在这种关系,为 0 表示不存在。
对 tensor 进行分解:

AA 是 n×r 的矩阵,表示每个实体的隐性表示(latent-component representation),RkRk 是 r×r 的非对称矩阵,建模第 k 个属性/关系中的实体 latent component 的交互。
矩阵 AA 和 RkRk 通过约束最小化问题来计算:
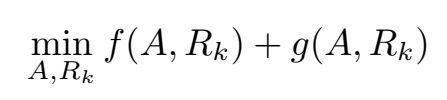
特别要提的是 RkRk 是非对称矩阵,这样可以建模非对称关系,在同一个实体作为头实体或尾实体时会得到不同的 latent component representation。
其中,


更具体地,
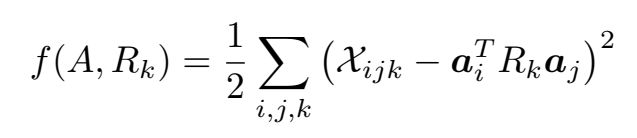
(其实贴图时可以不用定义高度)
这样的分解机制可以利用相关实体提供的信息进行表示,类似推荐里的协同过滤,这里称为 collective learning,举了一个栗子:

以上就是 Rescal 的核心思想了,后面有几个小节讲和其他方法的联系以及计算 factorization 的方法,没有仔细看。
实验
collective classification
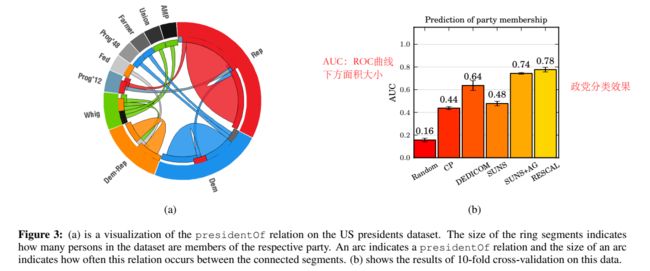
该实验使用自建的政党数据集,包括 93 个实体和 3 个关系,因此构建了 93×93×5 的 tensor。政党分类效果如下。
collective 实体消歧
实体消歧可以视为 isEqual 关系的链接预测,在 Cora 数据集上进行了实验:

除了上述两个实验,还在 Kinships, Nations 和 UMLS 数据集上进行了链接预测,并在 Nations 数据集上进行了聚类实验。并在各个数据集上进行了与其他两个算法的运行效率的比较,不再贴图了。
代码
文章中说 Rescal 是用不超过 120 行的 Python/Numpy实现的,但没有给出代码。Pykg2vec 实现了 Rescal,但我没有看明白,实现的比较巧妙。因为也没有打算做这块,就不继续花时间研究了。
class Rescal(PairwiseModel):
"""
`A Three-Way Model for Collective Learning on Multi-Relational Data`_ (RESCAL) is a tensor factorization approach to knowledge representation learning,
which is able to perform collective learning via the latent components of the factorization.
Rescal is a latent feature model where each relation is represented as a matrix modeling the iteraction between latent factors. It utilizes a weight matrix which specify how much the latent features of head and tail entities interact in the relation.
Portion of the code based on mnick_ and `OpenKE_Rescal`_.
Args:
config (object): Model configuration parameters.
.. _mnick: https://github.com/mnick/rescal.py/blob/master/rescal/rescal.py
.. _OpenKE_Rescal: https://github.com/thunlp/OpenKE/blob/master/models/RESCAL.py
.. _A Three-Way Model for Collective Learning on Multi-Relational Data : http://www.icml-2011.org/papers/438_icmlpaper.pdf
"""
def __init__(self, **kwargs):
super(Rescal, self).__init__(self.__class__.__name__.lower())
param_list = ["tot_entity", "tot_relation", "hidden_size", "margin"]
param_dict = self.load_params(param_list, kwargs)
self.__dict__.update(param_dict)
self.ent_embeddings = NamedEmbedding("ent_embedding", self.tot_entity, self.hidden_size)
self.rel_matrices = NamedEmbedding("rel_matrices", self.tot_relation, self.hidden_size * self.hidden_size)
nn.init.xavier_uniform_(self.ent_embeddings.weight)
nn.init.xavier_uniform_(self.rel_matrices.weight)
self.parameter_list = [
self.ent_embeddings,
self.rel_matrices,
]
self.loss = Criterion.pairwise_hinge
def embed(self, h, r, t):
""" Function to get the embedding value.
Args:
h (Tensor): Head entities ids.
r (Tensor): Relation ids of the triple.
t (Tensor): Tail entity ids of the triple.
Returns:
Tensors: Returns head, relation and tail embedding Tensors.
"""
k = self.hidden_size
self.ent_embeddings.weight.data = self.get_normalized_data(self.ent_embeddings, self.tot_entity, dim=-1)
self.rel_matrices.weight.data = self.get_normalized_data(self.rel_matrices, self.tot_relation, dim=-1)
emb_h = self.ent_embeddings(h)
emb_r = self.rel_matrices(r)
emb_t = self.ent_embeddings(t)
emb_h = emb_h.view(-1, k, 1)
emb_r = emb_r.view(-1, k, k)
emb_t = emb_t.view(-1, k, 1)
return emb_h, emb_r, emb_t
def forward(self, h, r, t):
h_e, r_e, t_e = self.embed(h, r, t)
# dim of h: [m, k, 1]
# r: [m, k, k]
# t: [m, k, 1]
return -torch.sum(h_e * torch.matmul(r_e, t_e), [1, 2])
@staticmethod
def get_normalized_data(embedding, num_embeddings, p=2, dim=1):
norms = torch.norm(embedding.weight, p, dim).data
return embedding.weight.data.div(norms.view(num_embeddings, 1).expand_as(embedding.weight))
在 FB15k 数据集上尝试运行了一下,效果很差:

【小结】 本文用三维张量分解进行三元组嵌入。
双线性模型(一)(RESCAL、LFM、DistMult) - 胡萝不青菜 - 博客园
第十二周.直播.DGL-KG, LifeSci讲解_oldmao_2000的博客-CSDN博客
RESCAL:A Three-Way Model for Collective Learning on Multi-Relational Data - 知乎