【自然语言处理概述】数据预处理
【自然语言处理概述】数据预处理

作者简介:在校大学生一枚,华为云享专家,阿里云专家博主,腾云先锋(TDP)成员,云曦智划项目总负责人,全国高等学校计算机教学与产业实践资源建设专家委员会(TIPCC)志愿者,以及编程爱好者,期待和大家一起学习,一起进步~
.
博客主页:ぃ灵彧が的学习日志
.
本文专栏:人工智能
.
专栏寄语:若你决定灿烂,山无遮,海无拦
.

文章目录
- 【自然语言处理概述】数据预处理
- 一、前沿
-
- (一)、任务描述
- (二)、环境配置
- 二、代码部分
-
- (一)、数据准备
- (二)、lending club 数据集
- (三)、缺失值处理
- (四)、去噪
- 三、总结
一、前沿
(一)、任务描述
在处理自然语言处理领域的任务时,有些新闻数据集中每条数据都是一个单独的文件。对海量数据文件进行空间占用、类型等分析十分必要,可加深用户对数据的了解,进而在处理数据时合理分配资源。
(二)、环境配置
本次实验平台为百度AI Studio,Python版本为Python3.7,下面介绍如何通过Python编程方式实现“海量”文件的遍历。
二、代码部分
(一)、数据准备
import os
import time
import pandas as pd
from zipfile import ZipFile
pd.set_option('display.max_columns', None)
pd.set_option('display.max_rows', 200)
import matplotlib as mpl
import seaborn as sns
import matplotlib.pyplot as plt
from matplotlib import font_manager
from matplotlib.ticker import FormatStrFormatter
# root = os.path.dirname(os.getcwd())
data_path = '.'
with ZipFile('data/data24164/lendingclub.zip') as z:
z.extractall()
def read_data(path):
"""
:params path: str 存放着数据集的文件夹路径
:return data: list 存着多个数据集 [df1, df2, ...]
"""
data = []
for f in os.listdir(path):
if f[-3:] != 'zip':
continue
df = pd.read_csv(os.path.join(data_path, f),
compression='zip', low_memory=False, skiprows=1)[:-2] # 不要最后2行数据
data.append(df)
print('读取{}, {:6d}个样本, {}个特征'.format(f, df.shape[0], df.shape[1]))
return data
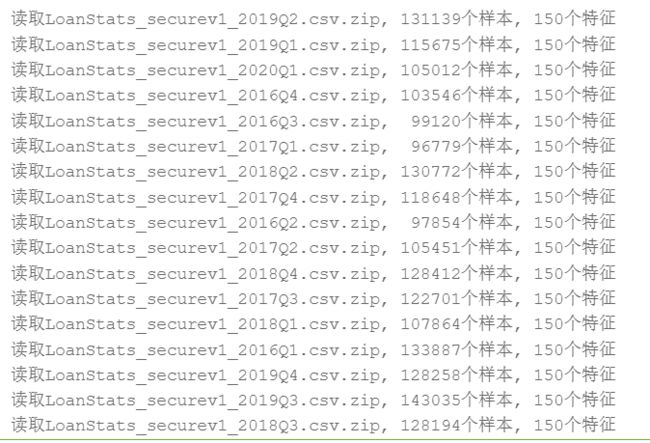
data = read_data(data_path)
输出结果如下图1所示:
data = pd.concat(data).reset_index(drop=True)
(二)、lending club 数据集
loan_status(贷款状态):
- Current
- Fully Paid (全部偿还)
- Charged Off (冲销,投资人有损失)
- Default 违约
- In Grace Period(在宽限期)
- Late (16-30 days)(延期16-30天)
- Late (31-120 days)(延期31-120天)
状态Current(贷款还款中),不能确定是否违约,所以这部分数据不是有效数据,应该去掉
https://www.lendingclub.com/info/demand-and-credit-profile.action
import os
"""
通过给定目录,统计所有的不同子文件类型及占用内存
"""
size_dict = {}
type_dict = {}
def get_size_type(path):
files = os.listdir(path)
for filename in files:
temp_path = os.path.join(path, filename)
if os.path.isdir(temp_path):
# 递归调用函数,实现深度文件名解析
get_size_type(temp_path)
elif os.path.isfile(temp_path):
# 获取文件后缀
type_name=os.path.splitext(temp_path)[1]
#无后缀名的文件
if not type_name:
type_dict.setdefault("None", 0)
type_dict["None"] += 1
size_dict.setdefault("None", 0)
size_dict["None"] += os.path.getsize(temp_path)
# 有后缀的文件
else:
type_dict.setdefault(type_name, 0)
type_dict[type_name] += 1
size_dict.setdefault(type_name, 0)
# 获取文件大小
size_dict[type_name] += os.path.getsize(temp_path)
剔除Current, In Grace Period, Issued, Fully Paid是好账,其他的作为坏账。
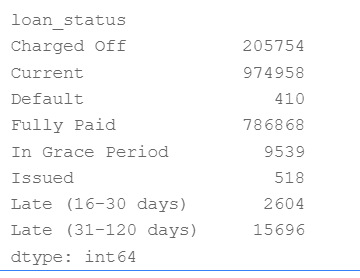
data.groupby('loan_status').size()
输出结果如下图2所示:
# 1是坏账 0 是好账 -1表示需要剔除的数据
loan_status_dict = {"Fully Paid": 0,
"Charged Off": 1,
"Late (31-120 days)": 1,
"Late (16-30 days)": 1,
"Default": 1,
"Current": -1,
"In Grace Period": -1,
"Issued": -1}
data["loan_status"] = data["loan_status"].map(loan_status_dict)
# 删掉
data = data[data["loan_status"]!=-1]
(三)、缺失值处理
total_misval = data.isna().sum().sort_values(ascending=False) # 缺失值个数从高到低
total_misval = total_misval[total_misval != 0] # 删除没有缺失值的特征
per_misval = total_misval / total_misval.max() # 百分比形式
# 绘制缺失值占比情况图
def draw_per_misval():
f, ax = plt.subplots(figsize=(10, 10),dpi=100)
sns.set_style("whitegrid")
# 只显示缺失值占比大于10%的
sns.barplot(per_misval[per_misval>0.1]*100,
per_misval[per_misval>0.1].index,
ax=ax,
palette="GnBu_r")
ax.xaxis.set_major_formatter(FormatStrFormatter("%2.f%%")) # 格式化字符串
ax.set_title("missing value")
plt.show()
draw_per_misval()
输出结果如下图3所示:

# 获得缺失值占比大于threshold的特征,删掉该特征
def drop_misval_ft(data, threshold, per_misval):
misval_ft = per_misval[per_misval > threshold].index
data.drop(misval_ft, axis=1, inplace=True)
print("删掉了{}个特征".format(len(misval_ft)))
return data
# 对于缺失值比例小于threshold的特征,删除含有这些特征的缺失值的样本:
def drop_samples(data, threshold, per_misval):
features = per_misval[per_misval < threshold].index
print("当前共有{}个样本".format(data.shape[0]))
data.dropna(subset=features, inplace=True)
print("删除完毕,当前共有{}个样本".format(data.shape[0]))
return data
data = drop_misval_ft(data, 0.15, per_misval)
data = drop_samples(data, 0.05, per_misval)
data["il_util"].fillna(0,inplace=True) # 0填补空缺值
data["mths_since_recent_inq"].fillna(0,inplace=True) # 0填补空缺值
data.drop("emp_title",axis=1,inplace=True)
emp_length_dict = {"10+ years": 10, "2 years": 2, "< 1 year": 0.5, "3 years": 3, "1 year": 1, "5 years": 5,
"4 years": 4, "6 years": 6, "7 years": 7, "8 years": 8, "9 years": 9}
data["emp_length"] = data["emp_length"].map(emp_length_dict)
data["emp_length"].fillna(value=0, inplace=True)
(四)、去噪
# 删除取值频率过高的特征
def drop_high_freq_features(df, freq_limit):
high_freq_features = []
for feature in df.columns:
n = df.shape[0] # 总样本数
most_ft_val = df[feature].value_counts().max() # 某特征取值频率最大的
per = most_ft_val/n # 频率占比
if per >freq_limit:
high_freq_features.append(feature)
df.drop(high_freq_features,axis=1,inplace=True) # 删除取值高频特征
print("删掉了{}个特征".format(len(high_freq_features)))
print("还剩{}个特征".format(df.shape[1]))
return df
data = drop_high_freq_features(data, freq_limit=0.95)
# 日期调一下,去除月份,只保留年份
data.issue_d = data.issue_d.apply(lambda x:x[-4:])
三、总结
本系列文章内容为根据清华社出版的《自然语言处理实践》所作的相关笔记和感悟,其中代码均为基于百度飞桨开发,若有任何侵权和不妥之处,请私信于我,定积极配合处理,看到必回!!!
最后,引用本次活动的一句话,来作为文章的结语~( ̄▽ ̄~)~:
【学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰。】
ps:更多精彩内容还请进入本文专栏:人工智能,进行查看,欢迎大家支持与指教啊~( ̄▽ ̄~)~
