【论文笔记】Learning Rich Features for Image Manipulation Detection(CVPR2018)
CVPR2018: Learning Rich Features for Image Manipulation Detection
原文链接:http://arxiv.org/abs/1805.04953
一作开源源码:https://github.com/pengzhou1108
方法的提出
- 目前篡改手段越来越多,也越来越高级,有些在对图片进行了篡改之后会对图片进行高斯平滑、压缩等后处理,导致很难识别出被篡改的区域
- 目前存在的一些检测技术也存在一些局限性,例如LSTM体系结构、局部噪声特征+CFA模式,这些方法大多集中于特定的篡改伪影,并仅限于特定的篡改技术
- 图像篡改检测不同于传统的语义对象检测,因为它更加关注篡改伪影而不是图像内容,这表明需要学习更丰富的特征。本文提出了一种双流的Faster R-CNN网络,来学习丰富的图像篡改检测特征。实验表明,该网络对拼接、复制移动和删除具有鲁棒性。此外,该网络使我们能够对可疑的篡改技术进行分类
- 本文还使用SRM滤波器内核来提取低级噪声,用作Faster R-CNN网络的输入,并学习从噪声特征中捕获篡改痕迹。此外,还联合训练一个并行的RGB流来建模中级和高级的视觉篡改伪影
在四个标准图像处理数据集上的实验表明本文的双流框架优于每个单独的流,并且与其他方法相比,在压缩图像和改变大小的图像的检测上表现出了该方法的鲁棒性,达到了最先进的性能。
先导知识
三种常见篡改类型:
- 拼接(Image splicing) :把其他图片里面的某个物体拼接到另一张图上。
- 复制移动(Copy-move) :同一张图上,进行部分区域的拷贝,然后放到该图中的其它地方。
- 去除(Remove):对像素进行修改,将某部分图像“移除”。

第一列是真实图像,第二列是P过的图,第三列是真实数据的掩膜展现出篡改的区域。
Faster R-CNN网络
一种目标检测算法。
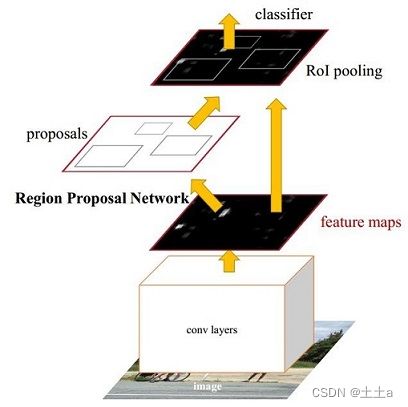
上图为Faster R-CNN的基本结构,由四个部分组成:
- 卷积层(Conv layers)。用于提取图片的特征。输入为整张图片,输出为提取出的特征feature maps。由一组基础的conv+relu+pooling层组成。该feature maps被共享用于后续RPN层和全连接层。
- RPN网络(Region Proposal Networks)。RPN网络用于生成候选区域(region proposals)。输入为第一步中生成的featrue maps,输出为多个候选区域。
- 感兴趣区域池化层(Roi Pooling)。该层收集输入的feature maps和proposals,综合这些信息后提取proposal feature maps,送入后续全连接层判定目标类别。
- 分类和回归(Classification)。输出候选区域所属的类,和候选区域在图像中的精确位置。
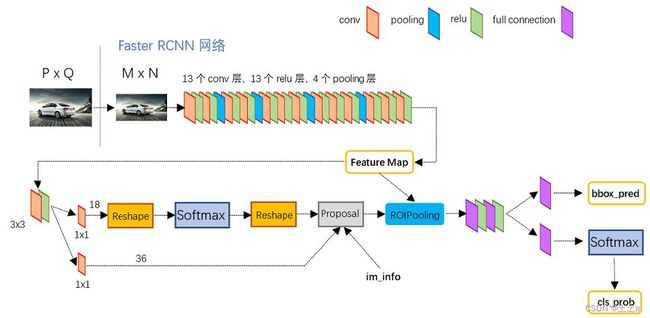
下图是python版本中的VGG16模型中的Faster R-CNN的网络结构
所提出的方法
RGB-N: 双流的Faster R-CNN网络。双流分别为RGB stream、noise stream。
它是一种多任务框架:同时执行篡改分类和边界框回归。
- RGB流: 提供RGB图像,从RGB图像输入中提取特征,以发现篡改伪像。
- 噪声流: 提供SRM图像,从中提取的噪声特征来发现真实区域和篡改区域之间的噪声不一致。
- 在全连接层之前通过双线性池化融合来自两个流的特征,以进行篡改分类。
- RPN(区域候选网络)使用RGB流来定位篡改区域。
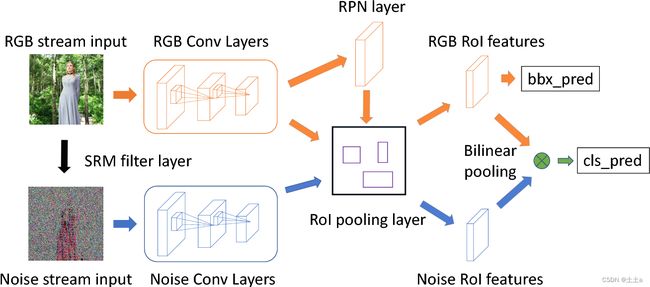
如上图所示,橘黄色的箭头连起来的是RGB流,蓝色的箭头连起来的是噪声流。每个单独的流其实都是一个Faster R-CNN。
RGB输入流
RGB流是单个Faster R-CNN网络,用于边界框回归和篡改分类。我们使用ResNet 101网络从输入的RGB图像中学习特征。ResNet的最后一个卷积层的输出功能用于篡改分类。
传统的对象检测的RPN网络搜索的是可能是对象的区域,而本文的RPN网络搜索的是可能被篡改的区域。候选区域可能不一定是对象,例如,在移除篡改过程中的情况。
RPN网络的损失函数为:(与Faster R-CNN的RPN是一样的)


噪声输入流
RGB通道不足以解决所有不同的篡改情况。尤其是,经过精心后期处理以隐藏拼接边界并减少对比度差异的篡改图像对于RGB流而言是具有挑战性的。因此,我们利用图像的局部噪声分布来提供其他证据。与RGB流相反,噪声流旨在更加关注噪声,而不是语义图像内容。
噪声流的主干卷积网络架构与RGB流相同。噪声流与RGB流共享相同的RoI池层。对于边界框回归,我们仅使用RGB通道,因为根据我们的实验,RGB特征比RPN网络的噪声特征表现更好。
双线性池化
RGB通道不足以解决所有不同的篡改情况。尤其是,经过精心后期处理以隐藏拼接边界并减少对比度差异的篡改图像对于RGB流而言是具有挑战性的。
与RGB流相反,噪声流旨在更加关注噪声,而不是语义图像内容。使用SRM过滤器从RGB图像中提取局部噪声特征作为噪声流的输入。噪声流的主干卷积网络架构与RGB流相同。噪声流与RGB流共享相同的RoI池化层。对于边界框回归,这里仅使用RGB通道。
如下图所示,第一列是篡改图像,第二列是篡改图像红色框框住的部分放大图,第三列是噪声图,第四列为GT。
第二列的棒球员身体边缘异常高的对比度提供了一个强烈的线索,表明篡改的存在。而第二行房屋则很难用视觉直接观察出,但是噪声特征却很明显地检测到了篡改痕迹。由此可见,在不同的场景中,视觉信息和噪声特征在揭示篡改工件方面起着互补的作用。

使用双线性池化将RGB流与噪声流结合在一起进行篡改检测。
经过全连接和softmax层后,我们获得了RoI区域的预测类别。我们将交叉熵损失用于篡改分类,将smooth L1损失用于边界框回归。 总损失函数为:
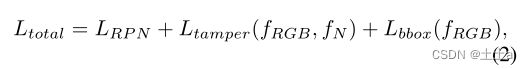
其中L-total表示总损失。L-RPN表示RPN网络中的RPN损失。L-tamper表示最终的交叉熵分类损失,它基于RGB和噪声流中的双线性池特征。L-bbox表示最终的边界框回归损失。f-RGB和f-N是RGB和噪声流的RoI特征。所有项的总和为总损失函数。
实验部分
我们在四个标准图像处理数据集上展示了我们的双流网络,并将结果与最新方法进行了比较。我们还比较了不同的数据扩充,并测量了我们的方法对大小调整和JPEG压缩的鲁棒性。
预训练模型
由于没有充足的数据用于训练,实验时首先在合成的数据集上进行预训练。
- 使用COCO中的图像和注释自动创建合成数据集。使用分割标注从COCO中随机选取objects,然后粘贴到其他图像中。分开训练集和测试集,训练集和测试集分别是90%、10%。
- 模型的输出是带有置信度得分的边界框,表示检测到的区域是否已被篡改。为了在RoI中包括一些真实区域以便更好地进行比较,我们在训练过程中将默认边界框稍微扩大了20个像素,以便RGB流和噪声流都了解到篡改区域与真实区域之间的不一致性。
- 在这个合成数据集上端到端地训练我们的模型。在Faster R-CNN中使用的ResNet 101在ImageNet上进行了预训练。使用平均精度(AP)进行评估,其度量与COCO 检测评估相同。
为什么只选择RGB特征作为RPN的输入呢?
这是由实验对比做出来的选择。本文作者做了单流网络、RPN采用不同输入的双流网络在检测篡改区域上的对比实验。结果如下表,不仅表明双流比单流的效果出色,也表明了仅采用RGB特征作为RPN输入的双流的效果是最好的。

RGB Net:仅使用RGB流检测篡改区域
Noise Net:仅使用噪声流
RGB-N noise RPN:双流,但采用噪声特征作为RPN输入
Noise+RGB RPN:双流,同时采用噪声和RGB特征作为RPN输入
RGB-N:双流,仅采用RGB特征作为RPN输入(本文采用的方法)
在标准数据集上的实验
数据集
NIST16 :该数据集包含了之前提到的三种图像篡改类型, 对该数据集中的操作进行后处理以隐藏可见痕迹。它们还提供用于评估的真实值篡改掩模。
CASIA:提供各种对象的拼接和复制移动图像。仔细选择被篡改的区域,并应用一些后期处理,例如滤波和模糊处理。通过对篡改图像和原始图像之间的差异进行阈值处理来获得真实值掩模。我们使用CASIA 2.0进行训练,并使用CASIA 1.0进行测试。
COVER:是一个相对较小的数据集,专注于复制移动。它覆盖了与粘贴区域相似的对象,以隐藏篡改伪影,并提供真实值掩模。
Columbia数据集:侧重于基于未压缩图像的拼接。提供真实值掩模。
评价指标
F1分数和AUC,与基线模型(ELA、NOI1、CFA1、MFCN、J-LSTM)做对比。
实验结果
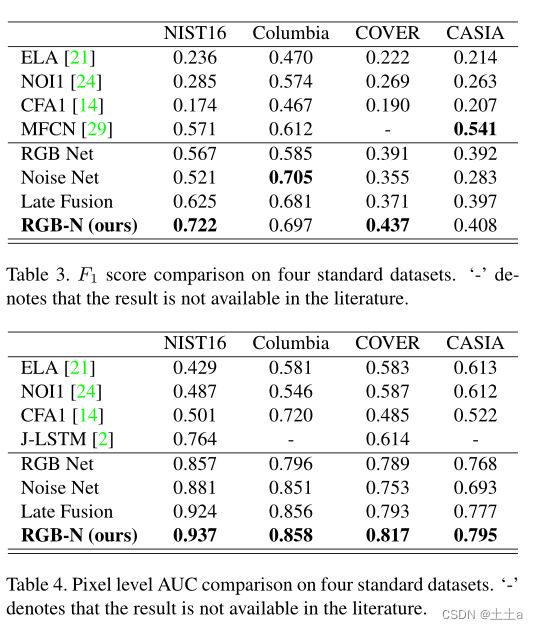
表3显示了本文的方法和baseline model之间的F1分数比较
表4提供了AUC比较。
从表3表4可以看出,本文的方法使优于传统方法的以及双流的性能优于每个单独的流。
数据增强:我们在下表中比较了不同的数据增强方法。与没有增强相比,图像翻转可提高性能,而其他增强方法(如JPEG压缩和噪声)则几乎没有改善。
由下表可以看出:第三行相较于第四行,性能有了明显的提升。而在此基础上再加入JPEG压缩和噪声的一、二行则几乎没有改善。

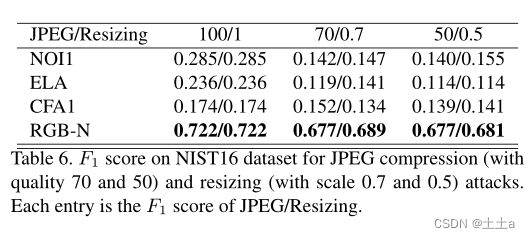
JPEG的鲁棒性和调整大小的攻击:我们测试了我们方法的鲁棒性,并与下表中的3种方法进行了比较。我们的方法对这些攻击更鲁棒,并且胜过其他方法。如下表所示。
篡改技术检测
通过实验测试了当前方法在三种篡改类型上面的性能,如下表。

可以看出,对拼接的检测效果最好,这是因为拼接很可能同时产生RGB伪影(例如不自然的边缘、对比度差异)以及噪声伪影。
对去除的检测由于复制移动,这是因为去除过程后的修补对噪声特征有很大影响。
而复制移动性能没那么好是因为
- 由于复制的区域来自同一张图像,这产生了相似的噪声分布,使我们的噪声流变得混乱。
- 两个区域通常具有相同的对比度。
- 该技术理想情况下需要将两个对象进行相互比较(即,它需要同时查找和比较两个RoI),而当前方法无法做到这一点。
定性结果
第1行是COVER数据集的检测结果,复制移动包会混淆RGB网络和噪声网络。RGB-N在这种情况下实现了更好的检测,因为它结合了两个流的特征。
第2行是哥伦比亚数据集的检测结果,RGB网络产生的结果比噪声流更精确。
第3行是CASIA1.0数据集的检测结果,拼接的对象在RGB和噪声流中都留下了明显的篡改伪影,从而对RGB、噪声和RGB-N网络进行精确检测。
由此可见,本文提出的双流模型优于任何一个单独的流,并且,即使单个数据流之一发生故障,我们的双流网络也能产生良好的性能。

下图显示了RGB-N网络对使用NIST16的篡改技术检测任务的结果。如图所示,我们的网络针对不同的篡改技术会产生准确的结果。

总结
我们提出了一种同时使用RGB流和噪声流的新型网络,以学习用于图像篡改检测的丰富特征。我们通过根据隐写分析文献改编的SRM滤波器层提取噪声特征,这使我们的模型能够捕获篡改区域与真实区域之间的噪声不一致。我们探索了从RGB查找篡改区域和图像的噪声特征的补充作用。毫不奇怪,两个流的融合导致性能提高。在标准数据集上进行的实验表明,我们的方法不仅可以检测篡改伪像,而且可以区分各种篡改技术。将来将探索更多特征,包括JPEG压缩。