【论文笔记】SPAN: Spatial Pyramid Attention Network for Image Manipulation Localization
SPAN: Spatial Pyramid Attention Network for Image Manipulation Localization
发布于ECCV2020
原文链接:https://www.ecva.net/papers/eccv_2020/papers_ECCV/papers/123660307.pdf
源码链接:https://github.com/ZhiHanZ/IRIS0-SPAN
摘要
我们提出了一种新颖的框架,即空间金字塔注意网络 (SPAN),用于检测和定位多种类型的图像处理。所提出的架构通过构建局部自注意力块的金字塔,高效地建模多尺度图像块之间的关系。该设计包括一个新颖的位置投影来编码补丁的空间位置。 SPAN 在通用的合成数据集上进行训练,但也可以针对特定数据集进行微调;与以前的最先进方法相比,所提出的方法在标准数据集上显示出显著的性能提升。
引言
SPAN被设计用于多种操作类型的像素级掩模预测。
先前的方法:
- RGB-N 提出了一种基于 Faster R-CNN 的方法来检测篡改区域;因此,它的预测仅限于矩形框。它还需要微调以适应新的数据集。
- ManTra-Net将图像处理类型分类和定位的任务结合到一个统一的框架中,并取得了与 RGB-N 相当的结果,但没有对目标评估数据进行微调。ManTra-Net进行像素级预测。然而,其定位模块仅对特征图不同尺度上相同点的“垂直”关系进行建模,而不会对图像块之间的空间关系进行建模。
本文的空间金字塔注意网络 (SPAN) 中的自注意模块使用多尺度传播和空间关系对“垂直”关系进行建模。
SPAN
SPAN 由三个模块组成:特征提取器、空间金字塔注意模块和决策模块。采用ManTra-Net提供的预训练特征提取器作为我们的特征提取器。为了建立不同图像块之间的关系,我们构建了一个自注意力层的层次结构,并将特征作为输入。
层次结构设计为首先计算局部自我注意块,并通过金字塔层次传播局部信息。这可以对邻居进行有效的多尺度建模。在每个自我注意层内,我们根据每个像素与其邻域像素的关系计算一个新的表示形式。为了更好地捕捉自我注意块中每个邻居的空间信息,我们还引入了更适合我们定位任务的位置投影,而不是用于机器翻译任务的原始位置嵌入方法。由几个2D卷积层组成的决策模块被应用于金字塔空间注意力传播模块的输出之上,以预测定位掩码。
本文提出的 SPAN 模型优于当前最先进的 (SoTA) 方法 ManTra-Net和 RGB-N,几乎在每个基准测试中具有相同的设置(例如,比哥伦比亚的 ManTra-Net 提高 11.21% ,没有微调;在 Coverage 上比 RGB-N 有 9.5% 的改进,有微调)。
主要贡献
- 设计了一种新颖的空间金字塔注意力网络架构,可以通过局部自注意力块在多个尺度上有效和明确地比较补丁;
- 我们在自注意力机制中引入了位置投影,而不是文本处理中使用的经典位置嵌入;
- 与最先进的方法相比,比较和建模不同尺度图像块之间关系的能力带来了更高的准确性。
方法
概述
SPAN由特征提取器、金字塔空间注意力传播和决策模块三个模块组成。 我们采用了ManTra-Net中提出的预先训练的特征提取器。 特征提取网络是在基于从Dresden图像数据库中采样的图像生成的合成数据上训练的,使用针对385类型图像操作数据的分类监督。 该特征提取器采用更宽更深的VGG网络作为主干结构,结合Bayer和SRM卷积层从视觉伪影和噪声模式中提取丰富的特征。
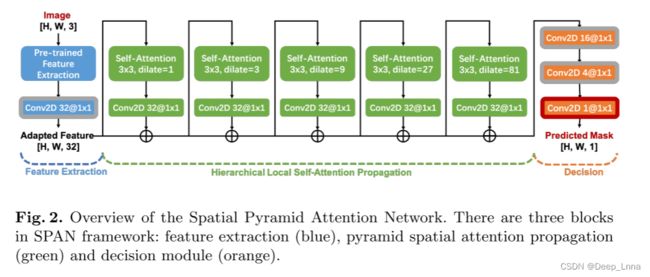
在使用预训练特征提取器提取的嵌入之上,应用卷积层来调整特征以馈入空间注意模块。金字塔空间注意力传播模块旨在建立像素表示的多个尺度上的空间关系。递归地应用五层局部自注意块以从相邻像素或块中提取信息。为了保留多尺度层的细节,使用残差连接,在每个自注意力块之后将输入添加回输出。为了生成最终的掩码输出,应用了 2D 卷积块。应用 Sigmoid 激活来预测软篡改掩码。
局部自注意块
把一个像素点为中心的周围(2n+1)(2n+1)邻域之内的所有像素的信息全部接收到一个对应点。n=1时,33领域如下所示,



邻域{ Y 1 , Y 2 , . . . , Y ( 2 n + 1 ) 2 Y_1,Y_2,...,Y_{(2n+1)^2} Y1,Y2,...,Y(2n+1)2}与像素 X i , j X_{i,j} Xi,j之间的关系可以用二次型参数来显式建模,并用于帮助构建用于操作定位的特征。 由于卷积块只是将像素添加到一起,而不是建立它们之间的相互关系,因此任何具有类似参数的卷积网络都不容易提取这些信息。
位置投影
如Transformer工作所示,位置嵌入在自注意计算中是必不可少的,以使模型能够区分具有不同时间顺序的输入之间的差异。 在我们的例子中,模型知道邻居像素和查询像素之间的相对空间关系也很重要。 在机器翻译模型Transformer中,位置嵌入是可学习的权重,它直接添加到每个输入位置的输入。 这对于语言任务是合理的,因为单词嵌入空间通常被训练为对应于语言意义的支持向量加法和减法。 然而,由于嵌入空间不符合这些要求,我们提出用可学习矩阵投影 M L 1 ≤ L ≤ ( 2 n + 1 ) 2 {ML}_{1≤L≤(2n+1)^2} ML1≤L≤(2n+1)2 来表示 ( 2 n + 1 ) 2 (2n+1)^2 (2n+1)2个可能的相对空间关系。 使用位置投影,LSA块现在变成
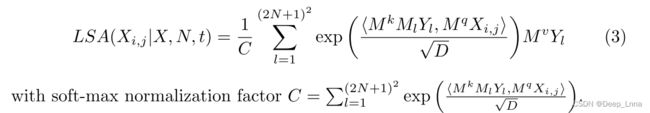
在图3中,我们说明了当n=1时的局部自注意块。 给定图像张量X,我们首先对每个目标像素 X i , j X_{i,j} Xi,j 及其局部邻域 P i , j P_{i,j} Pi,j 执行自注意机制。注意,对于边缘和角点像素,邻域大小分别为6和4。通过可学习的投影 M q M_q Mq、 M k M_k Mk 和 M v M_v Mv,我们为注意力机制准备了来自 P i , j P_{i,j} Pi,j 的key和value以及来自 X i , j X_{i,j} Xi,j的query。 最后,key、value和query组合成输出 X i , j X_{i,j} Xi,j(公式3)。

金字塔传播
局部自我注意块比较像素及其有有限距离 N t N_t Nt的邻居。但是,图像可能具有较大的篡改区域,这需要在相距很远的像素之间进行比较。我们不是简单地扩大N以获得更好的像素覆盖,而是迭代地应用我们的本地自注意块以金字塔结构传播信息。
如图4所示,紫色和橙色堆栈代表局部自注意块,紫色扩张距离为1,橙色扩张距离为3。通过自注意块,层1上的每个像素代表来自层0的9个像素; 层2上的每个像素代表来自层1的9个像素和来自层0的81个像素。通过适当设置的扩张距离,h层局部自我注意结构顶部的像素可以从底层达到 ( 2 N + 1 ) 2 h (2N+1)^{2h} (2N+1)2h像素。

金字塔设计有两个好处:
- 可以使用一个较小的N值,这使得每个自注意块的计算效率更高;
- 在上层,像素不仅表示自己,而且编码来自其局部区域的信息。 因此,通过比较那些像素,自我注意块比较来自两个不同补丁的信息。
块大小的分析:具有扩展距离{1,m,…, m h − 1 m^{h-1} mh−1}的h层m×m自注意块结构有助于与来自输入的大多数像素相关的输出像素,其中m=2n+1是每个自关注块的邻域大小。 最后一层中的每个像素覆盖输入特征上的 m h m^h mh× m h m^h mh区域。 因此,要覆盖S×S大小的图像,需要 h = O ( l o g m S ) h=O(log_mS) h=O(logmS)层。 由于每一层都需要进行 S 2 S^2 S2自注意计算,并且每个自注意块在时间和内存上都具有O( m 2 m^2 m2)复杂度,因此在可能的整数值中,相对于m的总复杂度为 O ( S 2 m 2 l o g m S ) O(S^2 m^2 log_m S) O(S2m2logmS),当m=2n+1=3时达到最小值。 3×3块不仅在相同的内存和时间预算下提供了最大的覆盖,而且提供了更多规模的比较。 在我们的SPAN实现中,我们采用了5层3×3的自关注块结构,扩展距离为1、3、9、27、81,如图2所示。 该结构在3,9,27,81和243五个不同的尺度上对相邻区域之间的关系进行了比较和建模。
框架训练
为了训练SPAN,我们冻结特征提取器,并以端到端的方式训练以下部分,在binary ground-truth mask监督下,使用1个标签篡改像素和0个标签真实像素。 我们采用二值交叉熵(BCE)作为我们的损失函数:

实验
数据集
使用Mantra-Net中提出的合成数据集进行训练和验证。另外四个流行的操纵检测基准用于微调和评估。
- Mantra-Net中提出的合成数据集
- NIST16
- Columbia
- Coverage
- CASIA
评价和比较
只进行预训练
比较SPAN和Mantra-Net在相同设置下的性能如表1所示,SPAN在Synval上的性能远远优于Mantra-Net。 在特征提取主干相同的情况下,SPAN能够更有效地建模不同块之间的空间关系,从而产生更好的定位精度。 与Mantra-Net相比,在AUC度量下SPAN模型也表现出了更好的性能,证明了我们提出的模型在不需要额外自适应的情况下对其他数据集具有良好的推广能力。
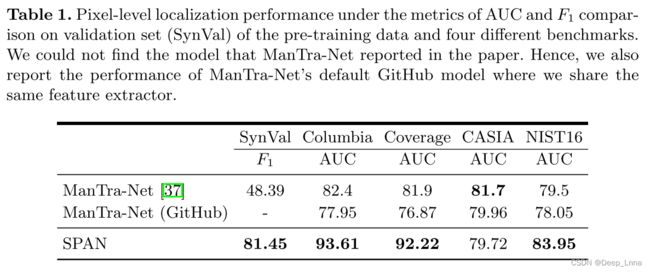
与Mantra-Net在Columbia和Coverage相比,SPAN在AUC实现了超过10%的性能收益。 在CASIA上的性能提升并不显著。 可能的原因有两个:
- Columbia和Coverage数据集的篡改区域和覆盖范围比CASIA数据集具有更多变化的尺度,我们的SPAN也得益于我们更有效的多尺度建模;
- CASIA样本的平均分辨率(256×384)低于其他数据集(NIST:2448×3264;Columbia:666×1002;覆盖范围:209×586)。 如表5所示,当测试图像的大小调整到较低分辨率时,Span和Mantra-Net之间的性能差距会减小。
预训练+微调
在微调设置下将 SPAN 与其他 SoTA 方法进行比较。如表 2 所示的结果表明,未经微调的 SPAN 在 Columbia 和 Coverage 上已经大幅优于 RGB-N 和其他方法,进一步证明我们的空间注意力模块具有强大的泛化能力。通过微调,所有四个数据集的性能都进一步提高。
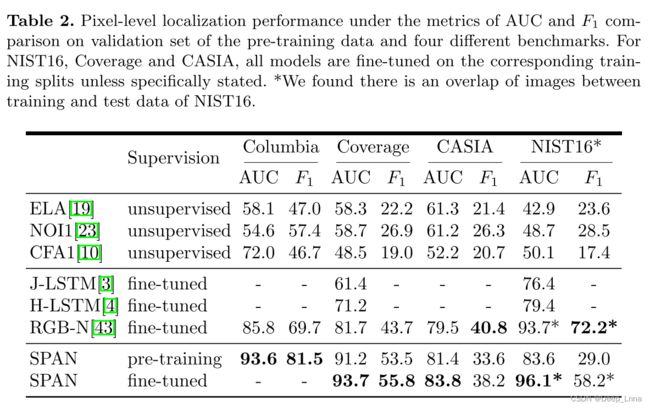
J-LSTM和H-LSTM也通过比较图像补丁进行预测。SPAN获得更好的性能的两个可能原因是: 1)J-LSTM和H-LSTM仅在单个尺度上查看补丁,这可能会限制它们检测到非常大或非常小的回火区域;2) J-LSTM独立处理补丁,并采用LSTM结构线性处理补丁,这可能会失去对这些补丁的空间和上下文信息的跟踪; H-LSTM试图通过沿着专门设计的Hilbert-Curve曲线路线引入补丁来缓解这一问题,但是线性LSTM仍然很难对空间信息进行显式建模。SPAN考虑了带有上下文和相邻像素的补丁,并且能够通过位置投影对空间关系进行建模。
篡改类型分析
在表3中,我们给出了在NIST16数据集上评估SPAN在不同操作类型上的性能。 为了进行比较,我们还通过直接评估Mantra-Net GitHub中提供的模型来生成每个类的结果。 在没有对NIST16进行微调(比较前两行)的情况下,我们的SPAN模型在所有三种操作类型上的表现都比Mantra-Net好,这表明我们提出的空间注意力模型是有效的,与篡改类型无关。 SPAN的结果可以通过适应这个特定的数据集来进一步改进。

消融实验
- 如何组合多尺度注意模块(卷积LSTM和残差连接(Res))不同层次的输出;
- 如何建立自我注意模型(位置投影(PP)和位置嵌入(PE))

实验表明,用PP代替PE作为位置建模,结合残差连接,在所有数据集上都实现了显著的性能改进。
鲁棒性实验
为了生成修改后的样本,我们在NIST16和Columbia上应用了标准的OpenCV内置函数arearsize、GaussianBlur、GaussianNoise、JPEGCOMPRESS。 SPAN显示了对压缩更健壮的性能,但对调整大小更敏感。

定性结果
图5显示了一些SPAN和Mantra-Net结果。 算例表明,在三种常见情况下,SPAN比ManTra-Net有更好的预测效果:1)假阳区域(真实物体被预测成虚假的)(蓝圈); 2)正确的操纵对象(绿圈)和3)噪声假阴性预测(橙色圆圈)。从上到下:操纵图像,ground-truth,ManTra-Net预测,SPAN预测和微调SPAN预测。 哥伦比亚数据集没有微调结果,因为哥伦比亚没有训练分裂。

总结
提出了一种空间金字塔注意网络(SPAN),该网络通过局部自注意块的金字塔结构在多个尺度上对块之间的关系进行建模,以检测和定位有或无微调的多种图像操作类型。 SPAN优于现有的模型。该方法在一般类型的操作检测和定位中具有较高的准确性和鲁棒性,表明在不同尺度上建立块的关系有助于捕获操作定位中的基本信息。 然而,在较低的图像分辨率下,SPAN可能不太有效。