【论文笔记】Attention-Based Two-Stream Convolutional Networks for Face Spoofing Detection
发布于IEEE Transactions on Information Forensics and Security
原文链接:https://ieeexplore.ieee.org/document/8737949
摘要
人脸欺骗攻击仍然是现代人脸识别系统的一个威胁。尽管已经提出了许多有效的反欺骗方法,但许多现有方法的性能会因光照而下降。
本文提出了一个双流卷积神经网络(TSCNN),它在RGB空间(原始成像空间)和多尺度Retinex(MSR)空间工作。RGB空间包含详细的面部纹理,但是对光照很敏感;MSR对光照不敏感,但它包含的面部信息不那么详细。此外,MSR图像能有效地捕捉到人脸欺骗的高频信息,对人脸欺骗检测具有较强的鉴别能力。为了有效地融合两个来源(RGB和MSR)的特征,本文提出了一种基于注意力的融合方法,它可以有效地捕捉两个特征的互补性。
在CASIA-FASD、REPLAY-ATTACK和OULU等多种数据集上效果很好,在跨数据集上也十分有效。
引言
背景
随着手机的普及,人脸识别系统的应用越来越普及,其安全性的弱点也越来越突出。 例如,由于社交网络的普及,在互联网上获取一个人的人脸图像来攻击人脸识别系统是非常容易的。 因此,人脸欺骗检测引起了人们的广泛关注,并在过去的几年里引发了大量的研究。
一般来说,人脸欺骗攻击主要有四种类型:照片攻击、掩蔽攻击、视频重放攻击和3D攻击。 由于掩蔽攻击和3D攻击代价较高,因此,照片攻击和视频重放攻击是最常见的两种攻击。 照片和视频重放攻击可以用用户在摄像机前的静态人脸图像和视频发起,这些图像和视频实际上是从真实图像中重新捕获的。 显然,在相同的捕获条件下,重获图像的质量比真实图像的质量要低。 低质量的攻击可能是由于缺乏高频信息、图像条带或云纹效应、视频噪声特征等。显然,这些图像质量下降因素可以作为区分真假人脸的有用线索。
人脸欺骗检测,也称为人脸活性检测,被设计用来对抗不同类型的欺骗攻击。 人脸欺骗检测通常是人脸识别系统的一个预处理步骤,用来判断人脸图像是从真人还是从打印的照片(回放视频)中获取的。 因此,人脸欺骗检测实际上是一个二分类问题。针对人脸欺骗攻击,国内外研究文献主要有四种方法:(1)基于微纹理的方法,(2)基于图像质量的方法,(3)基于运动的方法,(4)基于反射率的方法。
方法的提出
本文提出了一种新的基于深度学习的微纹理(MTB)方法。现有的MTB方法通常是在原始RGB颜色空间中对输入图像进行处理和分析。 然而,RGB图像对光照很敏感。 在光照条件下,基于RGB的MTB方法可能会降低其性能。 这促使我们开发一种光照鲁棒的MTB方法。 因此,我们提出了一种在两个互补空间上训练的双流卷积神经网络(TSCNN):RGB空间(原始空间)和多尺度Retinex(MSR)空间(光照不变空间)。
RGB和MSR图像都包含鉴别信息:RGB图像可以用来训练端到端鉴别CNN进行欺骗检测; MSR可以捕获高频信息,并且这些信息对欺骗检测特别有效。 其次,RGB和MSR图像具有互补性:RGB空间包含了人脸的详细信息,但对光照敏感; MSR对光照不敏感,但包含较少的细节面部信息。 在TSCNN框架下,将RGB和MSR图像分别传送到两个CNN(TSCNN的两个分支),生成两个具有鉴别能力的特征,用于反欺骗。 为了有效地融合这两个特征,我们提出了一种基于学习的融合方法,该方法受注意机制的启发。 除了常用的融合方法,如特征平均融合,我们的基于注意力的融合可以自适应地对特征进行加权,以获得良好的融合性能。 图1显示了RGB和MSR的互补性以及特征融合的重要性。图中表示的是RGB(第2栏)和MSR(第4栏)的单独特征得分和融合后的得分(第5栏)。与单个分数相比,融合后的分数有所提高。

主要贡献
- 本文是第一个研究融合RGB和MSR进行人脸反欺骗的;
- 本文提出了基于注意力的融合方法,该方法可以使TSCNN很好地适用于各种光照条件下的图像;
- 本文使用此方法对三个流行的反伪造数据库:CASIA-FASD、REPLAYATTACK和OULU进行评估。结果显示了所提策略的有效性。此外,在跨数据集实验上的效果也非常具有竞争力。
方法
在这一部分中,首先介绍了Retinex的理论,解释了MSR图像具有鉴别性的原因。 然后,分析了RGB和MSR特征的互补性,并详细介绍了所提出的TSCNN。 最后介绍了基于注意力的特征融合方法。
MSR
多尺度视网膜(Multi-Scale Retinex)
本文应用MSR是因为:
- MSR能够将图片的光照成分和反射成分分离,将光照成分去除利用反射信息做活体检测;
- MSR可以作为一个高通滤波,保留 real和fake faces 之间有分辨力的高频信息
假设:Retinex理论是基于这样一个假设,即物体的颜色是由不同波长的光的反射能力决定的。 物体的颜色不受不均匀照明的影响。 该理论将源图像S(x,y)分为反射率R(x,y)和照度L(x,y)两部分。 特别地,R(x,y)和L(x,y)包含频率的不同分量。 R(x,y)侧重于高频分量,而L(x,y)倾向于低频分量。 公式(1)表示Retinex:
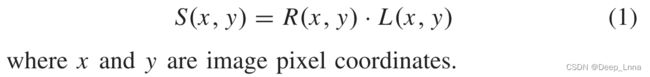
动机:L(x,y) 和 R(x,y) 分别代表光照和反射率(我们任务中的面部皮肤纹理)分量。 L(x,y)是由光源决定的,而R(x,y)是由被捕获物体表面的性质决定的,即我们应用中的脸。 光照与包括人脸欺骗检测在内的大多数分类任务明显无关,因此光照与反射率(纹理)的分离非常重要,因为分离后的反射率只能用于光照不变分类。 由于Retinex理论旨在进行这种分离,因此本文将Retinex用于光照不变人脸欺骗检测。
计算:为方便计算,公式 (1)通常转化为对数域:

由于s(x,y)是原始图像的对数形式,我们可以通过估计l(x,y)来计算Retinex输出r(x,y)。 因此,Retinex的性能由l(x,y)的估计决定。
下图的每个块代表一个SSR模块。 将所有SSR模块的输出与标度参数加权形成MSR。
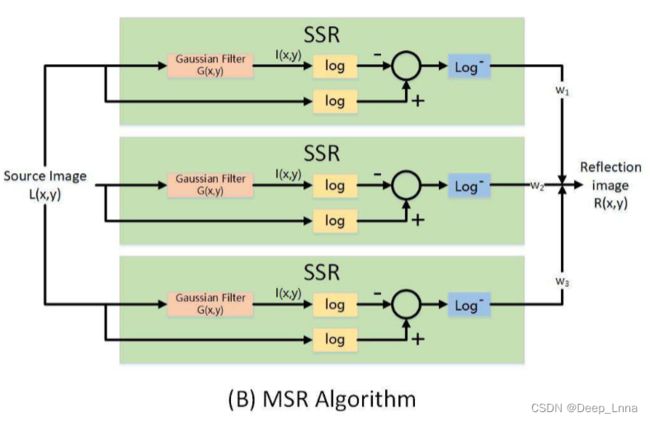
公式如下:
其中,G(x,y)是高斯滤波函数。
总结:MSR的优点:(1)MSR可以分离照度和反射率。(2)保留高频信息,利于检测
双流卷积神经网络(TSCNN)
以离线的方式将原始RGB图像转换为MSR图像。 两个图像源(RGB和MSR)分别馈入两个CNN进行端到端的训练,同时存在交叉熵二值分类损失。 学习到的两个特征(来自RGB和MSR图像)然后学习融合使用注意机制。
RGB和MSR图像的互补性:RGB颜色空间通常用于彩色图像的捕获和显示。 使用RGB图像的优点是:RGB图像能够自然地捕捉到细节的面部纹理,对欺骗检测具有鉴别性。 然而,RGB图像的缺点是对光照变化非常敏感。 其内在原因是RGB空间中三个颜色通道之间具有很高的相关性,使得亮度和色度信息难以分离。 由于现实世界中人脸图像的亮度条件不同,亮度(光照)和色度(肤色)的分离比较困难,从RGB空间学习的特征往往会受到光照的影响。
MSR算法可以实现光照不变的人脸图像。 因此,MSR人脸图像在不受光照影响的情况下,保留了面部皮肤的微观纹理信息。 MSR图像除了具有光照不变的优点外,还可以产生鉴别信息,用于欺骗检测。 具体来说,MSR算法去除原始图像中的低频成分(光照),留下高频成分(纹理细节)。 然而,高频信息对于恶搞检测具有鉴别性,因为真实人脸具有丰富的面部纹理细节,而假人脸,尤其是重新捕获的人脸,丢失了一些此类细节。
双流体系结构:本文提出了一个双流卷积神经网络(TSCNN),如下图所示。

TSCNN由两个输入不同的相同子网络(RGB和MSR图像)组成,在两个子网络的最后一个卷积层提取RGB和MSR图像的学习特征。 给定一幅输入图像/帧,使用MTCNN进行人脸和地标检测。 然后利用仿射变换对检测到的人脸进行对齐。 RGB流对从视频序列中提取的单个RGB帧进行操作。 对于MSR流,单个RGB帧(首先处理到灰度)被转换为MSR图像。 然后MSR图像被馈送到MSR子网络进行训练。 每个流都基于相同的网络,在本工作中,使用了两个成功的网络(MobileNet和Resnet-18)。 为了有效地融合来自两个流的特征,提出了一个基于注意力的融合块。
引入了四元组 M = ( E R G B , E M S R , F , C ) M=(E_{RGB},E_{MSR},F,C) M=(ERGB,EMSR,F,C),其中 E R G B E_{RGB} ERGB和 E M S R E_{MSR} EMSR分别是RGB和MSR流的特征提取器。 F是融合函数,C是分类器。 特征提取器是一个映射E:I→f,它获取输入图像(RGB或MSR)I并输出D维特征F。 提取的特征 f R G B f_{RGB} fRGB和 f M S R f_{MSR} fMSR都必须具有相同的D维数才能兼容早期(特征)融合。 特别地, f R G B f_{RGB} fRGB和 f M S R f_{MSR} fMSR可以通过不同的提取器(CNNs)得到,但特征维数应该是相同的。
融合函数F将 f R G B f_{RGB} fRGB和 f M S R f_{MSR} fMSR融合为融合特征v:

然后将融合的特征输入到分类器C中。因此,TSCNN可以表述为一个优化问题:

Backbone深度网路:人脸反欺骗数据集非常小,并且在单一的环境中捕获,容易导致过拟合。为了克服过拟合和提高许多计算机视觉任务的性能,从大型图像分类数据集(通常是ImageNet)中进行模型优化/预训练。使用了两个预训练Backbone,即MobileNet(更轻,精度更低)和Resnet-18(更重,精度更高)用于欺骗检测。采用二分类交叉熵损失即公式10进行二值分类(真实人脸与虚假人脸)。

基于注意力的特征融合
在许多计算机视觉任务中,特征融合是提高性能的重要手段。 不恰当的融合方法会使融合后的特征比单个特征效果更差。 在深度学习时代,通常使用的融合方法包括分数平均、特征串联、特征平均、特征最大池化和特征最小池化。 在我们的反欺骗任务中,我们发现这些融合方法不能深入挖掘来自不同来源的特征之间的相互作用,因此,我们提出了一种基于注意力的融合方法,如下图所示。

给定一组特征{ f i f_i fi, i = 1, …, N},我们尝试学习一组对应于特征的权重{ w i w_i wi, i = 1, …, N}来生成聚合特征v ,本问题中,融合的特征是 f R G B f_{RGB} fRGB和 f M S R f_{MSR} fMSR :
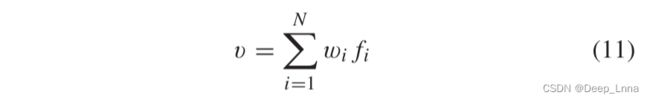
除了直接学习 w i w_i wi之外,我们还学习一个与 f i f_i fi 具有相同维度的核 q,q 用于通过点积过滤特征向量:

过滤器生成一个向量,该向量表示相应特征的重要性,命名为 d i d_i di ,用于将重要性转换为权重 。我们将 d i d_i di传递给 softmax 算子并获得所有正权重 w i w_i wi:

滤波器内核 q 很容易通过标准反向传播和随机梯度下降进行训练。
实验
基准数据集
- CASIA人脸反欺骗数据集(CASIA FASD):分为训练集和测试集,训练集由20名受试者组成。如图3,从上到下:低,正常和高质量图像。 从左到右:真人脸和扭曲照片,剪切照片和视频回放攻击。

- REPLAY-ATTACK数据集:由50个客户的真实访问和攻击的视频记录组成。如图4,分为受控场景和不利场景的图像,第一行是受控(光源可控),第二行是光源受限情况。
还设计了三种类型的攻击:
(1)打印攻击。高分辨率的图片被打印在A4纸上,并由相机重新捕捉;
(2)移动攻击。高分辨率的图片和视频被显示在iPhone 3GS的屏幕上,并被相机重新捕捉;
(3)高清攻击。图片和视频都显示在分辨率为1024×168的iPad屏幕上。

- OULU-NPU数据集:攻击数据库由4950个真实访问和攻击视频组成。如图5,分为受控场景和不利场景的图像,第一行是受控(光源可控),第二行是光源受限情况。NPU数据库中考虑的攻击类型是打印和视频重放。这些攻击是使用两台打印机(打印机1和2)和两台显示设备(显示器1和2)进行的。

评价指标
FAR:误识率,把不应匹配的匹配了
FRR:拒识率,把应该匹配的排除了
ERR:测试集上的相等错误率,该值表明错误接受的比例等于错误拒绝的比例。等错误率值越低,生物识别系统的准确度越高。
HTEP:测试集上的半数总错误率,同样是越小越好。
TPR:将正例分对的概率
FPR:将负例错分为正的概率
ROC曲线:反映了FAR、FRR关系,越偏向左上角效果越好。
在CASIA-FASD数据集的实验
训练集训练和调整模型参数,并在测试集上以等错误率 (EER) 的形式报告结果;数据库中的原始输入图像/帧转换为 MSR 图像。然后将不同颜色空间的图像分别输入到我们的 TSCNN 中;尽管RGB最常用,为了对比不同颜色空间的影响,比较了三种颜色空间:RGB、HSV和YCBCR的性能。 基于MobileNet和Resnet-18的欺骗检测结果(EER,越低越好)如表I所示。

ROC曲线如下图所示。
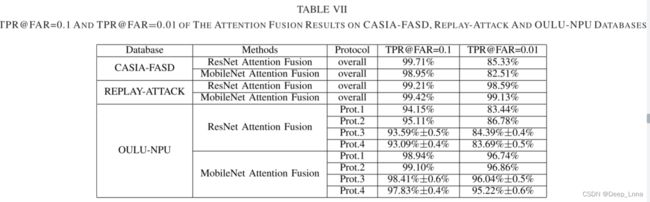
TPR@FAR=0.1和TPR@FAR=0.01的注意力融合结果如表VII所示。
结果:
- 从七个场景的结果来看,RGB和YCbCr在使用ResNet-18和MobileNet时的性能普遍优于HSV颜色空间。 RGB和YCbCr的结果非常相似。
- 在MobileNet和ResNet-18中,RGB、HSV和YCbCr功能均优于MSR功能(4.931%、5.134%和5.091%对9.531%)和ResNet-18功能(3.437%、4.831%和3.635对7.883%)。
- MobileNet(4.175%vs5.061%和4.339%)和ResNet-18(3.145%vs4.661%和4.761%)的MSR与RGB特征融合效果优于MSR与HSV、MSR与YCbCr。
- 在MobileNet上,MSR和RGB的融合效果优于单独的融合(融合率4.175%,RGB为4.931%,MSR为9.513%)。 对于ResNet-18融合也可以得出同样的结论。 至于RGB优于HSV和YCbCr的原因,我们认为MSR起到了减少光照影响的作用,而RGB则试图保留面部细节纹理。 但是HSV和YCBCR都是基于亮度和色度的分离,不能有效地与MSR进行融合。 验证了RGB和MSR图像的互补性。
- 从表VII中可以看出,使用Resnet的CASIA-FASD的总体结果(99.71%和85.33%)优于使用MobileNet的CASIA-FASD(98.95%和82.51%)。
在REPLAY-ATTACK和OULU-NPU的实验
表2是在REPLAY-ATTACK上的表现。我们可以看到MSR和RGB的融合在EER方面比单独的效果好;并且与LBP算法进行对照,可以看到效果比LBP算法好;此外,我们可以看到这种进一步的融合比ResNet融合更好,但比MobileNet融合略差。

为了进一步验证RGB和MSR融合对光照变化的有效性,我们在包含两种光照条件的REPLAY-ATTACK数据库上进行了实验:(1)均匀背景和荧光灯照明的受控条件,(2)背景和光照不均匀的不利条件。 为了讨论对光照的改进,我们将数据库分为不利光照和受控光照两部分,分别进行实验。 从表III和图7-(a),MSR特征在不利光照(更强的光照)下比RGB特征有更好的结果,显示了MSR在强光下的鲁棒性。 另一方面,RGB在控制光照(接近中性光照)方面优于MSR特征,表明RGB在中性光照下具有很强的保持纹理细节的能力。 融合后的结果在逆光和受控光照下都得到了改善。 因此,MSR和RGB的融合可以有效地处理各种光照,提高系统的性能。


对于OULU-NPU数据库:我们在开发集中表示EER,在测试集中表示APCER、BPCER和ACER。 表4和表7显示了基于MobileNet和ResNet-18的RGB、MSR和融合特征的结果。 在ACER和EER方面,我们可以看到RGB和MSR的融合比单独的表现更好。 对于四种协议中的大多数结果,特征融合显著优于单个特征。 特征融合的一致改进表明了RGB和MSR两种信息源使用的有效性。 如表2和表4所示,流行的网络(MobileNet和ResNet-18)在REPLAY-ATTACK和OULU-NPU数据库上取得了竞争性的性能。


基于注意力的融合结果
如上所述,RGB特征主要集中在所有频率上的面部皮肤的微观纹理,而MSR特征集中在高频上,减少了光照的影响。 表I、表II和表IV验证了这两种特征(RGB和MSR)融合的有效性。 下面进一步探讨这种有效性。
首先,我们通过可视化展示了一些定性的结果。 相对于平均特征融合对不同特征进行平均加权,注意力融合具有自适应地对特征进行非对称加权的灵活性。 因此,我们的基于注意力的融合有可能获得更好的权值,从而获得更好的性能。 图8-(a)显示了我们基于注意力的融合方法的这种不对称加权机制。 图8-(a)中的样本选自REPLAY-ATTACK数据库,该数据库涵盖两种成像亮度条件:不利光照(不均匀、复杂光照)、受控光照(均匀、中性光照)。 从图8中的样本,我们可以看到MSR和RGB的权重是自适应不对称的。 由于MSR图像比RGB图像具有更强的光照不变性,因此在不利(不均匀、复杂光照)光照下,MSR图像的权值高于RGB图像。 在控制光照下,不出所料,RGB图像获得了更高的权重。 图8(b)显示了一些在不同光照下具有三个分数(RGB,MSR,它们的融合)的样本。 我们可以看到一些样本在单个RGB或MSR评分上失败,但融合结果导致了正确的识别,表明了RGB和MSR融合的有效性,尤其是在各种光照下。

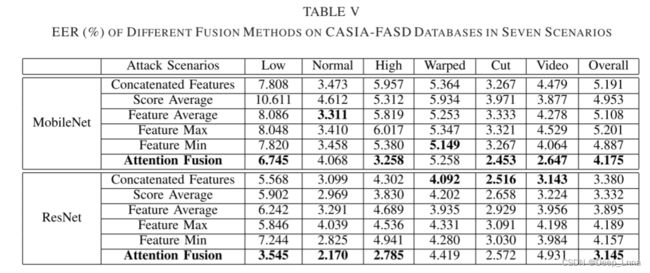
将所提出的基于注意力的融合方法与一些流行的特征融合方法进行了比较,包括分数平均法、特征串联法、特征平均法、特征最大池化法、特征最小池化法和所提出的注意力方法。 针对不同的数据库分别给出了融合结果。 表5显示了CASIA-FASD在七种情况下的结果。
此外,图7-(b)显示了使用MobileNet的流行特征融合方法的ROC曲线。

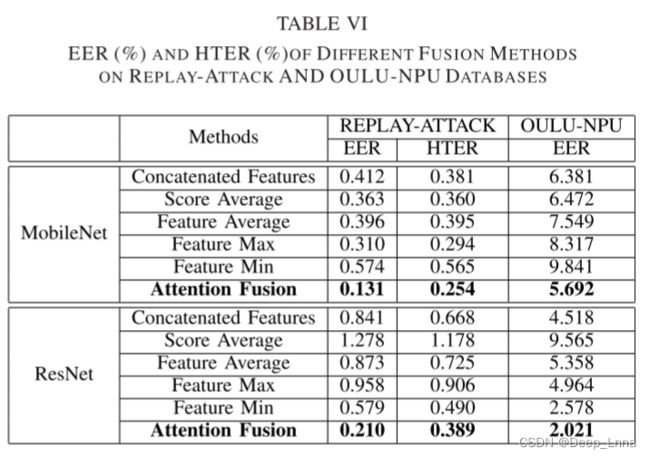
本文提出的基于注意力的融合方法在所有其他场景(总体)中均获得了4.175%(MobileNet)和3.145%(ResNet-18)的最低EER,显示了我们的融合方法与其他融合方法相比的优越性。 对于MoblieNet和ResNet-18,第2和第3性能最好的融合方法分别是{'feature min’和’score average‘}和{'score average’和‘级联feature’}。 表6显示了REPLAY-ATTACK和OULU-NPU的融合结果。 我们可以看到,在REPLAY-ATTACK(EER和HTER)和OULU-NPU(EER)上,我们的基于注意力的融合比其他所有融合方法都要好。 基于注意力的融合能够自适应地对RGB和MSR特征进行加权,从而获得了良好的性能。
与SoTA对比
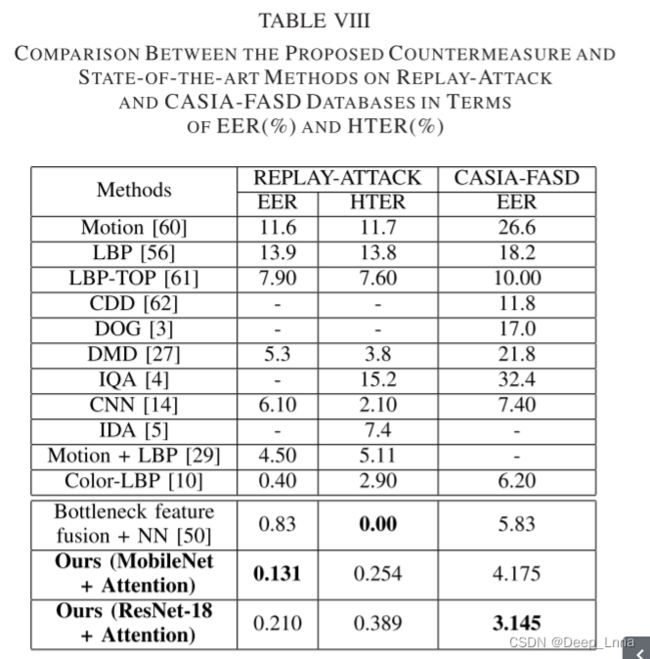
表8是就EER(%) 和HTER(%) 而言,在REPLAY-ATTACK和CASIA-FASD数据库上与最新方法之间的比较
下表9是在 EER (%)、APCER (%)、BPCER (%) 和 ACER (%) 方面对 OULU-NPU 数据库和最先进的方法进行比较。
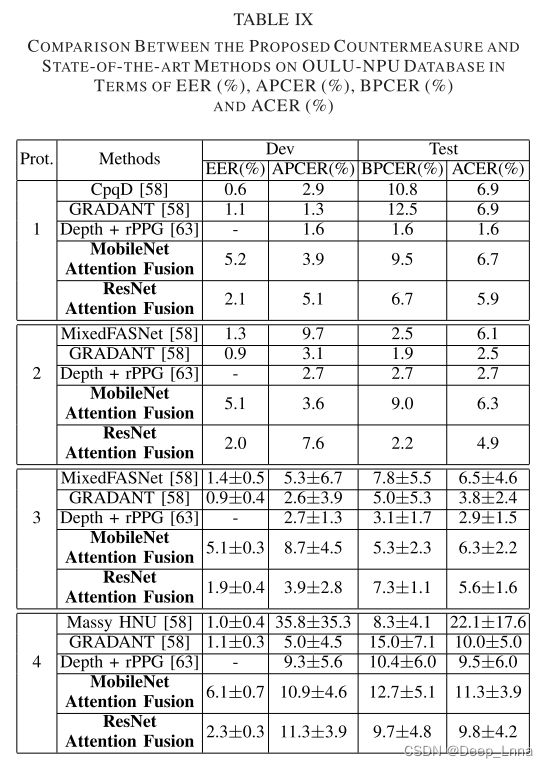
总之,我们的方法可以在所有三个基准数据库中实现非常强的性能,显示了所提出的方法的优点。
跨数据库比较
不同数据库的欺骗面孔是在不同环境(例如照明)下使用不同设备捕获的。我们在 CASIA-FASD 和 REPLAY-ATTACK 之间进行了跨数据库评估。更具体地说,跨数据库就是在一个数据库上训练和调优分类器,在另一个数据库上进行测试。系统在这种情况下的泛化能力通过在验证集和测试集上获得的 HTER 来体现。每次都使用 CASIA-FASD 或 REPLAY-ATTACK 对对策进行训练和调整,然后在其他数据库上进行测试。结果报告在表 X 中,与这种跨数据库方式的最先进技术进行了比较。

由于数据库之间的域转移 (不同的成像环境),所有反欺骗方法的性能都会下降。与最先进的方法相比,我们的方法 (MobileNet + 注意力) 达到了第二好的性能 (30.0% 和33.4%),比最好的方法(27.6% 和28.4%) 相比稍差。但是,Depth+rPPG使用了比我们的方法更多的辅助信息 (3D面部形状,rPPG信号)。
为了探索跨数据库评估中性能下降的原因,我们考虑标准分布距离度量,最大均值差异 (MMD)来测量源特征和目标特征分布之间的距离域偏移。
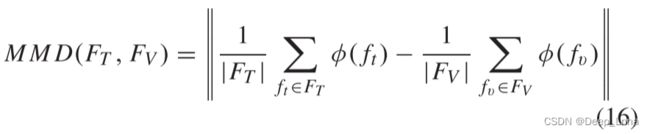
如上式所示,我们定义了一个表示 φ(),它对训练数据特征 f t ∈ F T f_t ∈ F_T ft∈FT 和验证数据特征 f v ∈ F V f_v ∈ F_V fv∈FV 进行操作。 MMD 值越大,域偏移越大。实验结果如下所示。

- 当我们在同一数据库上训练测试一下时,MMD小于在MobileNet和ResNet-18的不同数据库上训练和测试一下。
- 由于CASIA-FASD有七种情况,因此当我们在CASIA-FASD数据库上进行训练并在REPLAY-ATTACK数据库上进行测试时,MMD大于在REPLAY-ATTACK训练和CASIA-FASD数据库上测试一下的MMD。
- RGB和MSR功能的融合降低了MobileNet和ResNet-18的跨数据库的MMD。
总结
在本文中,我们提出了一种基于注意的两流卷积网络,用于人脸欺骗检测,以区分真实和假人脸。提出的方法应用通过CNN模型 (MobileNet和ResNet-18) 提取的互补特征 (RGB和MSR),然后采用基于注意力的融合方法来融合这两个特征。自适应加权特征在各种照明条件下包含更多的判别信息。
我们在三个具有挑战性的数据库(即 CASIA-FASD、REPLAY-ATTACK 和 OULU-NPU)上评估了我们的人脸欺骗方法,这表明了数据库内和数据库间的竞争性能。融合方法的实验表明,注意力模型可以在特征融合方面取得可喜的成果。跨数据库评估显示了 RGB 和 MSR 信息融合的有效性。