Windows 10 python 3.9安装运行Mockingbird--拎包入住功略
首先说明一下,什么是拎包入住。这是因为本人python不精通,机器学习等AI也只是只其然不知其所以然,一句话就是:我只有照搬现成ai库使用,没有调整算法和优化模型的能力,所以只能用别人创建好的代码使用,就象建好的房子我直接住一样:-)。感谢github和开源社区的大牛们。
mockingbird是一个AI模拟声音的开源python库,可以用你自己的录音或音频文件,在其预置的模型支持下,生成模拟录音者的声音。关于mockingbird的介绍请参考gighub里的这篇文章。MockingBird/README-CN.md at main · babysor/MockingBird · GitHub
或者:这篇文章https://gitee.com/Dwesome/MockingBird
提前说明:文章中很多windows命令行指令,我都在其前面加了conda环境名和目录名,目的是要指名相应的指令需要在什么样的conda环境和目录中执行,减少文字说明的模糊性。
一、windows10下python环境的准备
在安装mockingbird之前,需要准备python环境,由于pip search RPC功能被永入关闭,所以安装一个conda来管理虚拟环境还是有必要的。我这里选择的是Miniconda。
1、首先为mocingbird准备一个3.9环境,3.7我试了不行。3.10网上有人反馈也不行,是否是这样大家自己验证。但做为搬家者,最喜欢的方式还是“拎包入住”,建议大家还是先用3.9搭一个能用的再试别的吧。
我的miniconda安装在E:\miniconda之下,一般新建的envs也就在此目录的E:\miniconda\envs之下。
创建新环境:
conda create -n mockingbrid python=3.9请使用下面的指令,查看地一下自己的conda环境设置,这对了解你电脑上conda和pip配置环境有帮助。
conda info -a
pip config list -v2、关于conda包的缓存和PIP包的缓存位置
由于conda 和PIP都有喜欢在%appdata%下保存缓存包的恶习,所以,在安装大型AI训练模型时,建议我们把pkgs缓存的位置挪到空间比较充裕的硬盘分区去。
conda的包缓存和虚拟环境目录更改,需要编辑电脑上%homedirve%%homepath%下的".condarc"文件。
我的这个文件位置如下:
c:\user\admin\.condarc我的.condarc的内容如下,可以先备份你自己的原文件,然后将下面内容贴进.condarc
channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch-lts: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
envs_dirs:
- E:\MiniConda3\envs
- C:\Users\admin\AppData\Local\conda\conda\envs
- C:\Users\admin\.conda\envs
- C:\ProgramData\Anaconda\Miniconda3\envs
pkgs_dirs:
- E:\MiniConda3\pkgs
- F:\Miniconda\CondaPkg
- C:\Users\admin\AppData\Local\conda\conda\pkgs
- C:\Users\admin\.conda
- C:\ProgramData\Anaconda\Miniconda3\pkgspip的缓存包位置更改:我将位置搬到了E:\PythonTools\pip\pipcache。
pip config set global.cache-dir "E:\PythonTools\pip\pipcache"
pip config set global.index-url "https://pypi.tuna.tsinghua.edu.cn/simple"
pip config set install.trusted-host "pypi.tuna.tsinghua.edu.cn"二、按步就班安装mockingboid
1、首先下载github最新版本的mockingbird的master包
https://github.com/babysor/MockingBird/archive/refs/heads/main.zip。注意,这个包gitee.com上的版本有可能和github.com上的版本并不完全同步,所以,还是直接去github.com上去下载。
将下载的main.zip文件解压到一个单独的目录,我是解压到conda的虚拟环境里,解压缩后文件目录为:
E:\MiniConda3\envs\mockingbird\MockingBird-main2、安装pytorch
这里要注意,pytorch有两个版本cpu版和cuda版。cuda版是在你的计算机上安装了nvida支持cuda功能显卡的情况下,可以使用的版本,这是利用gpu浮点运算能力加速模型训练的版本。据我自己这台笔记本电脑的配置而言,cuda的训练整是cpu的3-4倍,网上有人说10倍,这是nvida显卡型号和显存大小相关的。
打开pytorch网站:Start Locally | PyTorch,选择你需要的pytorch版本,然后复制本文图片中用红框标记的conda安装命令。

想要看看自己的电脑上有没有支持cuda的显卡,可以在windows命令行中运行下述使命:
nvidia-smi这个命令运行成功,且显示如下相似结果,说明你的机器上有支持cuda的显卡。如果没有成功,则有两个可能,一是没有安装nvidia显卡的cuda驱动,二是显卡不支持cuda。

注意cuda version 11.8,这个在选择后pytorch的cuda版本时要用到。
现在,进入先前已经创建的mockingbird环境,运行从pytorch网站上复制的conda安装命令。
(base) C:\Users\admin>conda activate mockingbird
(mockingbird) C:\Users\admin>conda install pytorch torchvision torchaudio pytorch-cuda=11.7 -c pytorch -c nvidia注意,pytorch网站上截止本文发搞之日,pytorch cuda版本支持11.7。而nvidia显卡的cuda驱动已经升级到11.8。没关系,下载这个就行!
这里着重要说明一件事,如果你使用了清华的conda和pip镜像,则cuda版本下载不会成功,或者下载的是cpu版本。这时候,我的方法是直接下载pytorch上的cuda安装包到本地目录,比如e:\cudatmp ,下载地址为:https://download.pytorch.org/whl/cu117/torch-1.13.0%2Bcu117-cp39-cp39-win_amd64.whl
在完成上述命令行安装的基础上,使用pip安装wheel包:
pip install e:\cudatmp\torch-1.13.0+cu117-cp39-cp39-win_amd64.whl3、安装ffmpeg

下载图中标记链接下的ffmpeg,解压缩到一个独立文件夹,并且加此文件夹加入到windows环境变变量PATH之中。并确保在命令行中输入ffmpeg命令后,显示正确:

4、安装mockingbird
在conda的mockingbird环境中,进入已经下载被解压缩的mockingbird目录,也就是第1步中解压缩后的目录,我的目录是E:\MiniConda3\envs\mockingbird\MockingBird-main,然后输入以下命令安装依赖包:
(mockingbird) E:\MiniConda3\envs\mockingbird\MockingBird-main>pip install -r requirements.txt5、安装 webrtcvad
(mockingbird) E:\MiniConda3\envs\mockingbird>pip install webrtcvad-wheels三、安装社区预先训练好的合成器
使用预先训练好的合成器,可以让拎包入驻者尽快感受语音模拟的乐趣,并且给你的朋友一个惊喜。
我建议下载 https://pan.baidu.com/s/1iONvRxmkI-t1nHqxKytY3g 百度盘链接 4j5d 以及
https://pan.baidu.com/s/1PI-hM3sn5wbeChRryX-RCQ 提取码:2021
这两个文件包加起来超过1.3G,为了下载这两个文件,我忍痛开了一个月的“喂挨劈”...
将下载下来的的pretrained-11-7-21_75k.pt 复制到 conda环境中 \MockingBird-main\synthesizer\saved_models目录中。我的位置如下。
E:\MiniConda3\envs\mockingbird\MockingBird-main\synthesizer\saved_models>将下载的“Realtime-Voice-Clone-Chinese训练模型”文件夹中vcoder、encoder、synthesizer子目录中的文件复制到conda环境中 \MockingBird-main的对应文件夹中,我的目录分别如下:
(mockingbird) E:\MiniConda3\envs\mockingbird\MockingBird-main\vocoder>
(mockingbird) E:\MiniConda3\envs\mockingbird\MockingBird-main\synthesizer>
(mockingbird) E:\MiniConda3\envs\mockingbird\MockingBird-main\encoder>四、CUDA驱动下载
如果计算机上有支持cuda的显卡,则还需要下载不低于cuda11.7版本的驱动程序,网址:CUDA Toolkit 11.8 Downloads | NVIDIA Developer,当前版本为11.8,下载它没有问题,下载地址:
https://developer.download.nvidia.com/compute/cuda/11.8.0/local_installers/cuda_11.8.0_522.06_windows.exe这个文件包中包含显卡的最新驱动程序和cuda11.8支撑库,在安装过程中最好选自义安装,将安装位置调整到除C分区之外的分区,另外如果不需要visual studio支持,可以在选项中去掉。
五、运行测试环境
1、运行demo_toolbox.py
这个文件在conda环境中的\MockingBird-main文件夹内,如果安装一切顺利,且相关依赖包版本正确,那下述命令执行后弹出一个新的窗口。
E:\MiniConda3\envs\mockingbird\MockingBird-main>python demo_toolbox.py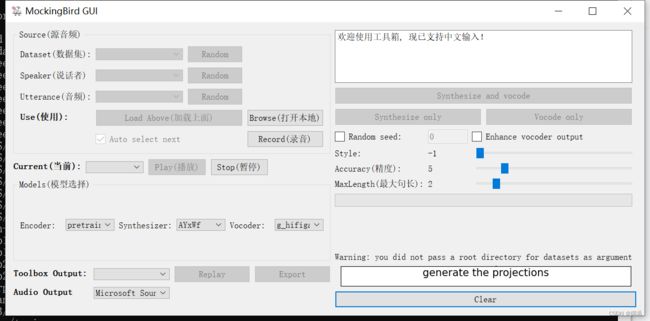
(1)点击Browse按钮选择已经录制好的自己的语音文件,或者直接点击Record即时录音。此时在Current下拉列表中会出现选择的语音文件或即时录音文件。
(2)Encoder列表中使用默认的pretrainted,Synthesizer列表中选择pretrainted75k,vocoder列表中选择pretrainted,然后点击Synthesizer and vocode按钮。完成合成之后,会播放合成语音。合成语音的效果要多尝试几次,也可以调整Style、Accuracy、Maxlength这三个参数,直到合成的mel spectrogram图形有明显的波段形状。
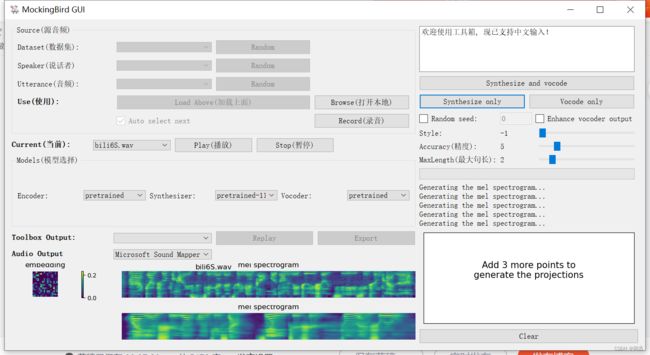
合成的技巧可以参考https://gitee.com/Dwesome/MockingBird#https://gitee.com/link?target=https%3A%2F%2Fdrive.google.com%2Ffile%2Fd%2F1H-YGOUHpmqKxJ9FRc6vAjPuqQki24UbC%2Fview%3Fusp%3Dsharing
(2)运行web.py
web.py提供模拟和训练等全部功能的web操作界面。运行后会打开一个web服务器,并在命令行中显其服务地址,在浏览器中输入服务器地址并打开页面。
(mockingbird) E:\MiniConda3\envs\mockingbird\MockingBird-main>python web.py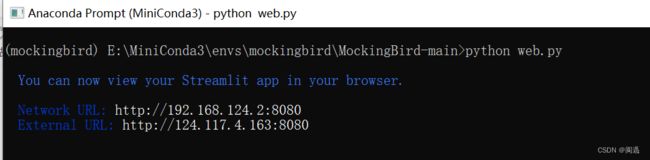
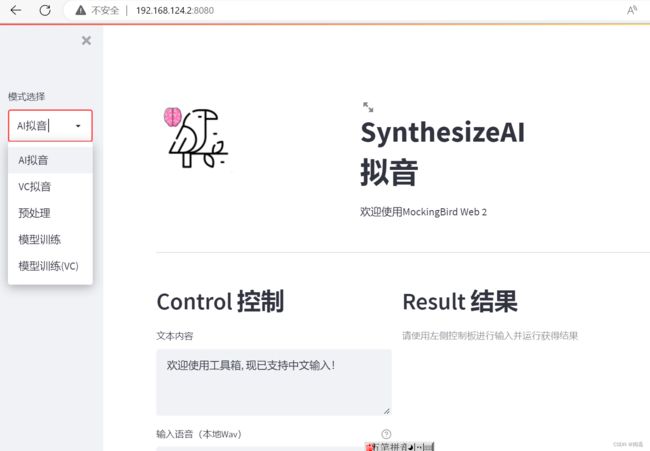
六、模型训练
网上的模拟训练介绍很多不太清晰,我在测试环节折腾了好久,尤其是GPU测试,可以说即要谢谢网络,也要吐槽网络。下面说一上我的环境配置过程
1、下载aidatatang_200zh训练包。
这个包17.4G,仅仅解压缩train目录里的内容,需要15G,而SV2TTS目录则需要26.3G。所以我是直接外接一个USB绿联硬盘盒做为训练数据存储区。解压缩的时候,要先解压aidatatang_200zh.tgz为aidatatang_200zh.tar,再解压aidatatang_200zh.tar到aidatatang_200zh目录,再进入aidatatang_200zh\corpus\train目录,将其中的所有tar压缩包解压到train目录本身中,解压完,那些压缩包就可以删除以腾出磁盘空间。我的计算机在解压缩花费的时间我已经忘记,反正是睡了一觉、只了顿饭之后,才解压缩完。aidatatang_200zh训练包被解压后放置在usb硬盘的G:\mocking文件夹中,其目录为:
G:\MOCKING
├─aidatatang_200zh
│ ├─corpus
│ │ ├─dev
│ │ ├─test
│ │ └─train
│ │ ├─G0013
……
│ │ ├─G6985
│ │ ├─G7009
│ │ └─G7072
│ └─transcript
└─SV2TTS
└─synthesizer
├─audio
├─embeds
└─mels2、先用web.py做模型训练
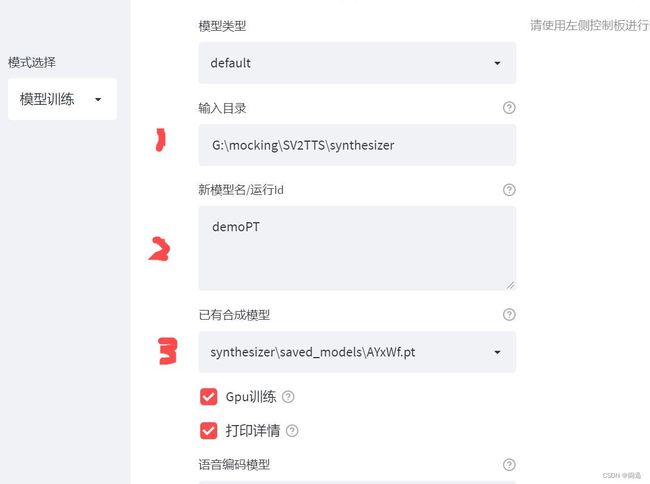
页面中:
1的位置,必须填写aidatatang_200zh的父目录下的SV2TTS目录,我的计算机上就是USB移动硬盘的G:\mocking\SV2TTS目录。
2的位置,如果你要新建一个训练项目,则在此输入一个新的名称,如果你要使用已经有的训练项目,则此项因为空。
3的位置,如果你要用已有的项目,则在下拉列表中选择,其中你自己如果已经有了自定义训练集,也会显示在列表中。注意,你的自定义训练集被存放在你的conda环境的MockingBird-main\synthesizer\saved_models文件夹中。训练集需要空间1G。
在GPU训练之前打勾,如果你的GPU支持,并且驱动及环境变量设置正确,系统将会用GPU进行训练,如果不支持GPU,则会使用CUP训练。
其他项目选择默认参数不变。现在点击训练按钮开始训练。
3、观察训练输出

注意图中红色方框中的内容,我的机器正确配置了GPU训练模式,所以训练设置指示是CUDA。否则就是CPU。
4、GPU的配置
(1)设置正确的环境变量
如果GPU和CUDA驱动安装正确,且nvidia-smi运行结果显示Cuda11.8和内存无误,则要记下gpu的编号,我的计算机只有一个nvidia显卡,且编号是0。如果你的计算机有多张支持CUDA的显卡,则也要记下它们的编号。
在mockingbird环境中设置环境变量set CUDA_VISIBLE_DEVICES=0。如果是多张卡,则可以是“set CUDA_VISIBLE_DEVICES=0,1,3”。显卡编号用逗号分开。
(mockingbird) E:\MiniConda3\envs\mockingbird\MockingBird-main>set CUDA_VISIBLE_DEVICES=0(2)设置合适的训练批次大小
不同型号计算机的GPU内存配置有所不同,我的GPU内存只有2G,mockingbird默认的批次大小为16,运行一会儿就会因为GPU内存不足而中断,这个问题在github中有解决方案,按照其提示修改hparams.py代码中的批次数量。该文件在conda环境中 MockingBird-main\synthesizer目录下。我在代码头部加了一个常量,再在代码相关部分用此常量替代原用的batch_size。
import ast
import pprint
import json
my_batch_size=4 ##调整后的batch_size
...
### Tacotron Training
### 调整批次大小
tts_schedule = [(2, 1e-3, 10_000, my_batch_size), # Progressive training schedule
(2, 5e-4, 15_000, my_batch_size), # (r, lr, step, batch_size)
(2, 2e-4, 20_000, my_batch_size), # (r, lr, step, batch_size)
(2, 1e-4, 30_000, my_batch_size), #
(2, 5e-5, 40_000, my_batch_size), #
(2, 1e-5, 60_000, my_batch_size), #
(2, 5e-6, 160_000, my_batch_size), # r = reduction factor (# of mel frames
(2, 3e-6, 320_000, my_batch_size), # synthesized for each decoder iteration)
(2, 1e-6, 640_000, my_batch_size)], # lr = learning rate我自己的计算机GPU内存为2G,经尝试9、6、5和4个数值,4是最大保持持续运行的数字。
5、设置好环境变量和批次大小,现在可以用web.py运行一次训练了。
如果正确配置,则使用ctrl+shift+esc调出windows任务管理器,可以在“性能”页面里看到GPU及其内存使用率都将正确显示。注意,任务管理器中的GPU编号和nvidia-smi显示的编号是不一样的。
6、模型训练的命令行方式
进入conda环境的MockingBird-main目录,运行python synthesizer_train.py demoPT G:\mocking\SV2TTS\synthesizer。其中demoPT就是我们自建的模型训练集。
(mockingbird) E:\MiniConda3\envs\mockingbird\MockingBird-main>python synthesizer_train.py demoPT G:\mocking\SV2TTS\synthesizer七、写在最后
我在使用github最新mockingbird包之前,下载使用过gitee.com 的 Dwesome / MockingBird克隆包,出现过两个问题,一是需要visual c++ build tools,我用网上的办法下载visual c++ build tools安装包无果,只能安装visual studio 2015解决。二是在执行demo_toolbox.py过程中,提示"no module named 'tools.alignments' 'tools' is not a package"错误,用vscode跟踪发现importlib.import_module()加载tools模块目录时失败,进入该目录后发现缺少__init__.py文件,于是在其目录中加入一个空的__init__.py文件,问题解决。另外,使用github最新包时,出现h5py版本不正确,导致espnet202209无法使用,pip更新h5py包之后问题解决。
由于在安装过程中一些细节问题我并没有及时记录,所以有些问题在这篇文章里并没有提到。还请其他拎包客给予补足、修正。