ubuntu系统和pytorch环境安装驱动、cuda和cudnn(包括解决安装CUDA时提示/tmp空间不足的方法)
ubuntu给pytorch深度学习环境以及ubuntu系统安装cuda和cudnn
保研已经结束将近2个月了。这几天开始着手毕设的事情,做深度学习行人重识别这一块。由于深感pytorch有超过tensorflow之势,所以我决定和之前一直用的tensoflow框架先暂时告个别,入坑pytorch。于是乎。。。由于重度遗忘的原因,之前怎么配置tensorflow环境忘记了很多,所以配pytorch遇到了很多坑!!!(主要是cuda和cudnn这一块)花了3小时码这篇博文希望帮助大家!
加油打工人
首先我需要提示大家:
如果cuda和cudnn只是为了在创建的pytorch环境里用(一般都是吧),只需要按照我第一部分内容的步骤做,忽略第二部分。也就是说,可以直接在pytorch环境通过install命令安装cuda和cudnn,即:
通过“conda install cudatoolkit”和“conda install cudnn”安装!!!
通过“conda install cudatoolkit”和“conda install cudnn”安装!!!
通过“conda install cudatoolkit”和“conda install cudnn”安装!!!
######################### 第一部分#########################
1、创建一个pyrtorch的新环境
conda create -n 环境名 python=版本号
我的环境名为torch,一直习惯用python3.6,所以我用的是
conda create -n torch python=3.6
2、进入刚刚创建的环境
conda activate torch
3、安装cuda
conda install cudatoolkit=9.0
我一直习惯用9.0版本,自己选择
4、安装cudnn
conda install cudnn
这时候cudnn不再需要版本号了,conda会自动安装和cudatoolkit兼容的对应版本的cudnn。
5、安装pytorch
pytorch和tensorflow、caffee等等都是深度学习框架,但本质上还是库或者包(package)。因此我们需要在环境里安装pytorch.
conda install pytorch
同样的,pytorch也不需要版本号,Anaconda会自动安装适合版本的pytorch
6、检查以上是否安装成功
conda list
这时候就可以看到刚刚我们在环境里安装好的cuda,cudnn,pytorch
没错,如果只是安装这些东西,这个pytorch环境比较重要的cuda、cudnn、pytorch就已经成功了,当然后续还需要自行安装numpy等重要的库。
以上这些不是我写这篇博客的原因,因为以上寥寥几行命令是在我跌跌撞撞两天后悟出的真正需要的命令。而实际上在此之前的这两天一直在忙活着给自己的ubuntu系统装cuda和cudnn,也就是第二部分内容(其实是没啥必要的)!!!!而不是在我真正需要的pytorch环境安装!!!(哭了哭了) 。在给自己ubuntu装cuda和cudnn过程中我发现很多博客都是复制粘贴或者不够准确全面,接下来我将讲述一下如何给自己的ubuntu系统装cuda和cudnn.
#####################第二部分##############################
1、查看gcc版本号是后面安装的基础!
这也是后来我安装版本号version为450的nvidia driver驱动时系统提示的当前gcc版本是5.5.0,而需要7.5.0我才发现的!
gcc -v
我的版本号是5.5.0,于是我才升级到了7.5.0(这和我后面安装的450.80版本的nvidia driver相匹配)
sudo apt-get remove gcc #卸载老版本的gcc
sudo apt-get remove g++ #卸载老版本的gcc++
sudo apt-get update #更新官方源
sudo apt-get install gcc #我执行这个命令后,系统默认安装了gcc7.5.0。如果想安装其他版本的gcc我认为应该也是可以在后面加“==x.x.x”的
sudo apt-get install build-essential #build-essential是一整套工具,gcc++,libc等
gcc -v #再次查看gcc版本,此时已更新成7.5.0
2、安装适合本系统的nvidia Driver
这需要我们到nvidia官网去查找,输入本电脑的信息后,官网会给出适合的Driver
官网网址:nvidia驱动官网


可以看到官网指示适合我的驱动版本为450.80.02,之后点击Download,下载驱动。
当然我看到不少博客说在终端输入 sudo ubuntu-drivers devices 就可以找到系统推荐的驱动版本,然后sudoapt-get install就行。
尝试结果如下
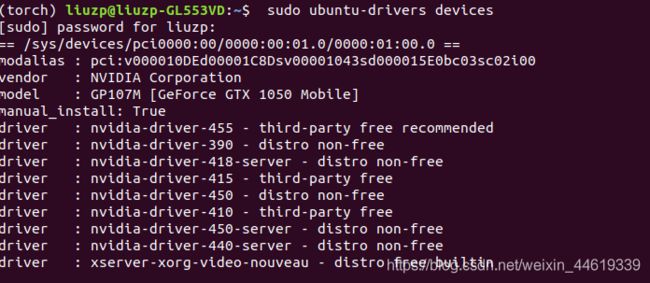
显示的系统推荐的nvidia 版本号(一般是显示450, 390, 455等),但是我apt-get install时还出了点问题,所以为了稳妥些,建议大家直接上官网查找后在官网下载
3、安装nvidia驱动
先卸载本机旧版本的驱动`
sudo apt-get remove --purge nvidia*
sudo apt autoremove
禁用nouveau驱动:
lsmod | grep nouveau
若无任何输出,则说明禁用成功。
进入到下载好的.run文件夹下给驱动run文件赋予执行权限:
cd /home/liuzp/Downloads #这是我.run文件存放的文件夹
sudo chmod a+x NVIDIA-Linux-x86_64-450.80.02.run
接下来开始执行.run文件安装nvidia驱动,要感谢这位博主(感谢这篇博客!)特别强调的循环登陆问题。
sudo ./NVIDIA-Linux-x86_64-450.80.02.run -no-x-check -no-nouveau-check -no-opengl-files
#只有禁用opengl这样安装才不会出现循环登陆的问题
-no-x-check:安装驱动时关闭X服务
-no-nouveau-check:安装驱动时禁用nouveau
-no-opengl-files:只安装驱动文件,不安装OpenGL文件
安装过程中会有几个选项让我们选择,我只记得大概描述
1、 Nvidia's 32-bit compatibility libraries? 选择 No 。
2、 Would you like to run the nvidia-xconfigutility to automatically update your x configuration so that the NVIDIA x driver will be used when you restart x? Any pre-existing x confile will be backed up. 选择 Yes
等等问题
其实我前后安装了3次驱动,每次蹦出的问题不大一样。最后一次甚至没弹出选择题就安装成功了,因机器和运气而异吧。
我的系统安装成功是这样的

之后在终端输入
nvidia-smi
弹出这样的截图才是说明nvidia驱动安装好了

4、安装cuda(重点)
上一步驱动已经安装好了,接下来安装cudatoolkit时同样需要我们注意,驱动和我们将要下载的cuda版本是否匹配问题。
4.1 如果你的系统之前已经安装过cuda(比如我要之前安装过CUDA10.0),请先彻底删除之前的CUDA再执行4.2步骤:
cd /usr/local/cuda/bin
sudo ./uninstall_cuda_x.x.pl #我的文件是uninstall_cuda_10.0.pl
之后再检查/usr/local/下是否还有cuda10.0文件夹,如果有,删除
cd /usr/local
sudo rm -r cuda-10.0 #删除cuda10.0文件夹
这样应该就彻底清除了旧版本的cuda.删除完后再按下面的步骤找新的需要的cuda.
4.2 如果系统之前没有安装过cuda,直接上官网查找和nvidia驱动匹配的cuda
官网链接

由于我的nvidia版本是450.80.02,因此适合我的应该是CUDA 11.0.3 Update 1,也就是11.0.3版本的cuda.
接下来在官网下载,地址是网址

输入自己的ubuntu系统信息,我的是ubuntu18.04, 一定要选择runfile文件。选择后官网下面会给出下载命令
 所以在终端输入
所以在终端输入
wget https://developer.download.nvidia.com/compute/cuda/11.1.1/local_installers/cuda_11.1.1_450.80.02_linux.run
sudo sh cuda_11.1.1_450.80.02_linux.run
注意第二句:sudo sh cuda_11.1.1_450.80.02_linux.run !!
我执行这一句的时候,系统提示了**/tmp空间不足问题**,然后cuda就中断安装了,吓得我想重新划分磁盘空间大小,但是duck不必,因为并不是真的出现/tmp大小不够。如果你也碰到这种情况,请这样做:
首先在/home目录下新建一个tmp文件夹
sudo mkdir /home/tmp
之后再输入
sudo sh cuda_11.1.1_450.80.02_linux.run --tmpdir=/home/tmp
然后等待几十秒后,就进入安装cuda过程,会出现一些选项让你选择。
有几个选项一定要注意:
Do you want to install the OpenGl Libraries? 选择no
Do you want to run nvidia-xconfig? 选择no
其余的都选择yes
这是我在安装cuda 10.0过程中出现的选择问题以及最后成功的截图

如果最后出现了类似以下的信息(如上图末尾显示),说明cuda安装成功了
Driver: installed
Toolkit: installed in /usr/local/cuda-11.0
Samples: installed in /home/liuzp
最后要记得修改环境变量,添加cuda的路径。
sudo gedit ~/.bashrc
.bashrc就是系统环境变量,在.bashrc文本最末尾添加以下三行。
大家只需要把后面的版本号改成自己的,然后复制这三行到自己的.bashrc环境变量就行
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-11.0/lib64
export PATH=$PATH:/usr/local/cuda-11.0/bin
export CUDA_HOME=$CUDA_HOME:/usr/local/cuda-11.0
添加完后,记得点击保存save。
之后使环境变量生效
source ~/.bashrc #使环境变量生效,如果没有执行这一句再次打开环境变量.bashrc时刚刚添加的三行会消失,相当于作废
最后检查cudatoolkit是否安装成功
nvcc -V
如果出现下面这样的结果,能显示cuda信息,说明安装好了

在我安装过程中,我也看到不少博客提出更稳妥的检查是否安装成功方法,即尝试编译cuda提供的samples,亲测有效。我建议大家也试试
其中samples是安装cuda时自动下载下来的,一般存在/home/xxx下,sample里面包含好几个sample.我的如下显示NVIDIA_CUDA-11.0_Samples

cd /home/xxx/NVIDIA_CUDA-11.0_Samples #xxx是你自己的用户名,我的是liuzp.
make #系统就会进入到编译过程,整个过程大概需要30分钟以内。如果出现错误的话,会立即停止
如果执行完最后显示Finished building CUDA samples,就表示你可以完全放心安装cuda是没出错的!
当然如果你没足够耐心,可以只编译其中一个sample而不编译所有的samples
cd /usr/local/cuda-11.0/samples/1_Utilities/deviceQuery
sudo make
./deviceQuery
这是我的执行过程

如果执行完最后显示“Result=PASS”,说明你的cuda安装通过了检测,安装成功
5、安装cudnn(重点)
这个过程坑不多。进入官网,找到和cuda匹配的cudnn。进入官网

前面讲到,我的是cuda 11.0.3,因此先找到cudnn for CUDA11.0,可以看到有好几个适合CUDA11.0的,我认为是都可以的(建议都下载到本地后逐个尝试,哪个cudnn可以用哪个)。选择点击其中一个,进入后如下图

选择下载第一个,cuDNN Library!我下载的是cudnn-11.0-linux-x64-v8.0.4.30。
下载到本地后,解压后文件里面有cuda文件夹,cd到cuda文件夹后执行
sudo cp cuda/include/cudnn.h /usr/local/cuda/include/
sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64/
sudo chmod a+r /usr/local/cuda/include/cudnn.h
sudo chmod a+r /usr/local/cuda/lib64/libcudnn*
cudNN就安装好了。
Summary总结:从大三开始配环境,到这两天重新配一遍,真的应验了一句话:科研就是不断试错的过程。一个很现实的细节问题,就是总是要留意各个依赖包版本匹配的问题。希望博客能帮助到大家(真的呕心沥血整理的亲身体验的安装记录,两天腰酸背痛。。)
平哥我亲测有效,绝不无脑搬运。
参考(感谢大哥良心博客)
[1]: https://blog.csdn.net/wm9028/article/details/110268030
[2]: https://blog.csdn.net/qq_34138003/article/details/109390134