【配准图像】
MU-Net: A MULTISCALE UNSUPERVISED NETWORK FOR REMOTE SENSING IMAGE REGISTRATION
(MU-Net:一种多尺度无监督遥感图像配准网络)
多传感器或多模态图像对的配准是许多遥感应用的基础性任务。为了实现高精度、低成本的遥感图像配准,提出了一种多尺度无监督网络(MU-Net)。MU-Net无需昂贵的地面实况标签,直接学习从图像对到其变换参数的端到端映射。MU-Net通过在多个尺度上叠加多个深度神经网络模型,实现了由scoarse-to-fine的配准流水线,避免了反向传播算法陷入局部极值,抵抗了图像的严重失真。此外,基于结构相似性设计了一种新的损失函数范式,使得MU-Net能够适用于各种类型的多模态图像。
介绍
遥感图像配准(Remote sensing image registration (RSIR))的目的是通过对应性检测获取图像间的几何变换参数(transformation parameters (TPs) )。RSIR是一项前期工作,它直接影响后续工作的性能,如图像融合、变化检测和变形监测等。从传统技术到深度学习(DL)技术,遥感界已经开发出许多令人鼓舞的图像配准方法。
传统的方法一般可以分为两类:基于特征的方法和基于区域的方法(Ma等人,2021年)。基于特征的方法从两幅图像中提取显著的和可重复的特征,并建立它们的对应关系。尺度不变特征变换(SIFT)是其中的代表,在SIFT的基础上提出了很多算法,如加速鲁棒特征(SURF)、定向FAST和旋转BRIEF(ORB)等。这些类SIFT方法适用于从单模态图像中提取可重复特征,但对于具有辐射变化的多模态图像(如光学-SAR图像对)则很脆弱。为了提高对辐射测量差异的鲁棒性,提出了一些局部特征描述符,例如辐射变化不敏感特征变换(RIFT)。总的来说,基于特征的方法的主要挑战是提取高度可重复的和不同的特征并正确地匹配它们。
基于区域的方法通常采用模板方案并通过评估图像的相似性来检测对应性。一些广泛使用的相似性度量是差平方和(SSD)、归一化互相关(NCC)和互信息(MI)。上述度量的性能很容易受到辐射度变化的影响。基于区域的方法的最新研究是将结构特征集成到相似性度量中以应对辐射度变化。虽然基于结构特征的区域配准方法能够有效地处理辐射变化,但在配准之前需要消除图像间明显的几何畸变。这需要手动选择控制点或需要具有地理参考信息的图像,使得基于区域的方法受到限制。总的来说,基于区域的方法的主要局限性在于它们不能有效地处理具有大几何失真的图像。
这两类传统方法分别存在上述缺点。此外,它们通常包括集成通过手工而不是自动学习提取的特征或局部描述符的匹配过程。由于在特征提取、描述和匹配过程中没有信息反馈,这些方法缺乏深层语义信息。当图像源改变时,这些手工制作的特征通常需要重新设计以保持匹配性能。因此,传统的方法往往难以处理几何失真和多模态图像之间的辐射差异。
近年来,越来越多的研究聚焦于数字图书馆。DL方法在一定程度上可以解决传统方法的缺点。一般来说,DL方法可以分为两类:集成学习方法和端到端学习方法。
集成学习方法通常集成深度神经网络(DNN)转化为传统的方法,并从自动学习的特征映射中提取特征描述符。传统的关键点检测、特征描述、模板滑动等操作都是在自学习的特征图上进行,而不是在原始图像或手工艺品特征图上进行。一些研究将SIFT描述符与DNN相结合,或将多方向梯度特征放入DNN。然而,这些集成学习方法无法匹配几何失真较大的图像,并且仍然需要针对不同的数据设计特定的DNN。与传统方法相比,计算复杂度增加了许多倍,但配准效果并没有明显改善。
端到端学习方法旨在直接预测TP。根据优化器是否需要地面实况TP,端到端学习方法可以被分为有监督的端到端学习方法(此后称为有监督的方法)和无监督的端到端学习方法(此后称为无监督的方法),其共同架构分别如图1(a)和(b)所示。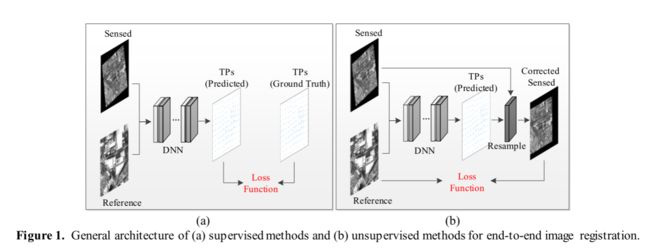
如图1(a)所示,监督方法在训练过程中最大限度地减少了预测TP和地面真实TP之间的差异。相关研究包括深度图像单应性估计网络(DHN)、多尺度深度图像单应性估计网络(MHN)和深卢卡斯-卡纳德特征图(DLKFM)。然而,监督方法的网络需要通过大量具有地面真实TP的图像来训练。一个很大的挑战是,真正的标签是昂贵的,很难在RSIR获得。这种局限性使得监督方法难以在实践中得到广泛应用。
无监督方法在训练过程中优化图像之间的相似性,并且不需要地面真实TP,如图1(b)所示。近年来,无监督配准方法在医学图像配准中得到了广泛的应用,它解决了在没有真实可信点的情况下,网络训练效率不高的问题。相关的杰作包括VoxelMorph,以及深度学习图像配准框架(DLIR)。然而,由于以下原因,直接将相关方法应用于RSIR可能并不合适。首先,现有方法不能有效处理噪声和非线性辐射差异,这使得这些方法容易受到多模态RSIR的影响。其次,这些方法在图像配准之前需要对图像进行粗配准,而在RSIR中,消除几何失真是目标而不是预处理步骤。当图像具有显著的几何和辐射差异时,这些方法通常遭受较大的配准误差。
一般来说,在没有地面真值TP的情况下,目前还缺乏能够有效同时处理图像间大的几何畸变和辐射差异的方法,而我们的工作填补了这一空白。我们提出了一种多尺度无监督网络(MU-Net),它是一种从输入图像对到其TP的端到端映射方案。我们堆叠了几个DNN模型,用于从coarse-to-fine的配准管道,每个DNN模型代表在单个尺度上执行的工作流。在每个尺度上,通过优化图像之间的相似性来训练相应的DNN,从而避免了对地面真实TP的需要。首先,每个DNN模型被单独地和连续地训练以初始化网络权值。其次,将所有DNN模型级联堆叠形成联合配准流水线,并对联合配准流水线的参数进行联合训练,输出最终的TP。此外,该方法基于图像的结构特征而非图像的灰度特征来评价图像对的相似性,适用于多模态RSIR。
贡献
1)我们提出一个配准网络与无监督学习,这是一个端到端的图像的映射方案对转换参数。
2)该算法将多个DNN模型在多个尺度上叠加,形成由粗到精的配准流水线,避免了陷入局部极值,并能抵抗大范围的图像失真。
3)设计了一种新的基于结构相似度的损失函数模型,使得配准网络适用于各种类型的多模态图像。
方法
在这一部分中,详细阐述了所提出的用于RSIR的MU-Net,该MU-Net将图像通过多个尺度上的多个设计的DNN结构来回归TP,然后校正传感图像以与参考图像对齐。由于通过评估两幅图像的结构特征描述符的相似性来直接优化TP,因此MU-Net是完全无监督的。在本文中,我们选择仿射TP作为预测映射的形式,并且MU-Net可以集成其他形式。详情如下所示。
Problem Formulation
假设有一对图像f & m要对准。一个是具有每个像素的正确地理坐标的参考图像f,另一个是具有几何失真的感测图像m。 为了校正m,目标是找到一组TPsμ。在传统的图像配准中,通过最大化某个相似性度量Sim来直接优化μ:
在无监督配准方法中,μ通过设计的DNN F回归:
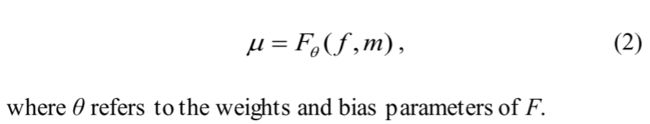
因此,μ是间接优化的,因为它是通过最大化Sim直接优化的θ:

在MU-Net中,F被定义为一个由coarse-to-fine的堆叠式配准流水线,在训练过程中优化其权值和偏差参数θ。
Multiscale Workflow
MU-Net执行从coarse-to-fine的多尺度策略。具体来说,将三个DNN模型级联叠加,将不同下采样率的图像输入MU-Net,如图2所示。

首先,尺度为1的DNN模型执行输入图像f和m之间的初始和全局对准。具体地,f & m通过1/4的比例因子下采样,然后输入到第一DNN模型以评估初始TP μ1。随后,将μ1应用于空间Transformer网络(Spatial Transformer Network (STN)),并校正原始感测图像m以产生第一校正感测图像Tμ1(m)。
其次,尺度为2的DNN模型在f和Tμ1(m)之间执行残差对齐。具体而言,f & Tμ1(m)通过1/2的比例因子进行下采样,然后输入到第二个DNN模型以评估残差TP Δμ1,将其积分到μ1以产生第二个TP μ2。并且μ2被施加到STN,并且校正原始感测图像m以产生第二校正感测图像Tμ2(m)。
第三,尺度为3的DNN模型还在f和Tμ2(m)之间进行了更详细的比对。具体而言,将f和Tμ2(m)直接输入第三个DNN模型,以评估残余TP Δμ2,将其积分到μ2,以产生最终TP μ3。将μ3应用于STN并校正原始感测图像m以产生最终校正感测图像Tμ3(m),从而实现图像配准。
DNN Architecture on Each Scale
在本节中,我们将介绍每种规模的DNN架构。为了提取深层语义信息并找到端到端TP映射,我们利用通道注意机制和深度残差网络,以形成DNN架构。前者能自适应地调整各通道的权值。后者保证了深层语义信息不会随着网络的深化而减少。
我们将深度残差(Deep Residual (DR))ConvBlock定义为添加残差网络的普通卷积块,而(Squeeze Excitation and Deep Residual)SE-DR ConvBlock是集成了信道注意机制的DR ConvBlock。图3描述了第三个尺度上的DNN架构。输入图像对应该具有相同的大小,如果不具有相同的大小,则通常采用补零或裁剪。两幅图像在通道方向上连接,然后分别通过一系列7×7和一系列5×5的ConvBlock。这两条路径通过上采样和跨步连接连接在一起,然后是几个3×3 ConvBlock。在前向传播过程中,图像尺寸减小,通道加深,有利于提取深层语义信息。在经过最后一个ConvBlock后,深层语义信息通过两个完全连接层直接映射到TP。
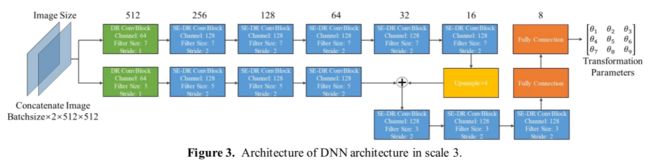
第一和第二尺度上的DNN架构类似于第三尺度上的DNN架构。不同之处在于,输入图像经过了下采样,因此图像的初始尺寸变为128×128像素或256×256像素,而不是512×512像素。因此,我们为每个路由减少了两个SE-DR ConvBlock,同时将通道的最大数量保持在32,这形成了第一尺度上的DNN架构。类似地,我们减少了每个路由的SE-DR ConvBlock,并将通道的最大数量维持在64,这形成了第二尺度上的DNN架构。
Unsupervised Training
在MU-Net中,三个DNN模型以级联方式堆叠,形成从粗到精的配准流水线。因此,训练过程包括初始化和联合训练两部分。
在第一阶段,为了初始化网络权重,每个DNN模型被单独地和连续地训练,以基于图像结构相似性最小化相应的损失:Losssim(f,m,μ1),Losssim(f,m,μ2)和Losssim(f,m,μ3)。第一模型被训练用于粗略对准。在第一模型的权重固定的情况下,连续训练第二模型以微调比对。最后,训练第三模型e以进一步校正对准,同时冻结第一和第二模型的权重。
在第二阶段,所有堆叠DNN模型的权重被解冻以可更新。并且MU-Net中的每个DNN模型被联合训练以在多个尺度上协作地最小化总损失,其被定义为:
支持参考图像与经TP及其空间变换校正的感测图像达到最佳相似度。类似地,支持感测图像以实现与通过逆空间变换包裹的参考图像的最佳相似性。为了提高TPs μ的可靠性,我们对坐标映射Tμ的矩阵求逆: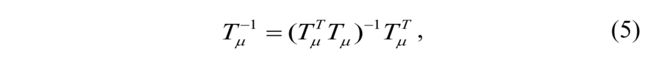
其中 T μ − 1 Tμ^ {-1} Tμ−1表示坐标映射的逆矩阵。因此,相似性损失函数定义为:
对于多模态的RSIR,如光学SAR图像,由于辐射差异,其像素强度不能直接用于相似性评价。考虑到多模态图像之间保留了结构特征,我们使用结构描述子代替强度来计算相似性度量值。对于收敛损失函数,我们主要采用了一种快速和鲁棒的结构描述符,称为定向梯度的信道特征(CFOG)。如图6所示,CFOG首先提取多方向梯度,然后构建方向直方图。基于方向直方图,卷积运算由三维类高斯核执行,该核收集相邻像素的方向梯度。因此,生成了3-D结构特征图。
我们在结构特征图A和B上对Sim(A,B)采用相似性度量NCC。NCC通过搜索最大值的位置来确定两个结构特征图之间的对应关系,其可以计算为: