Pytorch 天池_工业蒸汽量预测
Pytorch 天池_工业蒸汽量预测
- 1. 赛题介绍
- 2. 数据说明
- 3. 实验步骤
-
- 3.1 数据清洗
- 3.2 数据归一化
- 3.3 数据划分
- 3.4 建立模型
- 3.5 训练参数
- 3.6 运行代码
- 3.7 实验结果
1. 赛题介绍
火力发电的基本原理是:燃料在燃烧时加热水生成蒸汽,蒸汽压力推动汽轮机旋转,然后汽轮机带动发电机旋转,产生电能。在这一系列的能量转化中,影响发电效率的核心是锅炉的燃烧效率,即燃料燃烧加热水产生高温高压蒸汽。锅炉的燃烧效率的影响因素很多,包括锅炉的可调参数,如燃烧给量,一二次风,引风,返料风,给水水量;以及锅炉的工况,比如锅炉床温、床压,炉膛温度、压力,过热器的温度等。
赛题链接:https://tianchi.aliyun.com/competition/entrance/231693/introduction
2. 数据说明
数据分成训练数据(zhengqi_train.txt)和测试数据(zhengqi_test.txt),其中字段V0-V37,这38个字段是作为特征变量,“target”作为目标变量。
训练集:
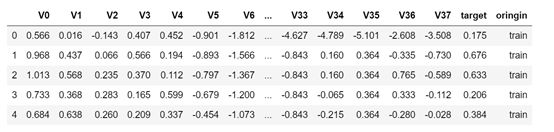
测试集:

因此我们可以创建一个简单的深度学习模型Y=f(x),使用V0-V37作为训练集(train set)的输入x,target作为模型的输出(即预测结果),对预测结果的评估可以使用均方误差MSE(mean square error)。最后将测试集的数据输入到训练好的模型中,得到测试集的预测结果。
3. 实验步骤
3.1 数据清洗
需要先了解数据的特征及其分布,才能对数据进行清洗,有必要的话还可以提高特定数据的权重,来增强模型对数据的拟合程度。
将训练集和测试集的V0-V37合并,查看特征分布。
SelectKBest特征选择:
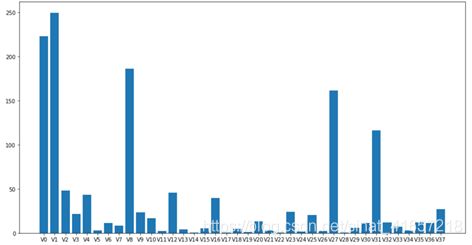
数据质量分布图:
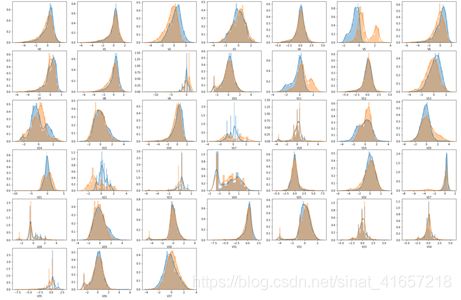
使用目测法可以发现,特征中{V5,V9,V11,V17,V19,V20,V21,V22,V24,V28}的数据在训练集和测试集中分布不均匀,那么可以近似的理解为这些特征对模型的影响比较小,也就是模型对这些数据的学习可能对预测没有帮助,因此我们可以将这几个特征从数据集中移除,让模型只学习其他的特征。
(数据清洗部分我只考虑到了特征集合与模型学习的关系,应该再对横向的数据进行清洗,假设存在某行数据存在较大的误差,那么可能这个数据会对模型的学习产生负面影响)
3.2 数据归一化
为了能够更好的训练,最好将输入数据进行归一化(归一化可以将数据约束在一个区间),这里我们可以使用数据标准化(StandardScaler)或数据归一化(MinMaxScaler)处理数据。
考虑到后面深度学习网络使用的激活函数为ReLU,ReLU的计算结果是非负数,因此我使用的是数据归一化,将数据约束在0-1。
归一化结果:

3.3 数据划分
用于训练的数据,按照训练集和测试集按照8:2进行划分,然后导入模型训练并调参。如果最后训练效果良好,可以把训练集和测试集的比例再调高,有助于模型的学习,以及得出测试数据的最优结果。
3.4 建立模型
由于训练使用的特征为28个,数量少于32个,并且训练样本不超过3000,根据经验得出,深度学习网络的隐藏层设置在3到5层较为合适。
因此可以构建类似下列模型:

废话:模型一共5个隐藏层,各层神经元个数为{28,32,64,32,16,1},并使用ReLU作为隐藏层的激活函数。这里的各层神经元使用的是2的倍数,有一种说法是数据在GPU和CPU中是使用二进制存储的,使用2的倍数可以提高数据的计算速度,其实不使用2的倍数也可以,使用2的倍数只是起到一个方便修改参数的作用,同时神经网络具有优秀的泛化性,前后两层神经元个数差距不大也能得到良好的学习。所以各层神经元你想设为{28,48,64,32,16,1}也没有问题,别问问就玄学。
3.5 训练参数
| Name | value | Description |
|---|---|---|
| batch_size | 32 | 训练批次 |
| epoch | 500 | 训练轮数 |
| learning_rate | 0.001 | 学习率 |
| weight_decay | 0.01 | 权重衰减 |
| optimizer | Adam | 模型训练优化器 |
运行环境:
CUDA10.0、Python3.6.9、Pytorch1.2.0
3.6 运行代码
import numpy as np
import torch
import torch.nn as nn
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn import preprocessing
import torch.utils.data as Data
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = ['sans-serif'] # 中文乱码
plt.rcParams['font.sans-serif'] = ['SimHei'] # 中文乱码
plt.rcParams['axes.unicode_minus'] = False # 正常显示符号
class Model():
def __init__(self, sizes):
self.MSE = nn.MSELoss()
self.layers = nn.ModuleList()
self.train_loss_set = []
self.test_loss_set = []
for neuron, next_neuron in zip(sizes[:-1], sizes[1:]):
self.layers.append(nn.Linear(neuron, next_neuron))
def forward(self, x):
for layer in self.layers[:-1]:
x = torch.relu(layer(x))
x = self.layers[-1](x)
return x
def train(self, x_train, y_train, epochs, batch_size=1, lr=0.001, weight_decay=0.01):
self.train_loss_set = []
self.test_loss_set = []
optimizer = torch.optim.Adam(self.layers.parameters(), lr=lr, weight_decay=weight_decay)
# 数据集划分批次
torch_data_set = Data.TensorDataset(x_train, y_train)
loader = Data.DataLoader(dataset=torch_data_set, batch_size=batch_size, shuffle=True)
for e in range(epochs):
if e == 300 or e == 450:
lr /= 2
for (batch_x, batch_y) in loader:
y_hat = self.forward(batch_x)
loss = self.MSE(y_hat, batch_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
y_train_predict = self.forward(x_train)
train_loss = self.MSE(y_train_predict, y_train)
self.train_loss_set.append(train_loss.item())
print("Epoch:{} train loss:{}".format(e + 1, train_loss.item()))
if __name__ == '__main__':
# 训练数据路径
train_path = 'zhengqi_train.txt'
# 测试数据路径
test_path = 'zhengqi_test.txt'
# 保存结果路径
save_path = 'result.txt'
train_data = pd.read_table(train_path) # 读取训练数据
delete = [5, 9, 11, 17, 19, 20, 21, 22, 24, 28] # 不重要特征 V5 V9 V11 V17 V19 V20 V21 V22 V24 V28
data_range = [i for i in range(38) if i+1 not in delete] # 可以作为训练的列
# 训练批次
batch_size = 32
# 训练轮数
epochs = 500
# 学习率
learning_rate = 1e-3
# 权重衰减
weight_decay = 0.01
# 获得训练集
x_train, y_train = train_data.iloc[:, data_range].values, train_data.iloc[:, -1].values
test_data = pd.read_table(test_path) # 读取测试数据
x_result = test_data.iloc[:, data_range].values # 提取值
# 数据归一化
scaler = preprocessing.MinMaxScaler(feature_range=(0,1))
len_x_train = len(x_train)
len_x_result = len(x_result)
data = np.vstack((x_train, x_result))
data = scaler.fit_transform(data)
# 切割数据
x_train = data[:len(x_train)]
x_result = data[len(x_train):]
# numpy转tensor, view(n行,m列)
x_train = torch.from_numpy(x_train).float()
y_train = torch.from_numpy(y_train).float().view(-1, 1)
# 模型初始化
sizes = [len(data_range), 48, 64, 32, 16, 1] # 模型尺寸
model = Model(sizes) # 创建模型
model.train(x_train, y_train, epochs=epochs,batch_size=batch_size, lr=learning_rate, weight_decay=weight_decay) # 训练
# 预测测试数据
x_result = torch.from_numpy(x_result).float() # 标准化转float
y = model.forward(x_result) # 前向传播
print(y.shape) # 显示数据尺寸
np.savetxt(save_path, y.detach().numpy()) # 保存文本
# 绘制结果
plt.figure(figsize=(8, 6)) # 设置画布大小
plt.plot(model.train_loss_set, 'r-', linewidth=1, label='train mse') # 训练集损失
plt.legend()
plt.grid(True) # 显示网格
plt.show() # 显示图片
3.7 实验结果
训练过程:
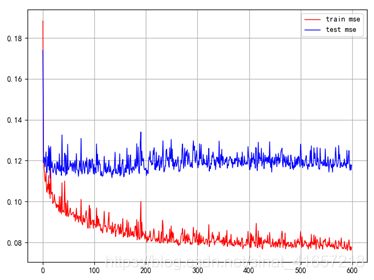
蓝色代表测试集误差,红色代表训练集误差,可以看出模型已经达到一个收敛状态,由于最后需要的是测试数据的预测结果,我将测试数据进行预测提交,得到的MSE为0.2759。
预测的误差挺大的,那么就需要进一步优化了,我把神经元个数调整成{28,48,64,32,16,1},由于测试集是不参与训练的,于是我把原先的所有训练集和测试集合并进行训练,得到下面的训练误差结果:

接着使用训练完的模型,对zhengqi_test.txt的数据进行预测,提交后得到的MSE值为0.1232