朴素贝叶斯算法——垃圾邮件分类
目录
系列文章目录
文章目录
前言
二、数据预处理
1.引入的库
2.去掉非中文字符及切片分词
3.进行标注
标注的实现代码:
4.创建词汇表
5.遍历文档中在词汇表中出现的词
6.创建朴素贝叶斯分类器训练函数
7.构建贝叶斯分类器
8.自动化处理垃圾邮件
结果:只截取了一部分
9.最终实现
总结
前言
前面我们已经学习复习了概率论上的一些基础知识,下面我们就需要用这些知识实现用朴素贝叶斯算法对邮件进行分类。
一、收集邮件数据集
垃圾邮件数据集可以通过任何方法进行收集,网上找、自己写等等,我所收集的中文邮件
二、数据预处理
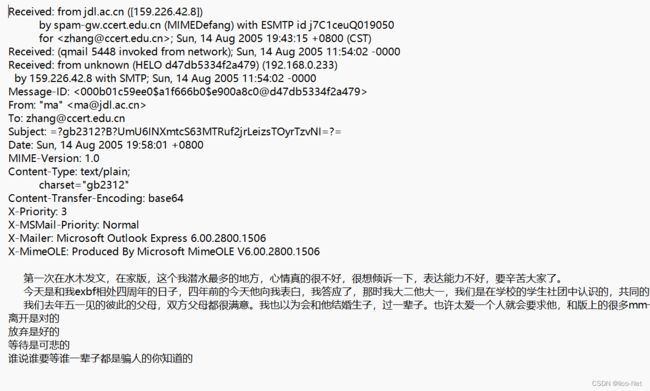
每一篇邮件大致如图所示,除了邮件文本外,还包含其他信息,如发件人邮箱、收件人邮箱等,因为这里是想把垃圾邮件分类简单的作为一个文本分类任务来解决,所以需要去掉除邮件文本外的信息。
1.引入的库
import re #正则表达式库
import jieba #分词库
import codecs
import os
2.去掉非中文字符及切片分词
#对邮件数据集进行预处理
#去掉非中文字符
def CleanStr(string):
string = re.sub(r"[^\u4e00-\u9fff]"," ",string) #将出现的非中文字符用空格替换掉
string = re.sub(r"\s{2,}"," ",string) #s在正则表达式表示任意匹配字符,{2,}表示匹配的字符前面至少出现两次
return string.strip() #用于移除字符串首尾指定的字符(默认为空格或换行符)
#批量读取文件并另保存
def GetDataInFile(original_path,save_path = 'allEmail.txt'): #批量打开文件,并将内容保存在allEmail.txt
files = os.listdir(original_path) #绝对路径
for file in files:
if os.path.isdir(original_path + '/' + file):
GetDataInFile(original_path + '/' + file,save_path = save_path) #绝对路径+相对路径
else:
email = '' #初始化
f = codecs.open(original_path + '/' + file,'r','gbk',errors = 'ignore')
for line in f:
line = CleanStr(line) #将读取到的文件调用正则表达式函数
email += line
f.close()
f = open(save_path,'a',encoding='utf-8') #打开另保存文件
email = [word for word in jieba.cut(email) if word.strip()!=''] #用推导公式将email进行切片
f.write(' '.join(email)+'\n')
print('Storing email in a file...')
GetDataInFile('E:/Learn_data/NaiveBayesData/train/ham',save_path='E:/Learn_data/NaiveBayesData/train/ham/allEmailHam.txt')
GetDataInFile('E:/Learn_data/NaiveBayesData/train/spam',save_path='E:/Learn_data/NaiveBayesData/train/spam/allEmailSpam.txt')
print('Store email finished!')
结果:上述代码会在ham和spam各生成一个allEmail.txt的文本文件,里面包含了所有的ham或spam邮件的中文词汇,这里我只截取了部分
![]()

3.进行标注
单独创建一个文本文件保存标签,对邮件进行标注,将样本标签写入一个单独的文件0表示垃圾邮件,1表示非垃圾邮件;需要注意的是我所打开的文本文件是一个对所有邮件创建索引的文本文件,如图所示:
![]()

标注的实现代码:
#对邮件进行标注,将样本标签写入一个单独的文件0表示垃圾邮件,1表示非垃圾邮件
def GetLabel(original_path,save_path):
label_list = []
f = open(original_path,'r',encoding='utf-8') #这里打开的是邮件的索引文本
#spam
for line in f:
if line[0] == 'S':
label_list.append('0')
#ham
elif line[0] == 'H':
label_list.append('1')
with open(save_path,'w',encoding='utf-8') as f:
f.write('\n'.join(label_list))
f.close()
print('Storing labels in a file ...')
GetLabel('E:/Learn_data/NaiveBayesData/Index.txt',save_path='E:/Learn_data/NaiveBayesData/label.txt')
print('Store labels finished !')
结果:标注的结果只截取了正样本的部分
0001000010100000000000011111111111111111
4.创建词汇表
#创建一个词汇表
def CreateVocabList(docList):
VocabSet = set([]) #创建一个空集
for document in docList:
VocabSet = VocabSet | set(document) #创建两个集合的并集
return list(VocabSet)
5.遍历文档中在词汇表中出现的词
def setOfwords2Vect(vocabList,inputSet): #该函数的输入参数为词汇表及某个文档,输出的是文档向量,向量的每个元素为1或者0,分别表示词汇表中的单词在文档中是否出现
returnVec = [0]*len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] = 1
else:
print("the word:%s is not in my Vocabulary!"%word)
return returnVec
6.创建朴素贝叶斯分类器训练函数
#朴素贝叶斯分类器训练函数
def trainNB0(trainMatrix,trainCategory): #输入参数为文档矩阵trainMatrix和以及由每篇文档类别标签所构成的向量trainCategory
numTrainDocs = len(trainMatrix) #获得训练集的长度
numWords = len(trainMatrix[0]) #
pAbusive = sum(trainCategory)/float(numTrainDocs)
p0Num = np.zeros(numWords)
p1Num = np.zeros(numWords)
p0Denom = 0.0
p1Denom = 0.0
for i in range(numTrainDocs): #循环遍历训练集trainMatrix中的所有文档
if trainCategory[i] == 1:
p1Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i])
else:
p0Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i])
p1Vect = p1Num/p1Denom
p0Vect = p0Num/p0Denom
return p0Vect,p1Vect,pAbusive
7.构建贝叶斯分类器
#创建朴素贝叶斯分类函数
def classify(vec2Classify,p0Vec,p1Vec,pClass1):
p1 = sum(vec2Classify *p1Vec) + log(pClass1)
p0 = sum(vec2Classify * p0Vec) + log(1.0-pClass1)
if p1 > p0:
return 1
else:
return 08.自动化处理垃圾邮件
#创建邮件的测试函数
def SpamTest(): #该函数是对贝叶斯垃圾邮件分类器进行动化处理
docLists = []
classList = []
with open('E:/Learn_data/NaiveBayesData/train/ham/allEmailHam.txt','r',encoding='utf-8') as f:
for word in f:
word = f.readline()
docLists.append(set(word))
classList.append(1)
with open('E:/Learn_data/NaiveBayesData/train/spam/allEmailSpam.txt','r',encoding='utf-8') as f:
for word in f:
word = f.readline()
docLists.append(set(word))
classList.append(0)
VocabList = CreateVocabList(docLists)
trainMat = []
trainClasses = []
for docIndex in range(50):
trainMat.append(setOfwords2Vect(VocabList,docLists))
trainClasses.append(classList[docIndex])
p0V,p1V,pSpam = trainNB0(np.array(trainMat),np.array(trainClasses))
#print(docLists)
#print(classList)
#print(VocabList)
print(p0V)
print(p1V)
print(pSpam)
s=SpamTest()
结果:只截取了一部分
开', '背', '在', '媚', '惜', '影', '次', '候', '必', '么', '易', '而', '夜', '者', '喜', '的', '生', '舒', '或', '感', '晚', '之', '送', '难', '能', '且', '门', '就', '已', '是', '点', '出', '不', '说', '什', '她', '都', '我', '当', '容', '天', '境', '了', '时', '事', '一', '从', '外', '会', '诉', '坐', '让', '得', '未', '可', '今', '面', '找', '猩', '闷', '服', '这', '看', '很', '吹', '欢', '冷', '隆', '觉', '多', '上', '管', '女', '每', '后', '没', '些', '经', '躺', '环', '着', '三', '逸', '还', '刮', '风', '下', '来', '安',

9.最终实现
import re
import jieba
import codecs
import os
import numpy as np
import sklearn.feature_extraction.text
from math import log
#对邮件数据集进行预处理
#去掉非中文字符
def CleanStr(string):
string = re.sub(r"[^\u4e00-\u9fa5]"," ",string) #将出现的非中文字符用空格替换掉
string = re.sub(r"\s{2,}"," ",string) #s在正则表达式表示任意匹配字符,{2,}表示匹配的字符前面至少出现两次
return string.strip() #用于移除字符串首尾指定的字符(默认为空格或换行符)
#批量读取文件并另保存
def GetDataInFile(original_path,save_path = 'allEmail.txt'): #批量打开文件,并将内容保存在allEmail.txt
files = os.listdir(original_path) #绝对路径
for file in files:
if os.path.isdir(original_path + '/' + file):
GetDataInFile(original_path + '/' + file,save_path = save_path) #绝对路径+相对路径
else:
email = '' #初始化
f = codecs.open(original_path + '/' + file,'r',encoding='utf-8',errors = 'ignore')
for line in f:
line = CleanStr(line) #将读取到的文件调用正则表达式函数
email += line
f.close()
f = open(save_path,'a',encoding='utf-8') #打开另保存文件
email = [word for word in jieba.cut(email) if word.strip()!=''] #用推导公式将email进行切词
for emails in email:
if len(emails)>1:
f.write(' '.join(emails))
# print('Storing email in a file...')
# GetDataInFile('E:/Learn_data/NaiveBayesData/train/ham',save_path='E:/Learn_data/NaiveBayesData/train/ham/allEmailHam.txt')
# GetDataInFile('E:/Learn_data/NaiveBayesData/train/spam',save_path='E:/Learn_data/NaiveBayesData/train/spam/allEmailSpam.txt')
# print('Store email finished!')
#对邮件进行标注,将样本标签写入一个单独的文件0表示垃圾邮件,1表示非垃圾邮件
def GetLabel(original_path,save_path):
label_list = []
f = open(original_path,'r',encoding='utf-8') #这里打开的是文件的索引文本
#spam
for line in f:
if line[0] == 'S':
label_list.append('0')
#ham
elif line[0] == 'H':
label_list.append('1')
with open(save_path,'w',encoding='utf-8') as f:
f.write('\n'.join(label_list))
f.close()
# print('Storing labels in a file ...')
# GetLabel('E:/Learn_data/NaiveBayesData/train/Index.txt',save_path='E:/Learn_data/NaiveBayesData/train/label.txt')
# print('Store labels finished !')
#创建一个词汇表
def CreateVocabList(docList):
VocabSet = set([]) #创建一个空集
for document in docList:
VocabSet = VocabSet | set(document) #创建两个集合的并集
return list(VocabSet)
#
def setOfwords2Vect(vocabList,inputSet): #该函数的输入参数为词汇表及某个文档,输出的是文档向量,向量的每个元素为1或者0,分别表示词汇表中的单词在文档中是否出现
returnVec = [0]*len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] = 1
else:
print("the word:%s is not in my Vocabulary!"%word)
return returnVec
#朴素贝叶斯分类器训练函数
def trainNB0(trainMatrix,trainCategory): #输入参数为文档矩阵trainMatrix和以及由每篇文档类别标签所构成的向量trainCategory
numTrainDocs = len(trainMatrix) #获得训练集的长度
numWords = len(trainMatrix[0]) #
pAbusive = sum(trainCategory)/float(numTrainDocs)
p0Num = np.zeros(numWords)
p1Num = np.zeros(numWords)
p0Denom = 0.0
p1Denom = 0.0
for i in range(numTrainDocs): #循环遍历训练集trainMatrix中的所有文档
if trainCategory[i] == 1:
p1Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i])
else:
p0Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i])
p1Vect = log(p1Num/p1Denom)
p0Vect = log(p0Num/p0Denom)
print("概率1",p1Vect)
print("概率0",p0Vect)
print("先验概率",pAbusive)
return p0Vect,p1Vect,pAbusive
with open('E:/Learn_data/NaiveBayesData/train/spam/allEmailSpam.txt',encoding='utf-8') as f1:
f3 = f1.read()
with open('E:/Learn_data/NaiveBayesData/train/label.txt',encoding='utf-8') as f2:
f4 = f2.read()
print(trainNB0(f3,f4))
#创建朴素贝叶斯分类函数
# def classify(vec2Classify,p0Vec,p1Vec,pClass1):
# p1 = sum(vec2Classify *p1Vec) + log(pClass1)
# p0 = sum(vec2Classify * p0Vec) + log(1.0-pClass1)
# if p1 > p0:
# return 1
# else:
# return 0
#创建邮件的测试函数
def SpamTest(): #该函数是对贝叶斯垃圾邮件分类器进行动化处理
docLists = []
classList = []
with open('E:/Learn_data/NaiveBayesData/train/ham/allEmailHam.txt',encoding='utf-8') as f:
for word in f:
word = f.readline()
docLists.append(set(word))
classList.append(1)
with open('E:/Learn_data/NaiveBayesData/train/spam/allEmailSpam.txt',encoding='utf-8') as f:
for word in f:
word = f.readline()
docLists.append(set(word))
classList.append(0)
VocabList = CreateVocabList(docLists)
trainMat = []
trainClasses = []
for docIndex in range(50):
trainMat.append(setOfwords2Vect(VocabList,docLists))
trainClasses.append(classList[docIndex])
p0V,p1V,pSpam = trainNB0(np.array(trainMat),np.array(trainClasses))
# print(docLists)
# print(classList)
# print(VocabList)
# print(p0V)
# print(p1V)
# print(pSpam)
s=SpamTest()
输入样本为:131.txt
结果为:正常邮件
输入样本为:023.txt
结果为:垃圾邮件
朴素贝叶斯分类的优缺点:
优点:在数据较少的情况仍然有效,可以处理多类问题
缺点:对于输入数据的准备方式比较敏感
总结
本篇文章内容到处结束,希望码友们继续再接再厉