Pytorch入门系列8----模型搭建
系列文章目录
文章目录
- 系列文章目录
- 前言
- 模型自定义
-
- 1、嵌套型模型
-
- 1.1声明一个具有Conv,BN、ReLU的复合模型
- 1.2.嵌套网络
- 2、堆叠排列型模型
-
- 注意:网络必须是module或用nn.ModuleList封装类型
- 总结
前言
今天我们来搭建一个简单的神经网络,看看各层是如何排布的。这有利于我们去理解将一个网络如何落实到Pytorch中。
模型自定义
1、嵌套型模型
1.1声明一个具有Conv,BN、ReLU的复合模型
为什么声明它?因为我想声明,记住是先有的想法,才去实现模型。我就想组合这三者,所以用如下代码去实现。
注意:你想组合10个Conv,50个BN,78个R就尽情的用代码去组合去实现,我们本节目的就是学会用Pytorch组我们的想法!!!
代码如下(示例):
class C8L(nn.Module): #继承module类
def __init__(self,in_dim, out_dim, kernel): #重载init方法
super(CBL, self).__init__() #调用父类init初始化
self.conv = nn.Sequential( # 卷积基本单元
nn.Conv2d(in_dim, out_dim,kernel,bias=False),# 卷积
nn.BatchNorm2d(out_dim), # BN
nn.ReLU(inplace=True), # relu
)
def forward(self, x):
x = self.conv1(x)
output = self.out(x)
return output
1.2.嵌套网络
在上面网络基础上再套一层壳子
代码如下(示例):
import torch.nn as nn
class ResUnit(nn.Module):
def __init__(self, in_dim, out_dim):
super(ResUnit, self).__init__()
#嵌套CBL声明1×1、3×3这2个卷积层
self.layer1_1 = CBL(in_dim, out_dim,1)
self.add_module("layer3_3", CBL(in_dim, out_dim, 3))
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
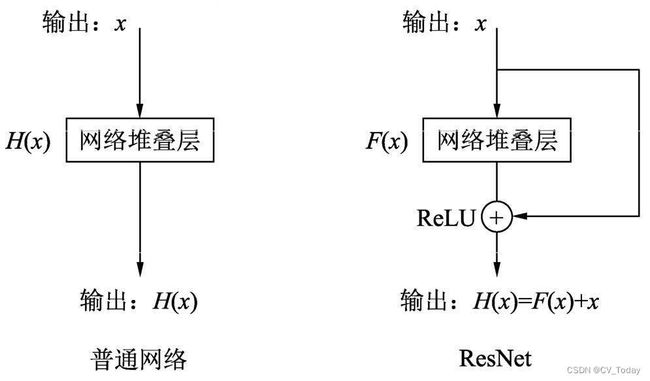
identity = x #映射保存一份原始数据
# 网路堆叠层是由1×1、3×3这2个卷积组成的,中间包含BN层
x = self.layer1_1(x)
out = self.layer3_3(x)
# 将identity(恒等映射)与网络堆叠层输出进行相加,并经过ReLU后输出
out += identity
out = self.relu(out)
return out
2、堆叠排列型模型
代码如下(示例):
import torch
from torch import nn
modules = nn.Sequential() #模型顺序库
models.add_module("conv1", nn.Conv2d(indim, outdim, kernel))
models.add_module('relu1', nn.ReLU())
models.add_module('conv2', nn.Conv2d(indim, outdim, kernel))
models.add_module('relu2', nn.ReLU())
注意:网络必须是module或用nn.ModuleList封装类型
注意:成员变量类型是Module的子类,pytorch才会注册这个模块,模型中才能被加入,否则就不会。
self.add_module(‘layer_{}’.format(i),layer)将nn.Linear声明为 module,Linear模块才被识别
class NeuralNetwork(nn.Module):
def __init__(self, layer_num):
super(NeuralNetwork, self).__init__()
# self.layers = nn.ModuleList([nn.Linear(608,608) for _ in range(layer_num)])封装为module或者for迭代为module
self.layers = [nn.Linear(608,608) for _ in range(layer_num)]
for i,layer in enumerate(self.layers):
self.add_module('layer_{}'.format(i),layer)
self.linear_relu_stack = nn.Sequential(
nn.Linear(608, 40),
nn.ReLU()
)
def forward(self, x):
for layer in layers:
x = layer(x)
logits = self.linear_relu_stack(x)
return logits
总结
以上就是今天要讲的内容,本文简单介绍了模型搭建的基本操作,多种方式都可实现网络的添加与构建。最重要的一点是,一定要清楚的指导自己想搭建的网络架构是什么样的,再用Pytorch来实现。