Redis总结一(基础命令)
Redis
Redis介绍前言
单机Mysql缺点:
- 数据量太大,一个机器太难承担
- 数据量的索引太大,一个机器的内存放不下
- 访问量(读写)太大,一个服务器承受不住
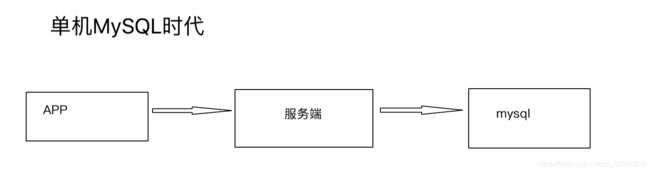
解决办法: - 缓存+读写分离
网站上的访问80%以上都是在读、每次都去查询数据库,效率很低,引入缓存机制,第一次去MySQL中读取数据,将数据返回给用户的同时,将数据在缓存中存储下来,第二次访问,就可以直接在缓存中读取 - 分库分表+集群
分库分表+水平拆分
NOSQL
NOSQL(NOT Only SQL) 泛指非关系型数据库
一,NoSQL特点
- 方便扩展(数据之间没有关系)
- 大数据量高性能(redis 写8w/s,读 11W/s)
- 数据类型是多样性的,不需要事先设计数据库,随取随用
- 存储方式多样,键值对、列存储、文档存储、图形数据库
- 没有固定的查询语句
二,NoSQL四大分类

Redis 入门
Redis基本概念
Redis是一个开源的(BSD协议),内存中的数据结构存储系统,可以用来作为数据库,缓存和消息中间件
它支持多种类型的数据结构,如 字符串(strings),散列(hashes), 列表(lists), 集合(sets),有序集合(sorted sets)与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。
Redis 内置了复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions)
和不同级别的 磁盘持久化(persistence)–RDB和AOP,
并通过Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)。
Redis的基本操作
Redis默认是有16个数据库,默认使用的是第0个数据库,可以通过select 切换数据库,Redis的命令大小写不敏感。
切换数据库
格式:select index

查看数据库大小
格式:dbsize

查看所有的keys
格式:keys *

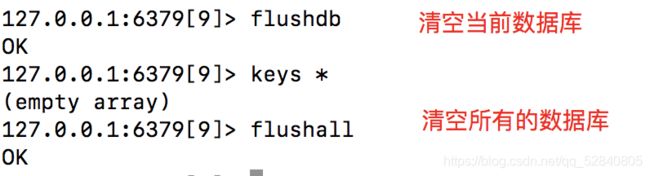
清除数据库
清除当前数据库:flushdb
清除所有数据库:flushall
Redis单线程
Redis是基于内存操作的,CPU不是Redis性能瓶颈,Redis的瓶颈就是根据机器的内存和网络带宽,CPU不是性能瓶颈,就可以使用单线程的
Redis的数据都是存放在内存中,所以说单线程去操作效率就是最高的,相比多线程,减少了CPU上下文切换耗时,对于内存系统而言,没有上下文切换的效率就是最高的,多次读写都是在同一个CPU。
Redis五种基本类型
基本命令
SET 设置key
GET 查看key对应值
EXPIRE 设置key的过期时间
TTL 查看key剩余时间
EXISTS 判断当前key是否存在
KEYS * 查看所有的key
DEL 删除当前key
TYPE 查看key存储的value类型
字符串 string
set get
设置值 set key value
获取值 get key

exists
判断值是否存在 :exists key

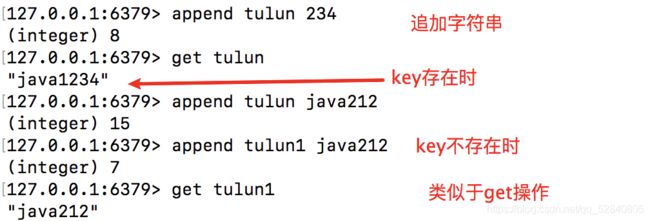
append
追加字符串,如果key不存在,相当于是set命令
格式:append key apendvalue
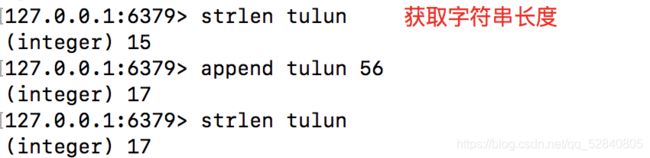
strlen
获取字符串的长度
格式:strlen key
incr decr
对value值进行自增1操作(如果key不存在,会被初始化为0)
格式:incr key
对value值进行自减1操作
格式:decr key

incrby decrby
设置加减的步长
格式:incrby key num decrby key num

getrange
获取给定范围的字符串值
格式:getrange key start stop

setrange
从指定的位置开始替换字符串的值
格式:setrange key offset value

setex ttl
设置过期时间 格式: setex key seconds values
查看剩余时间 格式:ttl key

setnx
setnx(set if not exists) 如果指定的key不存在则设置,存在的失败
格式: setnx key value
(分布式锁经常使用)

mset mget
同时设置多个值 格式:mset key1 value1 key2 value2 ...
同时获取多个值 格式:mget key1 key ...

getset
先获取值在设置值
格式:getset key value

应用场景:
计数器(分散数、统计数)
通常来保存单个字符串或者JSON字符串数据(短信验证码)
列表 list
类似于linkedlist链表结构,可以添加元素到列表的头部或者是尾部,同样头部和尾部都可以进行获取,可以用来作为栈、队列、阻塞队列。
lpush rpush lrange
从列表的左侧插入值 格式:lpush key value
从列表的右侧插入值 格式:rpush key value
从列表中获取指定范围的值 格式:lrange key start stop

lpop rpop
从列表的左侧移除值 格式:lpop key
从列表右侧移除值 格式:rpop key

lindex
获取指定下标的值
格式:lindex key index

llen
获取列表中元素的个数
格式:llen key

lrem
已移除列表中的元素
格式:lrem key count value

ltrim
截取列表中的值
格式:ltrim key start stop

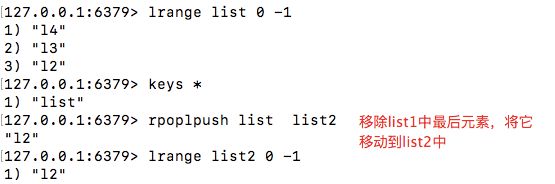
rpoplpush
移除列表中最后一个元素,将他添加到另一个列表中
格式:rpoplpush key1 key2
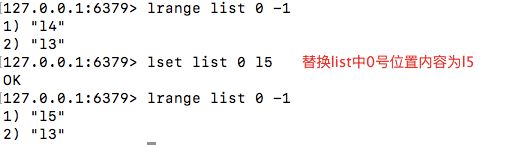
lset
根据下标替换列表中的值
格式:lset key index value
应用场景:
对数据量大的集合进行删减
列表数据显示:评论列表、关注列表、留言列表
list底层是一个链表,在l链表插入或者改动值,效率高,中间位置来修改,相对效率低一些
队列:lpush \rpop
栈: lpush \ lpop
集合 set
set中元素不能重复的
set实现是基于哈希表结构实现,在修改、添加等操作复杂度是O(1)
sadd
在set集合中添加数据
格式:sadd key value

smembers
获取set集合中所有值
格式:smembers key

sismember
判断某个值是否在set中
格式:sismember key value

scard
获取set中元素个数
格式:scard key
![]()
srem
删除set中元素
格式:srem key value

srandmember
从set中随机获取值
格式:srandmember key count

spop
随机删除指定的元素
格式:spop key [count]

应用场景:
利用唯一性:可以统计访问网站的所有独立的ip
对集合间进行求交集、并集、差集 方便实现共同挂住,共同喜欢,二度好友
应用:
哈希 hash
hash是一个map集合,是key-value的map集合
hset hget
插入和获取哈希的值 hset key field value /hget key field

hmset hmget
批量的插入和获取
格式:hmset key field1 value1 field2 value2 ....
获取格式: hmget key field1 field2 ...

hgetall
获取hash中所有的值
格式:hgetalll key

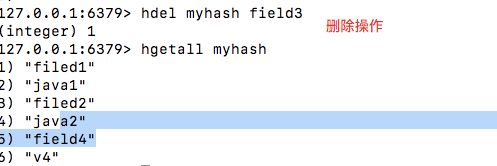
hdel
删除指定的filed 的哈希键值对
格式:hdel key field
hexitsts
判断哈数中字段是否存在
格式:hexists key field
hkeys hvals
获取哈数中所有字段或者值
格式 :hkeys key /hvals key
hsetnx
如果存在,则失败,如果不存在,则添加成功
格式:hsetnx key field value
应用场景:
hash中存储经常变更的对象,比如用户信息: user :name-value age-value ,set-value
hash适合存储对象 ,String适合存储字符串
有序集合 zset
- 每个元素都会关联一个double类型的分数,Redis正是通过分数为集合中的成员进行从小到大的排序
- 有序集合的成员是唯一的,但分数是可以重复
- 有序集合中的命令都是以z开头的
zadd
添加一个元素
格式:zadd key score value

zrange
获取zset中一定范围内的值
格式:zrange key start stop

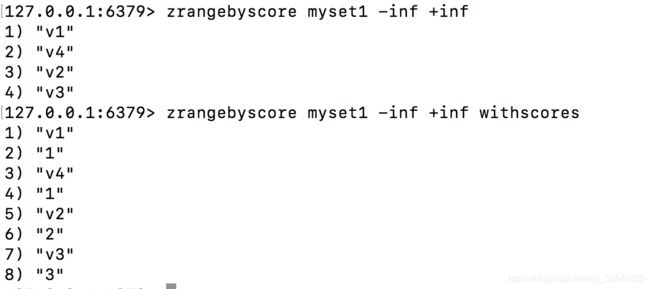
zrangebyscore
将zset中的值按照从小到大排序数据
格式 zrangebyscore min max
zrem
删除zset中指定的元素
格式:zrem key value

zcard
查看zset集合中元素的个数
格式:zcard key

zcount
根据score的值来统计给定区间的元素的个数
格式:zcount key min max

应用场景:
对于需要排序的场景下可以使用zset. 比如微博的实时新闻可以以发表时间作为score来存储,获取时就自动按时间来排好序
Redis三种特殊类型
geospatial地理空间
可以用来实现定位、附近的人、打车APP上距离计算
相关命令:

geoadd
添加地址位置
格式:geoadd key 纬度 经度 名称
对于两级无法直接添加

geopos
返回给定名称的经度和纬度
格式:geopos key 名称
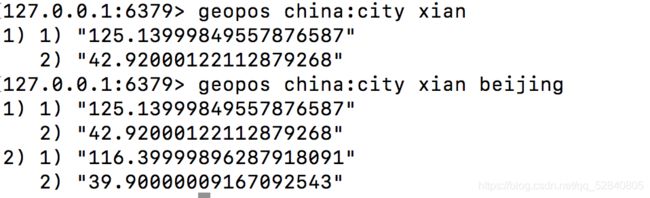
geodist
返回两个给定位置之间的距离
格式:geodist key 名称1 名称2 距离单位
距离单位: m(米) km(千米) mi(英里) ft(英尺)

geohash
返回给定的名称的11位的字符哈希值

georadius
以给定经纬度为中心,找到某一个半径内的元素
附件的人,打车附件可用车辆显示…

georadiusbymember
以一个成员为中心,查找指定范围内的元素

geo的底层实现上是一个zset集合

hyperloglogs
redis中通过hyperloglogs用来进行基数统计的算法
技术估算存在一定的误差,快速计算基数
比如:{1,3 ,5,7,5,7,8}
基数集{1,3,5,7,8} 基础(不重复元素)
pfadd
指定数据到hyperloglog中
pfcount
返回基数的估算值
pfmerge
将多个hyperloglog合并为一个hyperloglog

bitmap
bitmap是位图存储,都是通过二进制来进行记录,所有只有两种状态值的场景,都可以使用
比如:登录、未登录、活跃、不活跃。。。
setbit
在bitmap中添加数据
格式:setbit key offset value
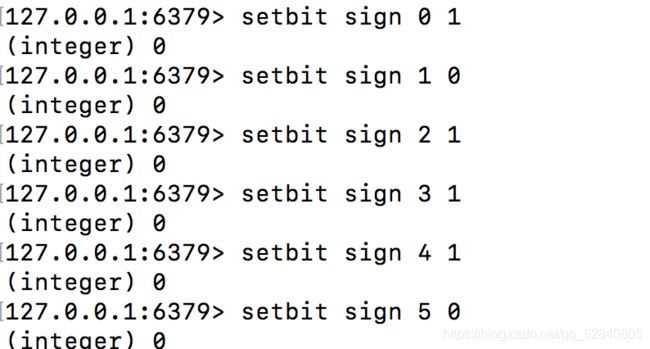
getbit
查看位图上某个位置的值
格式:getbit key offset

bitcount
统计位图上value为1的个数
格式:bitcount key start end
