超分之一文读懂SRGAN
这篇文章介绍SRResNet网络,以及将SRResNet作为生成网络的GAN模型用于超分,即SRGAN模型。这是首篇在人类感知视觉上进行超分的文章,而以往的文章以PSNR为导向,但那些方式并不能让人眼觉得感知到了高分辨率——Photo-Realistic。
参考目录:
①:SRResNet概要
②:深度学习端到端超分辨率方法发展历程
③:GAN-李宏毅
④:GAN的理解(内含③中PPT)
⑤:Pytorch源码
Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
- Abstract
- 1 Introduction
- 2 Method
-
- 2.1 Adversarial network architecture
- 2.2 Perceptual loss function
-
- 2.2.1 Content loss
- 2.2.2 Adversarial loss
- 3 Experiments
-
- 3.1 Data and similarity measures
- 3.2 Training details and parameters
- 3.3 Mean opinion score (MOS) testing
- 3.4 Investigation of content loss
- 3.5 Performance of the final network
- 4 Conclusion
Abstract
- SRGAN本质上是提供了一种新的Loss function——
perceptual loss(感知损失),回忆一下之前的SR都是由MSE损失函数来教会网络如何实现 L R → H R LR\to HR LR→HR,因此在本文中作者就会指出MSE的不足之处:其会对图像的细节进行平滑,使得重建的图像虽然有很高的PSNR,但是失去了人肉眼感知的高分辨率感,即论文中的Photo-Realistic。
本文是实现重建图像photo-realistic的首篇文章,其实现了在up-scale factor较大情况下,图像能有更多的重建细节,因此尽管在PSNR并不高的情况下,产生让人肉眼感官更加舒适的 H R HR HR图像(这其实不就是我们做SR的初衷么,这篇文章也告诉我们不一定PSNR高的图像就是我们追求的最终目标,而是photo-realistic)。具体地,引入GAN网络,因为GAN网络可以产生具有高感知质量的图像,而我们最终目标是使用感知loss去训练一个生成网络 G G G,其中感知loss由adversarial-loss和content-loss组成,这个网络主要由Resnet块组成,因此这个生成网络也叫SRResNet。由于GAN还有一个判别网络 D D D,因此整体的网络模型我们称之为SRGAN!- PSNR/SSIM并不能体现photo-realistic图像的质量,因此作者提出了一种新的图像质量评价指标来反映测试对象和真实高分辨率图像的相似程度,它就是
mean-opinion-score(MOS)。
1 Introduction
图像重建细节受限的原因:
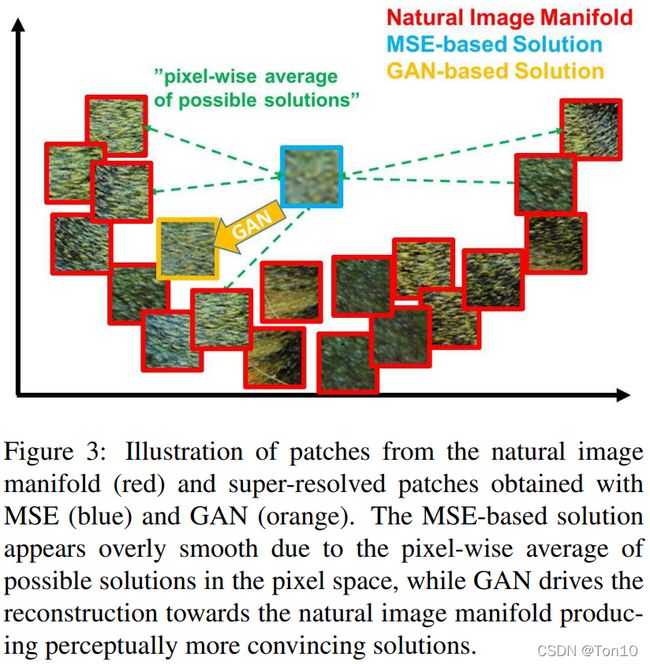 上图中,每一个矩形框都代表着一个像素,其中红色框未作处理的原图,蓝色是用MSE损失函数作为目标函数产生的训练结果,黄色是用感知损失作为目标函数产生的训练结果。从图中可以看出,蓝色框产生的结果在肉眼看来很模糊,这其实是MSE本质上是像素级基础上平均化的计算,因此自然就会将一些图像细节平滑掉(哪怕蓝色框的PSNR很高,我们也不希望是这样的结果)。
上图中,每一个矩形框都代表着一个像素,其中红色框未作处理的原图,蓝色是用MSE损失函数作为目标函数产生的训练结果,黄色是用感知损失作为目标函数产生的训练结果。从图中可以看出,蓝色框产生的结果在肉眼看来很模糊,这其实是MSE本质上是像素级基础上平均化的计算,因此自然就会将一些图像细节平滑掉(哪怕蓝色框的PSNR很高,我们也不希望是这样的结果)。
MSE损失函数的局限性:
虽然直接优化MSE可以产生较高的PSNR/SSIM,但是在up-scale factor较大的情况下,MSE作为loss function引导的学习无法使得重建图像捕获细节信息。
如上图所示,图二(从左边起第二张)虽然能产生较高的PSNR,但是在我们肉眼看来,明显图3拥有更高的分辨率。这就告诉我们,不能单纯的只把PSNR的提高作为优化目标,我们需要较高的PSNR,但是不能说PSNR就是我们的终极目标,不能以PSNR为唯一的目标,因为SR技术的最终目的还是要让人的肉眼感知更高的图像细节(实现photo-realistic),因此我们接下去就要更改MSE损失函数。
2 Method
设 I L R 、 I S R 、 I H R I^{LR}、I^{SR}、I^{HR} ILR、ISR、IHR分别是低分辨率图像、重建图像、高分辨率图像(标签)。
我们的目标是训练出一个生成网络 G θ G G_{\theta_G} GθG,其中 θ G = { W 1 : L ; b 1 : L } \theta_G=\{W_{1:L};b_{1:L}\} θG={W1:L;b1:L}是网络参数空间。
我们用mini-batch的方式来估计生成网络的参数:
θ G ^ = a r g m i n θ G 1 N ∑ n = 1 N l S R ( G θ G ( I n L R ) , I n H R ) . (1) \hat{\theta_G} = argmin_{\theta_G}\frac{1}{N}\sum^N_{n=1}l^{SR}(G_{\theta_G}(I_n^{LR}), I_n^{HR}).\tag{1} θG^=argminθGN1n=1∑NlSR(GθG(InLR),InHR).(1)其中, G θ G ( ⋅ ) G_{\theta_G}(\cdot) GθG(⋅)表示生成网络输出的重建图像 I S R I^{SR} ISR; l S R l^{SR} lSR就是后面2.2节要介绍的感知loss。
2.1 Adversarial network architecture
这一节将对对SRGAN中的生成网络和判别网络进行描述。
GAN解决的是一个MM问题,也就是min-max类型问题,具体的,对于GAN网络来说,其目标函数可定义为:
min θ G max θ D E I H R ∼ p t r a i n ( I H R ) [ l o g D θ D ( I H R ) ] + E I L R ∼ p G ( I L R ) [ l o g ( 1 − D θ D ( G θ G ( I L R ) ) ) ] . (2) \min_{\theta_G}\max_{\theta_D}\mathbb{E}_{I^{HR}\sim p_{train}(I^{HR})}[log D_{\theta_D}(I^{HR})] + \mathbb{E}_{I^{LR}\sim p_G(I^{LR})}[log(1-D_{\theta_D}(G_{\theta_G}(I^{LR})))].\tag{2} θGminθDmaxEIHR∼ptrain(IHR)[logDθD(IHR)]+EILR∼pG(ILR)[log(1−DθD(GθG(ILR)))].(2)
①:首先我们来看内层的maximization部分,相当于固定 θ G \theta_G θG不动,来学习调整 θ D \theta_D θD,也就是说内层是Discrimination(判别)网络的目标函数,为的是训练一个判别器网络 θ D \theta_D θD。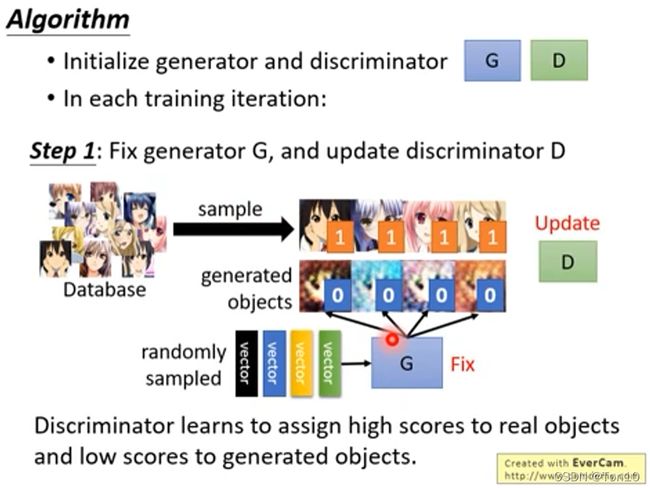 它背后的思想就是给 I H R I^{HR} IHR(标签)打一个高的分数,给经过生成网络出来的 I S R I^{SR} ISR一个低的分数,刚开始的时候判别网络 D D D往往很容易判别,因为生成网络的结果会和标签差别很大,比如判别器只需要认准图片中是否含有眼睛就可以区分是生成网络的结果还是标签。
它背后的思想就是给 I H R I^{HR} IHR(标签)打一个高的分数,给经过生成网络出来的 I S R I^{SR} ISR一个低的分数,刚开始的时候判别网络 D D D往往很容易判别,因为生成网络的结果会和标签差别很大,比如判别器只需要认准图片中是否含有眼睛就可以区分是生成网络的结果还是标签。
②:然后再来看外层,固定住判别网络参数,来学习调整生成网络的参数。
它的目的就是通过调整 θ G \theta_G θG来使得 D θ D ( G θ G ( I L R ) ) D_{\theta_D}(G_{\theta_G}(I^{LR})) DθD(GθG(ILR))尽可能变大,也就是说生成器网络的训练是为了让输出的结果通过判别网络输出一个较高的分数,从而骗过判别器,让判别器以为是标签 I H R I^{HR} IHR。
③:因此我们可以看出生成器变强之后,也会促使下一次判别网络会继续变强,增加区分真假的能力;再轮到生成器,他会继续增加假货(输入经过 G G G之后的输出)在判别器的分数,然后判别器继续提升,不断循环迭代,两者互相对抗,互相成长,最好训练得到的生成器网络就是我们所想要的网络。最后我们来看一下最初时候GAN的伪代码:
接下来我们来看一下SRGAN里的生成网络 G G G和判别网络 D D D是怎么样的吧?

①:从上图来看,SRGAN网络的生成网络部分就是一个以 B B B个Resnet块组成的深度网络。其中比如“k9n64s1”指的是 n = 64 n=64 n=64个 9 × 9 9\times 9 9×9,stride为1的卷积核。既然用到了Resnet,自然主要目的就是使用skip connection来加强信息跨层之间的流动以及防止网络深度的加深导致的梯度消失问题。单看SRResNet的结构和SRDenseNet类似,分为低层特征提取、高层特征提取、反卷积(转置卷积)层以及最后的CNN重建层。
②:SRGAN网络的判别网络部分就是为了训练式(2)的maximization部分,它就是很普通的一个CNN网络,其中激活函数使用Leaky-ReLU( α = 0.2 \alpha=0.2 α=0.2)来防止一些负性输出坏死;此外,网络的末端使用了Dense块再接sigmoid函数做一个二分类(其实就是对 I S R I^{SR} ISR和 I H R I^{HR} IHR进行打分)。整体的判别网络就是一个没有池化层的VGG网络,其中每经过一次跨步卷积(主要为了减少冗余信息的计算),图像的size就会减小,接着下一层feature map的数量就会翻倍。
2.2 Perceptual loss function
接下来介绍生成网络的Loss function——感知损失函数。在之前我们的Loss一般都是MSE,但是正如之前所说的MSE无法很好的恢复图像的细节,故我们改采用感知损失:
l S R = l X S R ⏟ c o n t e n t l o s s − 1 0 − 3 ⋅ l G e n S R ⏞ a d v e r s a r i a l l o s s . (3) \begin{matrix} l^{SR} = \underbrace{l_X^{SR}}_{content\,loss} - \overbrace{10^{-3}\cdot l_{Gen}^{SR}}^{adversarial\,loss}.\tag{3} \end{matrix} lSR=contentloss lXSR−10−3⋅lGenSR adversarialloss.(3)Note:
- 我们采用感知损失来训练生成网络,它由内容损失:文中取MSE或者VGG损失以及一定比率的对抗损失(GAN网络本身就有的损失函数)组成。
- SRResNet是只由MSE损失函数训练的,而不是感知损失,但是网络还是用的上面的网络;而SRGAN的训练中,生成网络部分才使用感知损失训练的。
2.2.1 Content loss
内容损失有2种方案:
- pixel-wise级的MSE损失。
- feature-map-wise级的VGG损失。
下面我们分别展开来介绍。
①:首先是MSE损失,之所以还启用MSE损失,是因为PSNR也是我们比较看重的一个点,我们强调肉眼感知上的高分辨率,但也不能少了PSNR的评价,因此MSE可作为总体loss的一部分:
l X S R = l M S E S R = 1 r 2 ⋅ W ⋅ H ∑ x = 1 r W ∑ y = 1 r H ( I x , y H R − G θ G ( I L R ) x , y ) 2 . (4) l_X^{SR} = l_{MSE}^{SR} = \frac{1}{r^2\cdot W\cdot H}\sum_{x=1}^{rW}\sum_{y=1}^{rH}(I_{x,y}^{HR} - G_{\theta_G}(I^{LR})_{x,y})^2.\tag{4} lXSR=lMSESR=r2⋅W⋅H1x=1∑rWy=1∑rH(Ix,yHR−GθG(ILR)x,y)2.(4)
②:然后我们来介绍VGG损失,所谓的VGG损失是作者采用预训练好的VGG-19网络的特征向量,使得生成网络的结果通过VGG某一层之后产生的feature map和标签 I H R I^{HR} IHR通过VGG网络产生的feature map做loss,作者指出这种loss更能反应图片之间的感知相似度。
具体的,定义 ϕ i , j \phi_{i,j} ϕi,j表示VGG网络第 j j j层卷积之后,第 i i i层最大池化层之前的feature map输出,则VGG-loss可表示为:
l X S R = l V G G / ( i , j ) S R = 1 W i , j H i , j ∑ x = 1 W i , j ∑ y = 1 H i , j ( ϕ i , j ( G θ G ( I L R ) ) x , y − ϕ i , j ( I H R ) x , y ) 2 . (5) l_X^{SR} = l_{VGG/(i,j)}^{SR} = \frac{1}{W_{i,j}H_{i,j}}\sum_{x=1}^{W_{i,j}}\sum_{y=1}^{H_{i,j}}(\phi_{i,j}(G_{\theta_G}(I^{LR}))_{x,y} - \phi_{i,j}(I^{HR})_{x,y})^2.\tag{5} lXSR=lVGG/(i,j)SR=Wi,jHi,j1x=1∑Wi,jy=1∑Hi,j(ϕi,j(GθG(ILR))x,y−ϕi,j(IHR)x,y)2.(5)Note:
- W 和 H W和H W和H分别表示VGG网络中feature map的维度,一般指的是feature map的张数。
- VGG损失是feature-map-wise,它拥有比MSE更好地能力去衡量感知上的相似度。也容易理解,feature-map-wise是对 H R 和 S R HR和SR HR和SR图像整体做loss,因此它提升的是 S R SR SR图像整体感知;而MES是针对像素级(pixel-wise),这样很容易将图像局部细节平滑掉。这一点在后续实验中也会体现出来。
2.2.2 Adversarial loss
对抗损失函数就是GAN中常用的形式,我们要最小化:
l G e n S R = ∑ n = 1 N − l o g D θ D ( G θ G ( I L R ) ) . (6) l_{Gen}^{SR} = \sum^N_{n=1}-log D_{\theta_D}(G_{\theta_G}(I^{LR})).\tag{6} lGenSR=n=1∑N−logDθD(GθG(ILR)).(6)背后的目的就是要让生成网络的结果产生较高的判别值来骗过判别网络。
3 Experiments
3.1 Data and similarity measures
- 文章采用的数据集如下:Set5、Set14、BSD100、BSD300、ImageNet。
- up-scale-factor = 4。
- PSNR/SSIM只在Y通道上计算。
- 实验中对比的算法如下:Nearest Neighbor(NN)、Bicubic、SRCNN、SelfExSR、DRCN、ESPCN、SRResNet变体(SRResNet(MSE-based)、SRResNet(VGG22-based))、SRGAN变体(SRGAN(MSE-based)、SRGAN(VGG22-based)、SRGAN(VGG54-based))。
3.2 Training details and parameters
- 作者从ImageNet上取下35W张图片作为网络的训练集,然后将裁剪后的 96 × 96 96\times 96 96×96的 H R HR HR图片通过Bicubic × 4 \times 4 ×4下采样得到 L R LR LR图像。
- mini-batch=16。
- 生成网络部分设置16个残差块。
- 采用Adam做优化。
- SRResNet(MSE-based)使用学习率为 1 0 − 4 10^{-4} 10−4训练100W个epoches。对于SRGAN的训练,由于SRResNet可以作为SRGAN的生成网络,因此作者将训练好的SRResNet的参数作为生成网络的初始参数来避免陷入局部最优。
- SRGAN变体的训练方式:前10W个epoches采用 1 0 − 4 10^{-4} 10−4的学习率,后10W个epoches采用 1 0 − 5 10^{-5} 10−5的学习率。
3.3 Mean opinion score (MOS) testing
作者提出了一种叫MOS图像评价指标,用于衡量重建图像的感知质量。
MOS就是让26个评分人对图片进行打分,其中最低为1分(低视觉质量),最高为5分(高视觉质量)。
实验中,作者对12种算法在Set5、Set14、BSD100数据集上打分,其中SRResNet(VGG22-based)、SRGAN(MSE-based)、SRGAN(VGG22-based)这三种不在BSD100数据级上打分,所以一共要对1128( 12 × 19 + 9 × 100 12\times 19 + 9\times 100 12×19+9×100)张图片进行打分。
因此MOS是一种人主观意识层面的打分系统,其直接和图片的photo-realistic相关。
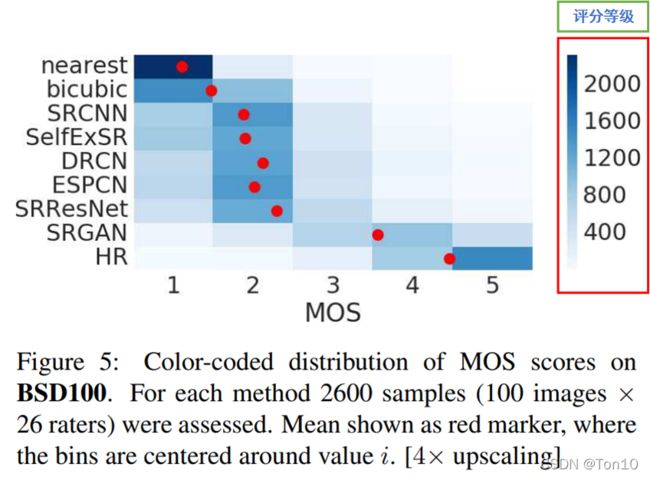
上图是26个评分人对BSD100数据集的打分统计,红色的点是对某个算法在2600张图片种的平均值,比如对于HR图像,大部分评价分数都是5分,可以看出蓝色部分很深,但也有少部分3分或者4分,因此平均下来就是靠近5分但不到的样子,平均的思想就是MOS名字种Mean来源。
3.4 Investigation of content loss
这一节是对两个变体的表现力比较,主要评价指标是PSNR/SSIM以及MOS。
SRResNet变体(SRResNet(MSE-based)、SRResNet(VGG22-based))。
SRGAN变体(SRGAN(MSE-based)、SRGAN(VGG22-based)、SRGAN(VGG54-based))。
首先先对这5种模型进行说明:
- SRResNet(MSE-based):以MSE为内容损失函数,没有对抗损失,后面的SRResNet就是指MSE-based。
- SRResNet(VGG22-based):以VGG22损失函数为内容损失,没有对抗损失。
- SRGAN(MSE-based):以MSE为内容损失函数,外加2.2.2节的对抗损失。
- SRGAN(VGG22-based):以VGG22损失函数为内容损失,主要用于捕获低层细节,外加2.2.2节的对抗损失。
- SRGAN(VGG54-based):以VGG54损失函数为内容损失,主要用于捕获高层细节,外加2.2.2节的对抗损失,后面的SRGAN一般指的就是以VGG54为内容损失函数。
实验结果如下:

- 从上述实验中我们可以看出,SRGAN虽然不能获取最佳的PSNR,但是却有着更好的视觉效果,能体现更多的细节,这一点从MOS值也可以看出来,可以说SRGAN实现了photo-realistic。
- 在SRResNet中,VGG-based要比MSE-based有更高的MOS值,说明feature-map-wise要比pixel-wise有更好的感知能力,可以训练出更多的图像细节。
- 从SRResNet(MSE-based)和SRGAN(MSE-based)来看,可以比较得出之所以SRGAN(MSE-based)的PSNR较低而MOS较高,是因为MSE作为内容损失和对抗损失内部竞争的结果,即PSNR的提升和感知质量的提升是对抗性的。
- 此外,SRResNet也实现了较高的PSNR值。
- 从Set14可以看出,VGG54-based比VGG22-based的MOS更高,说明更高层的图像特征会产生更多的图像细节,使得可以重建出视觉上更好的高分辨率图像。
3.5 Performance of the final network

从上图中我们可以获取2个重要结论:
- SRResNet在PSNR/SSIM上可以取得SOAT的结果。
- SRGAN获得最高的MOS值,说明其可以重建出更好的图像细节,在视觉上更加舒适,即实现了photo-realistic。
4 Conclusion
- 本文提出了在SISR领域的一种称之为SRGAN模型,其可以重建出具有较高感知质量,即人肉眼感知舒适的,具有丰富细节的图像。
- SRResNet可以单独作为一个SR网络,作者采用MSE为Loss函数,使用 × 4 \times 4 ×4的缩放倍数和16个残差块来实现当时的SOAT。
- SRGAN中的生成网络就是SRResNet网络,其以ResNet块为基本结构,是一个具有深度的SR网络。生成网络使用感知损失进行训练,而不是传统的MSE方法,它使用预训练之后的VGG网络产生的feature map级进行计算,再加上本身生成网络带有的对抗损失。此外判别器也需要去训练,两个网络结合起来就是我们的SRGAN网络。
- 本文提出了一种新的用于评价图像photo-realistic的标准——MOS,SRGAN在这个指标下达到了最佳的性能,重建出人肉眼感知最舒适的高分辨率图像。