SRGAN 超分辨率生成对抗网络模型
简介:
SRGAN全称为 Super Resolution Generative Adversarial,这是第一个对放大四倍真实自然图像做超分辨率的框架【模糊变清晰,有码变无码(狗头)】
生成器模型:
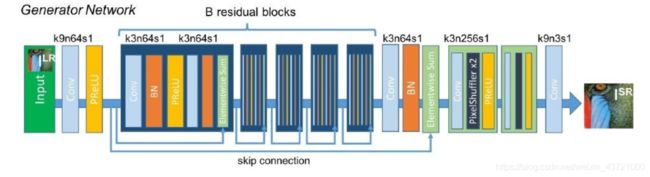
1.输入是一张低分辨率的图像
2.进入一个64通道步长为1的卷积
3.RELU激活
4.自定义个数的残差卷积快(每个卷积快结构:【1】64通道步长为1的卷积【2】BN参数标准化【3】RELU激活【4】64通道步长为1的卷积【5】BN参数标准化【6】将当前残差块之前的参数与当前参数连接)
5.进入一个64通道步长为1的卷积
6.BN参数标准化
7.将第一个残差块之前的参数与当前参数连接
8.【1】进入一个256通道步长为1的卷积【2】上采样或反卷积,将图片扩大至现在的两倍【3】RELU激活
9.重复第8步
10.进入一个3通道步长为1的卷积
11.输出是一张高分辨率假图
生成器代码【Keras】:
def build_generator(self):
'''
生成器模型代码,实现方法减少了一些网络层数
'''
# 残差卷积快
def residual_block(layer_input, filters):
d = Conv2D(filters, kernel_size=3, strides=1, padding='same')(layer_input)
d = BatchNormalization(momentum=0.8)(d)
d = Activation('relu')(d)
d = Conv2D(filters, kernel_size=3, strides=1, padding='same')(d)
d = BatchNormalization(momentum=0.8)(d)
d = Add()([d, layer_input])
return d
# 上采样
def deconv2d(layer_input):
u = UpSampling2D(size=2)(layer_input)
u = Conv2D(256, kernel_size=3, strides=1, padding='same')(u)
u = Activation('relu')(u)
return u
# 输入大小为128,128,3
img_lr = Input(shape=self.lr_shape)
# 第一部分,低分辨率图像进入后会经过一个卷积+RELU函数
c1 = Conv2D(64, kernel_size=9, strides=1, padding='same')(img_lr)
c1 = Activation('relu')(c1)
# 第二部分,经过16个残差网络结构,每个残差网络内部包含两个卷积+标准化+RELU,还有一个残差边。
r = residual_block(c1, 64)
for _ in range(self.n_residual_blocks - 1):
r = residual_block(r, 64)
# 第三部分,将第一个残差块之前的参数与当前参数连接。
c2 = Conv2D(64, kernel_size=3, strides=1, padding='same')(r)
c2 = BatchNormalization(momentum=0.8)(c2)
c2 = Add()([c2, c1])
# 第四部分,上采样部分,将长宽进行放大,两次上采样后,变为原来的4倍,实现提高分辨率。
u1 = deconv2d(c2)
u2 = deconv2d(u1)
gen_hr = Conv2D(self.channels, kernel_size=9, strides=1, padding='same', activation='tanh')(u2)
# 返回模型
return Model(img_lr, gen_hr)
判定器模型:

1.输入是一张高分辨率真实图像,或者生成器生成的高分辨率假图
2.进入一个64通道步长为1的卷积
3.RELU激活
4.【1】进入一个64通道步长为2的卷积【2】BN参数标准化【3】RELU激活
5.【1】进入一个128通道步长为1的卷积【2】BN参数标准化【3】RELU激活
6.【1】进入一个128通道步长为2的卷积【2】BN参数标准化【3】RELU激活
7.【1】进入一个256通道步长为1的卷积【2】BN参数标准化【3】RELU激活
8.【1】进入一个256通道步长为2的卷积【2】BN参数标准化【3】RELU激活
9.【1】进入一个512通道步长为1的卷积【2】BN参数标准化【3】RELU激活
10.【1】进入一个512通道步长为2的卷积【2】BN参数标准化【3】RELU激活
11.通过1024个神经元的全连接层
12.RELU激活
13.通过1个神经元的全连接层
14.S型函数输出判定结果
ps:进入全连接层之前,一共进行了四次步长为2的卷积,图片大小变为原来的1/16
判定器代码【Keras】:
def build_discriminator(self):
'''
判定器模型代码
'''
# 几个相似的模型层
def d_block(layer_input, filters, strides=1, bn=True):
d = Conv2D(filters, kernel_size=3, strides=strides, padding='same')(layer_input)
d = LeakyReLU(alpha=0.2)(d)
if bn:
d = BatchNormalization(momentum=0.8)(d)
return d
# 由一堆的卷积+LeakyReLU+BatchNor构成
d0 = Input(shape=self.hr_shape)
d1 = d_block(d0, 64, bn=False)
d2 = d_block(d1, 64, strides=2)
d3 = d_block(d2, 128)
d4 = d_block(d3, 128, strides=2)
d5 = d_block(d4, 256)
d6 = d_block(d5, 256, strides=2)
d7 = d_block(d6, 512)
d8 = d_block(d7, 512, strides=2)
d9 = Dense(64 * 16)(d8)
d10 = LeakyReLU(alpha=0.2)(d9)
validity = Dense(1, activation='sigmoid')(d10)
# 返回模型
return Model(d0, validity)
向训练好的生成器中传入低分辨率图片(共训练了10000轮):
输入图片:本次训练输入图片像素大小固定为32*32

输出图片:输出图片像素大小扩展为原来的4倍(128*128)

生成网络通过自身的训练参数,根据传入的低分辨率图像自行绘制了一张高分辨率图像,由于32*32像素的输入图像的可提取特征较少,所以一些脸部的皱纹提取不到,输出结果中的女人会比打码之前显得年轻一点点(狗头)