《利用Python进行数据分析》第七章数据预处理相关知识点总结
1、缺失值的处理
Series与DataFrame的dropna可以去除数据中的缺失值
import pandas as pd
from numpy import nan as NA
data = pd.Series([1,NA,3,NA,7])
data

data.dropna()

同时,可以使用fillna来填充缺失值,并换成自己想要的值。
import numpy as np
df = pd.DataFrame(np.random.randn(7,3))
df.iloc[:4,1] = NA
df.iloc[:2,2] = NA
df

使用fillna返回的是一个新对象。
df.fillna({1:0.5, 2:0})

2、数据转换
这种情况下,duplicated方法返回的是一个布尔值Series,这个Series反应的是每一行是否存在重复(与之前出现过的行相同的情况)DataFrame也同样适用。
data1 = pd.DataFrame({'k1':['one','two']*3 + ['two'],
'k2':[1,1,2,3,3,4,4]})
data1

data1.duplicated()

drop_duplicates返回的是DataFrame 内容是duplicated返回数组中为False的部分。
data1.drop_duplicates()

如果想基于k1列去除重复值:
data1.drop_duplicates(['k1'])

下面是map函数相关用法,运用map方法接收一个函数或一个包含映射关系的自典型对象。
data2 = pd.DataFrame({'food':['bacon','pulled pork','bacon','pastrami','corned beef','bacon','pastrami','honey ham','nova lox'],
'ounces':[4,3,12,6,7,8,3,5,6]})
data2

输入食物与肉类的映射
meat_to_animal = {
'bacon':'pig',
'pulled pork':'pig',
'pastrami':'cow',
'corned beef':'cow',
'honey ham':'pig',
'nova lox':'salmon'
}
再使用map方法将肉类匹配到DataFrame的食物中。
data2['animal'] = data2['food'].map(meat_to_animal)
data2

接下来介绍更改索引名的方法。
data4 = pd.DataFrame(np.arange(12).reshape(3,4),
index = ['ohio','Colorado','New York'],
columns = ['one','two','three','four'])
data4
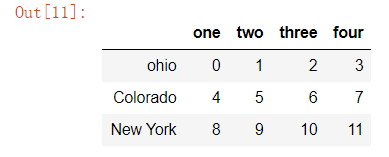
将列名改为大写,行名为首字母大写
data4.rename(index=str.title, columns=str.upper)

也可以结合字典对象更改列名。
data4.rename(index={'ohio':'INDIANA'},
columns={'three':'peekaboo'})
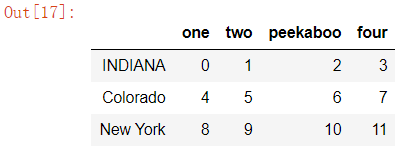
下面介绍的是分箱操作的cut方法(让我联想到了jieba包的cut)
ages=[20,22,25,27,21,23,37,31,61,45,41,32]
bins=[18,25,35,60,100]
cats = pd.cut(ages, bins)
cats

你看到的输出描述了pandas的cut计算出的箱。即ages对应的每个数的所在区间。
cats.codes

0,1,2,3分别代表categories中的区间序号。
你还可以通过向labels传递一个列表或数组来自定义箱名。
group_names = ['Young','YoungAdult','MiddleAged','Senior']
pd.cut(ages,bins,labels=group_names)

同时,也可以使用cut函数将数据切成n(指定数量)份,其切割方式为:
数据里的(最大值-最小值)/n=每个区间的间距
利用数据中最大值和最小值的差除以分组数作为每一组数据的区间范围的差值。
data = np.random.rand(20)
print(data)
result = pd.cut(data,4,precision=2) #precision保留小数点的有效位数
print(result)
res_data=pd.value_counts(result)
print(res_data)

如果用服从正态分布分箱,可以均匀分出四等分
data = np.random.randn(1000)#data服从正态分布
cats = pd.qcut(data, 4)#将data均匀分成四份
cats
![]()
pd.value_counts(cats)#data里面的元素服从正态分布,长度为1000,qcut将data按照每250的数据量将data分箱,分出4个等长的箱

any方法:要选出所有大于3或小于-3的行 可以使用any方法
data5 = pd.DataFrame(np.random.randn(1000,4))
data5[(np.abs(data5)>3).any(1)]
同时,对数据的随机抽样可以用sample方法来实现。
#随机抽样
choices = pd.Series([5,7,-1,6,4])
draws = choices.sample(n=10, replace=True)#replace允许有重复选择
draws

3、字符串操作
对于字符串组成的列表,可以使用join方法来改变分隔符:
pieces = ['a','b','guido']
'::'.join(pieces)
输出结果'a::b::guido'
同时还有个replace方法,但是对象必须是字符串,如果列表带入会报错
pieces.replace(',','')

尝试将列表转为str:
str(pieces).replace(',','')
输出"['a' 'b' 'guido']"
接下来通过正则表达式处理字符串。
正则表达式中,描述一个或多个空白字符的是\s+。
import re
text = 'foo bar\t baz \tqux'
re.split('\s+', text)
输出['foo', 'bar', 'baz', 'qux']
如果你想获得的是一个所有匹配正则表达式的模式的列表 你可以使用findall方法。
re.findall('\s+',text)
输出[' ', '\t ', ' \t']
如果用另一种表达方法,可以节省CPU周期。
regex = re.compile('\s+')
regex.split(text)
利用正则表达式,提取邮箱。
text2 = '''Dave [email protected]
Steve [email protected]
Rob [email protected]
Ryan [email protected]
'''
#-为转义符号 .+为贪婪匹配 非贪婪匹配为.+?
pattern = r'[A-Z0-9._%+]+@[A-Z0-9.]+\.[A-Z]{2,4}'
regex = re.compile(pattern, flags=re.IGNORECASE) #IGNORECASE使正则表达式不区分大小写
regex.findall(text2)
输出['[email protected]', '[email protected]', '[email protected]', '[email protected]']
更多正则表达式方法,我认为这位大佬博主写的详细:https://blog.csdn.net/qq_28633249/article/details/77686976?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522159506162519724835839844%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=159506162519724835839844&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allfirst_rank_ecpm_v3~pc_rank_v3-2-77686976.pc_ecpm_v3_pc_rank_v3&utm_term=%E6%AD%A3%E5%88%99%E8%A1%A8%E8%BE%BE%E5%BC%8F
其中的search方法返回的是文本中第一个匹配到的电子邮件的地址。
m = regex.search(text2)
m
输出
如果对正则表达式加上括号,则产生的匹配对象是groups方法,返回的是模式组件的元组。
pattern1 = r'([A-Z0-9._%+]+)@([A-Z0-9.]+)\.([A-Z]{2,4})'
regex1 = re.compile(pattern1, flags=re.IGNORECASE)
#修改后的正则表达式产生的匹配对象的groups方法 返回的是模式组件的元组
m = regex1.match('[email protected]')
m.groups()
输出('wesm', 'bright', 'net')
以上就是我认为本章比较重要的知识点,内容较多,如果有不足之处,还请指出。