Pytorch Image Models (timm)
计算机视觉模型库–Pytorch Image Models (timm)
帮助文档
"timm"是由Ross Wightman创建的深度学习库,是一个关于SOTA的计算机视觉模型、层、实用工具、optimizers, schedulers, data-loaders, augmentations,可以复现ImageNet训练结果的训练/验证代码。
Install
pip install timm
使用方法
创建模型
import timm
import torch
model = timm.create_model('resnet34')
x = torch.randn(1, 3, 224, 224)
model(x).shape
如果是要创建一个预训练的模型,则只要设置pretrained=True即可。
pretrained_resnet_34 = timm.create_model('resnet34', pretrained=True)
创建一个定制化类别数量的模型,只需设置num_classes=
import timm
import torch
model = timm.create_model('resnet34', num_classes=10)
x = torch.randn(1, 3, 224, 224)
model(x).shape
输出:
torch.Size([1, 10])
具有预训练权重的模型列表
timm.list_models()返回timm中所有模型的列表,如果要查看具有预训练权重的模型,只需设置pretrained=True
avail_pretrained_models = timm.list_models(pretrained=True)
len(avail_pretrained_models), avail_pretrained_models[:5]
输出
(271,
['adv_inception_v3',
'cspdarknet53',
'cspresnet50',
'cspresnext50',
'densenet121'])
使用关键词检索模型架构
all_densenet_models = timm.list_models('*densenet*')
all_densenet_models
输出
['densenet121',
'densenet121d',
'densenet161',
'densenet169',
'densenet201',
'densenet264',
'densenet264d_iabn',
'densenetblur121d',
'tv_densenet121']
定制化模型的通道数量
一般,ImageNet数据包含3通道的RGB图片
设置单一通道
m = timm.create_model('resnet34', pretrained=True, in_chans=1)
# single channel image
x = torch.randn(1, 1, 224, 224)
m(x).shape
输出
torch.Size([1, 1000])
设置25通道数
m = timm.create_model('resnet34', pretrained=True, in_chans=25)
# 25-channel image
x = torch.randn(1, 25, 224, 224)
m(x).shape
输出
torch.Size([1, 1000])
timm中的处理方法
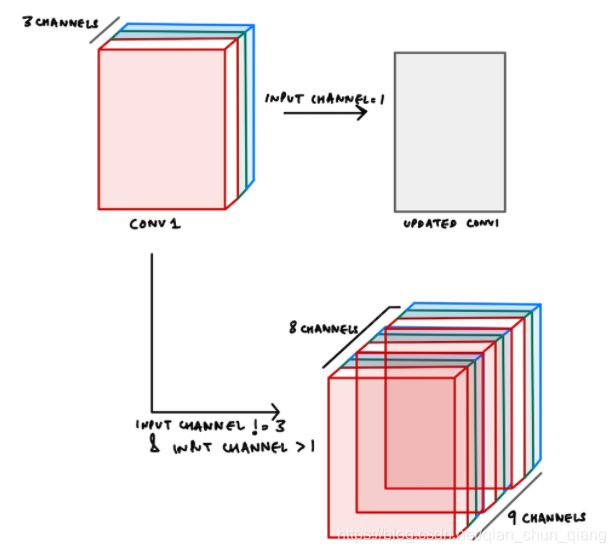
Case-1:当输入通道数=1
timm简单地将原3通道权重相加成单通道权重,并更新权重的shape
conv1_weight = state_dict['conv1.weight']
conv1_weight.sum(dim=1, keepdim=True).shape
Case-2:当输入通道数不等于1
假设通道数为8,则先将原先的3通道复制3次变为9通道,然后选择前8个通道
conv1_name = cfg['first_conv']
conv1_weight = state_dict[conv1_name + '.weight']
conv1_type = conv1_weight.dtype
conv1_weight = conv1_weight.float()
repeat = int(math.ceil(in_chans / 3))
conv1_weight = conv1_weight.repeat(1, repeat, 1, 1)[:, :in_chans, :, :]
conv1_weight *= (3 / float(in_chans))
conv1_weight = conv1_weight.to(conv1_type)
state_dict[conv1_name + '.weight'] = conv1_weight