Going Deeper with Convolutions
参考链接:https://cloud.tencent.com/developer/article/1338331
https://zhuanlan.zhihu.com/p/42124583
https://blog.csdn.net/sunlianglong/article/details/79956734
https://blog.csdn.net/shuzfan/article/details/50738394
创新点:
GoogLeNet的创新点都是围绕减少深度和提高性能来设计的。
- 借鉴NiN(Network in Network)中提出的思想,采用1×1 conv 来保持空间维度的同时,降低深度,也就是降低通道数量,同时1×1 conv还可以为你的网络增强非线性。
- 横向的卷积核排列设计,使得多个不同size的卷积核能够得到图像当中不同cluster的信息 ,我们称之为“多尺度”。这样融合了不同尺度的卷积以及池化,一个模块一层就可以得到多个尺度的信息,下一阶段也可以同时从不同尺度中提取的特征,可以进行多维度特征的融合,所以效果更好。把计算力拓宽,也避免了太深训练梯度弥散的问题。
- 对深度相对较大的网络来说,梯度反向传播能够通过所有层的能力就会降低。文中指出:“在这个任务上,更浅网络的强大性能表明网络中部层产生的特征应该是非常有识别力的”。通过将辅助分类器添加到这些中间层,可以提高较低阶段分类器的判别力,这是在提供正则化的同时克服梯度消失问题。后面的实验表明辅助网络的影响相对较小(约0.5),只需要其中一个辅助分类器就能取得同样的效果。
- 较高层会捕获较高的抽象特征,其空间集中度会减少。这表明随着网络转移到更高层,Inception架构中3×3和5×5卷积的比例应该会增加。而到最后一个卷积层出来的全连接,由全局平均池化替代了,减少了参数,节约了计算量。
Motivation
提高深度神经网络性能最直接的方式是增加它们的深度和宽度。但是这个简单方案有两个主要的缺点。
1.更大的尺寸通常意味着更多的参数,这会使增大的网络更容易过拟合,尤其是在训练集的标注样本有限的情况下。
2.计算资源使用的显著增加。
解决这两个问题的一个基本的方式就是:全连接甚至一般的卷积都转化为稀疏连接。
但是在实现上,全连接变成稀疏连接后实际计算量并不会有质的提升,因为大部分硬件是针对密集矩阵计算优化的,稀疏矩阵虽然数据量少,但是计算所消耗的时间却很难减少。
那么,有没有一种方法既能保持网络结构的稀疏性,又能利用密集矩阵的高计算性能。大量的文献表明可以将稀疏矩阵聚类为较为密集的子矩阵来提高计算性能,就如人类的大脑是可以看做是神经元的重复堆积,因此,GoogLeNet团队提出了Inception网络结构,就是构造一种“基础神经元”结构,来搭建一个稀疏性、高计算性能的网络结构。
Inception naive结构如下:
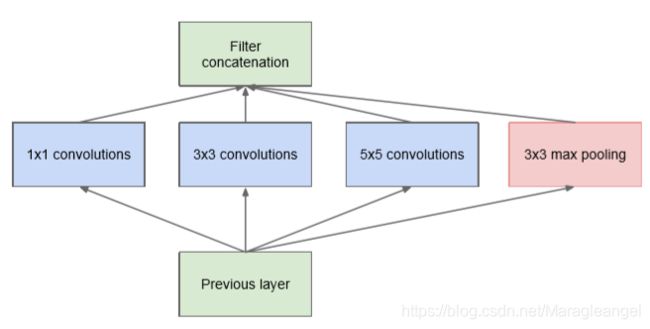
Inception 模块的作用:
- Inception 模块会并行计算同一输入映射上的多个不同变换,并将它们的结果都连接到单一一个输出。换句话说,对于每一个层,Inception 都会执行 5×5 卷积变换、3×3 卷积变换和最大池化。然后该模型的下一层会决定是否以及怎样使用各个信息。
- Inception可以看做是在水平方向上加深了网络
结合实际理解Inception:
下面给出一个实际的示例理解上面的Inception 模块。对于下图中的狗,在每张图片中大小不一样,特征尺度变化也很大。

- 由于特征尺度变化特别大,卷积操作选择适当的核尺寸变得较为困难。特征尺度较大的比较适合于较大的核,而特征尺度小的适合较小的核。
- 简单的加深网络,容易造成梯度发散,而且计算量会变大。
那为什么不能在同一层上采用多个尺寸的过滤器,使得网络本质上会变得更宽一些,而不是更深。作者设计 inception 模块就是用了这个想法。
naive Inception缺点
上述模块的一个大问题是在具有大量滤波器的卷积层之上,即使适量的5×5卷积也可能是非常昂贵的。经过pooling层输出的合并,最终可能会导致数量级增大不可避免。处理效率不高导致计算崩溃。而这种计算成本增长就成为了我们模型的致命瓶颈。
这导致了Inception架构的第二个想法:
在需要大量计算的地方进行慎重的降维。压缩信息以聚合。1*1卷积不仅用来降维,还用来修正线性特性。只在高层做这个,底层还是普通的卷积。
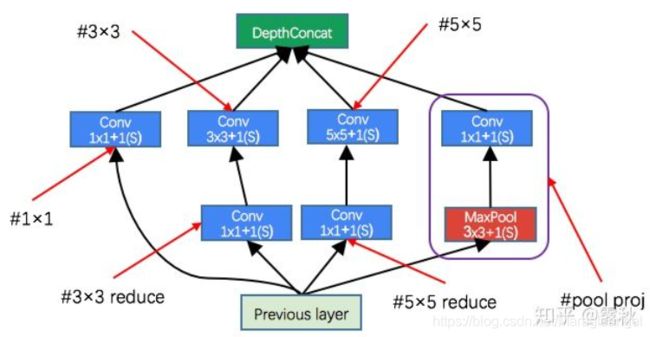
改进方法之Inception v1
Inception v1的网络结构如下图:
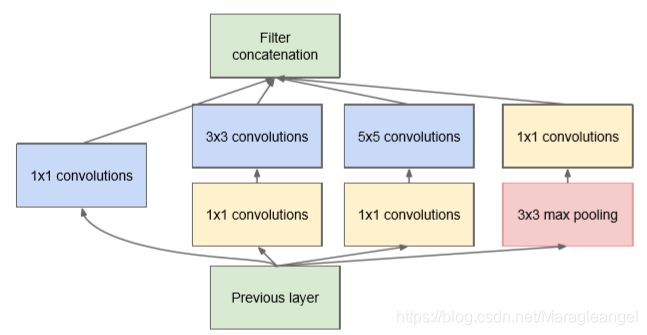
使用1*1卷积的作用:
- 降维( dimension reductionality )。比如,一张500 * 500 depth为100 的图片在20个filter上做1*1的卷积,那么结果的大小为500*500*20。
- 加入非线性。卷积层之后经过激励层,1*1的卷积在前一层的学习表示上添加了非线性激励( non-linear activation ),提升网络的表达能力;
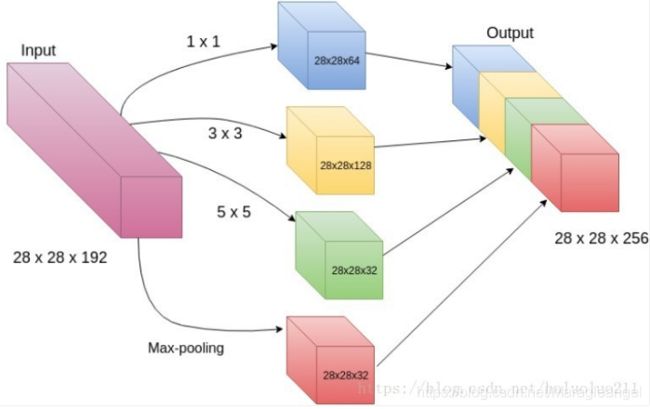
Inception-3a 输出计算:
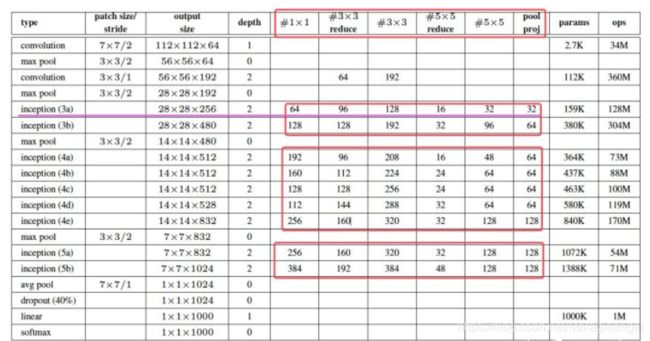
从 Table 1 中可以看到 Inception-3a 的输入是上一层 max pooling 的输出,即 Inception-3a 的输入大小为 28×28×192 (W×H×C)。那么 Inception-3a 的输出计算方式如下:
- # 1×1 的输出:此卷积使用的卷积核个数从 Table 1 中可知为 64,因此这一层的输出大小为 28×28×64 ①
- # 3×3 reduce 与 # 3×3 的输出: 通过 # 3×3 reduce 的操作输出为 28×28×96,将此输出作为 # 3×3 的输入,如果我们直接进行卷积操作就会发现,输出的结果为 26×26×128,与前面输出的结果就没有办法进行连接,因此需要在此处进行补零操作,即设置 padding=1 ,这样得到的输出结果就为 28×28×128 ②
- # 5×5 reduce 与 # 5×5 的输出:同上 # 5×5 reduce 的输出为 28×28×16,传入 # 5×5 ,此处依然需要进行补零操作 padding=2 ,从而得到输出 28×28×32 ③
- # pool proj 的输出:Max Pool为 3×3 ,因此要得到大小为 28×28 的输出就需要进行补零操作,此处 padding=1。Max Pool 的输入为 28×28×192 ,经过补零操作之后输出依然为 28×28×192,将其输入 Conv 1×1×32 (从 Table 1 可知卷积核个数为32个)从而得到的输出为 28×28×32 ④
最后将计算的结果: ① 28×28×64 ② 28×28×128 ③ 28×28×32 ④ 28×28×32
进行连接(即将通道数相加)可得到最终的输出结果:28×28×256
3a:[1×1 conv,128] 28×28×128×1×1×256
[3×3 conv,192] 28×28×192×3×3×256
[5×5 conv,192] 28×28×96×5×5×256 参数的总数为:387072 Total:854M ops
3b:[1×1 conv,64] 28×28×64×1×1×256
[3×3 conv,64] 28×28×64×1×1×256
[5×5 conv,128] 28×28×128×1×1×256
[1×1 conv,192] 28×28×192×3×3×64
[3×3 conv,96] 28×28×96×5×5×64
[5×5 conv,64] 28×28×64×1×1×256 参数的总数为:163328 Total:358M ops。
可以看到,虽然网络的复杂程度加大了,但是总的运算次数减小到之前的1/3。
另外,由于池化操作对于目前卷积网络的成功至关重要,因此建议在每个这样的阶段添加一个替代的并行池化路径应该也应该具有额外的有益效果。
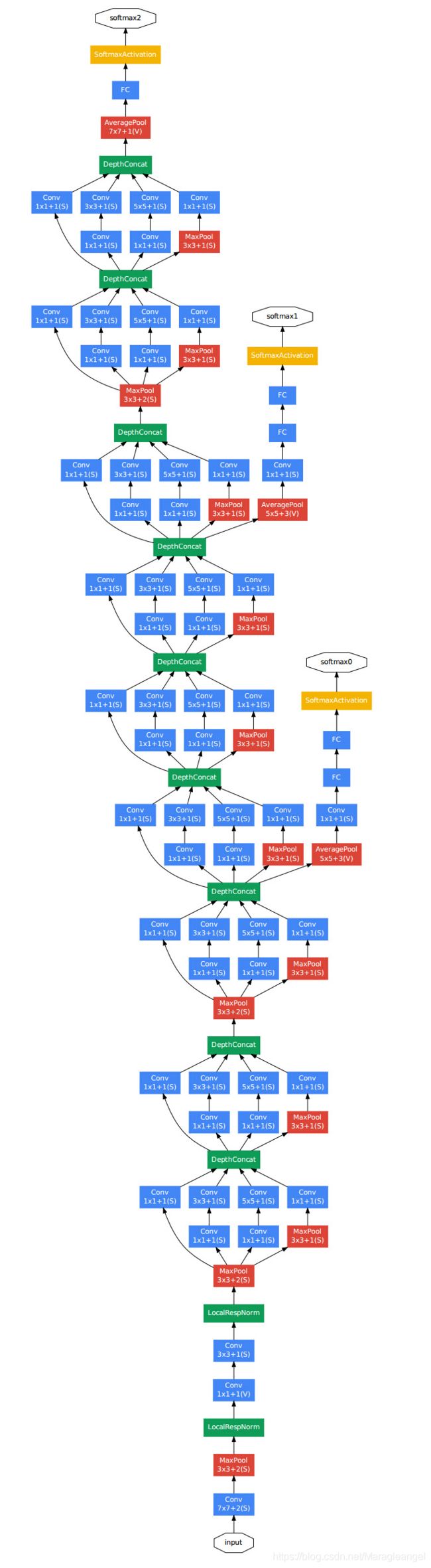
对上图做如下说明:
1 . 显然GoogLeNet采用了模块化的结构,方便增添和修改;
2 . 网络最后采用了average pooling来代替全连接层,想法来自NIN(network in network),事实证明可以将TOP1 accuracy提高0.6%。但是,实际在最后还是加了一个全连接层,主要是为了方便以后大家finetune;
3 . 虽然移除了全连接,但是网络中依然使用了Dropout ;
4 . 为了避免梯度消失,更浅网络的强大性能表明网络中部层产生的特征应该是非常有识别力的,所以网络额外增加了2个辅助的softmax用于向前传导梯度,放置在Inception (4a)和Inception (4b)模块的输出之上。在训练期间,它们的损失以折扣权重(辅助分类器损失的权重是0.3)加到网络的整个损失上。在推断时,这些辅助网络被丢弃。后面的控制实验表明辅助网络的影响相对较小(约0.5),只需要其中一个就能取得同样的效果。此外,实际测试的时候,这两个额外的softmax会被去掉。
包括辅助分类器在内的附加网络的具体结构如下:
- 一个平均滤波器大小5×5,步长为3的平均池化层,导致(4a)阶段的输出为4×4×512,(4d)的输出为4×4×528。
- 具有128个滤波器的1×1卷积,用于降维和修正线性激活。
- 一个全连接层,具有1024个单元和修正线性激活。
- 丢弃70%输出的丢弃层。
- 使用带有softmax损失的线性层作为分类器(作为主分类器预测同样的1000类,但在推断时移除)
图像采样
ILSVRC 2014 中的图像尺寸并不是都是正方形,正好适合输入 GooLeNet 模型中,对于图片进行相应的缩放操作是必要的。而论文中提到的裁剪的方式,实际是一种数据增强的方式。下面就具体分析下论文中是怎么操作的。
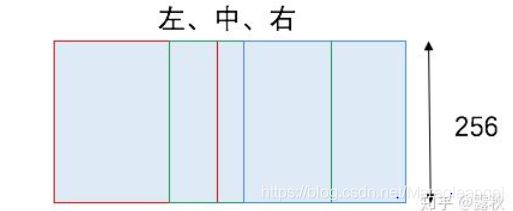
首先将一张图片的最短边缩放为 256、288、320 、352 四个尺寸,如一张 720×1024 的图片,通过上面的操作之后,短边 720 就变成了上面的四个值,相应的长边也进行了缩放,论文中提到缩放的比例在 4/3 与 3/4 之间。这样就得到了 4 张尺寸的图片。
然后在得到的缩放图片上,以左、中、右的方式截取方形区域,如果是人像则采取上、中、下的截取方式,这样就产生了3 个区域:
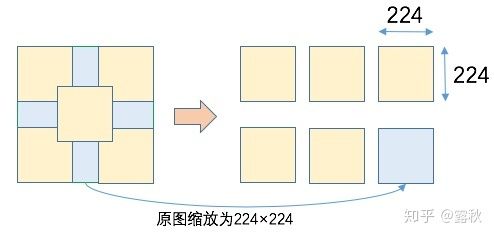
接着从截取的区域中,选择四个角和中心进行截取 224 大小的区域,最后把原图缩放为 224×224大小,这样就得到了 6 张图片:
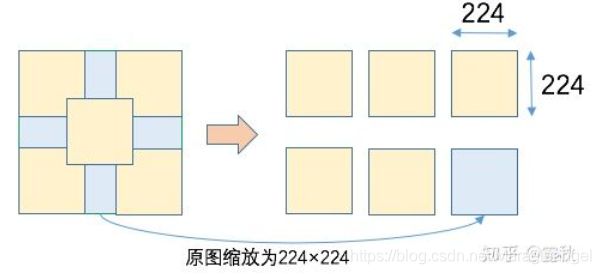
最后每张图再取一个镜像版本,这样就得到了 2 张图。
经过上面一系列操作之后得到的图片数量为 4(四个尺寸) × 3(左、中、右) × 6(4角 + 中心 + 原图缩放) × 2(镜像) = 144 张。
什么是稀疏性
Inception 就是为了解决在保留稀疏性的同时,又能利用密集矩阵的高计算性能。对其中的稀疏性产生了疑问,什么是稀疏性?最后看了一些资料才知道,其实稀疏性(sparsity)就是指局部连接(Local Connectivity),如下图:
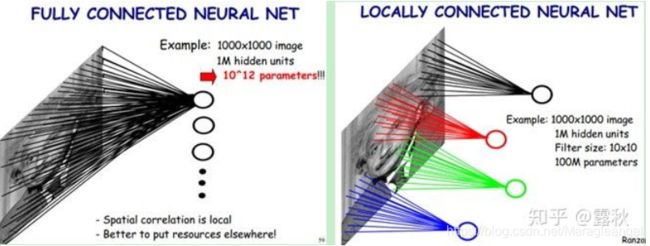
左边是全连接,而右边是局部连接,通过局部连接大大的减少参数的数量。
然后在通过参数共享进一步减少参数的数量:
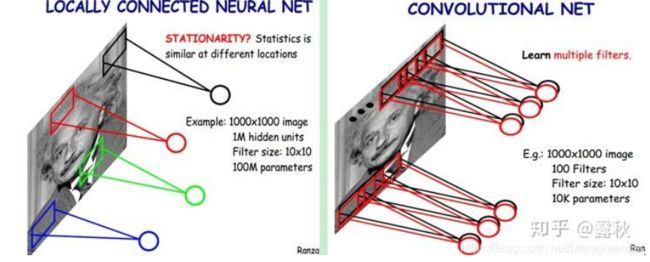
接下来看的论文
看到链接中说:论文中提到了这样一句话:max-pooling layers result in loss of accurate spatial information,作者也意识到了最大池化会导致某些精确的空间信息丢失,但是他在这里仅仅提到了,没有去深入思考,联想到了最近的一个新模型,CapsNet,神经网络提出者Hinton的新论文。其中的思想也很新颖,而且对CapsNet能否与迁移学习相联系有着比较大的兴趣,正在尝试着去研究。我接下来会看看ResNet,然后阅读CapsNet.