【总结】工业缺陷检测-机器视觉方法整理
万字长文细说工业缺陷检测 - 知乎
目录
一、问题
1.1 数据问题
1.2 应用场景要求
二、应对方案
三、基础架构
3.1 编码器 -- 特征提取阶段
3.2 解码器 -- 特征融合阶段
Feature Pyramid Networks--特征金字塔
1、无融合
2、自上而下单向融合的FPN
3、简单双向融合
4、复杂的双向融合
5、M2det中的SFAM
3.3 Attention -- 建立目标与其上下文之间的连接
(1) 通道注意力-- Channel attention
1、SENet -- CV领域的真神
2、ECANet -- 一维卷积替换SENet中的MLP
3、SKNet
(2) 空间域注意力方法 Spatial attention
1、自注意力:Self-Attention
2、非局部注意力:Non-local Attention(CVPR2018)
(3)混合域注意力方法
1、CBAM
2、DANet
3、CCNet
4、Residual Attention Network
四、训练过程
4.1 损失函数
4.2 数据预处理
五、常用的一些处理手段&定制特性:
一、问题
与自然场景相比,工业检测任务存在的特有问题:自动缺陷检测任务中存在三个主要挑战:
1.1 数据问题

1.2 应用场景要求
- 高精度
- 高效率
- 低成本
- 落地、绿色环保
可行性:
- 明显:缺陷清晰可见,肉眼容易辨别,同时也是对光学成像提出要求;
- 明确:缺陷标准定义明确,没有争议,是对需求进行筛选;
二、应对方案
- 界线难分(对比度低)、类间差距大、类内差距小:提升网络的特征提取能力
- 形态纹理位置不固定(多尺度):特征金字塔多级提取特征
- 不平衡、小样本:数据增强、无监督/半监督、迁移学习、损失函数优化
- 应用场景效率:轻量级模型、剪枝蒸馏、硬件加速
三、基础架构
编码器 -- 解码器结构 + 各种上下文信息融合
- FCN、U-net、PSPnet、deeplab、seg-net、Refinenet......
3.1 编码器 -- 特征提取阶段
从分类网络迁移过来,用作特征提取器,后续的网络负责从这些特征中,检测目标的位置和类别。
编码器往往是各种CNN模型的一个共享结构。
-
- AlexNet: https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
- VGG: https://arxiv.org/pdf/1409.1556.pdf
- Residual Network: https://arxiv.org/pdf/1512.03385.pdf
- Wide ResNet: https://arxiv.org/pdf/1605.07146.pdf
- FractalNet: https://arxiv.org/pdf/1605.07648.pdf
- ResNeXt: https://arxiv.org/pdf/1611.05431.pdf
- GoogleNet: https://arxiv.org/pdf/1409.4842.pdf
- Inception: https://arxiv.org/pdf/1602.07261.pdf
- DenseNet: https://arxiv.org/pdf/1608.06993.pdf
- SORT: https://arxiv.org/pdf/1703.06993.pdf
- Compact Bilinear: https://arxiv.org/pdf/1511.06062.pdf
- MobileNet(轻量级):轻量级网络-Mobilenet系列(v1,v2,v3) - 知乎
- Xception(轻量级):[论文笔记] Xception - 知乎
- ShuffleNet(轻量级):论文阅读笔记:ShuffleNet_loki2018的博客-CSDN博客_shufflenet
- SqueezeNet(轻量级):SqueezeNet详解 - 知乎
-
这个共享结构除了结构性的超参(总深度、总宽度)以外,反复使用了多种技巧,其中包括
- Residual(残差): 直接elementwise加法。
- Concat(特征拼接): 直接对特征深度作拼接。
- Bottleneck(特征压缩): 通过Conv(1,1)对稀疏的或者臃肿的特征进行压缩
- Grouping(分组): fc-softmax分类器从1个观察点把不同类靠空间球心角分离开,不同类放射状散开不符合高斯假设。分组改善了这一点。
- Fractal(分形模式): 结构复用,可能带来好处
- High-Order(高阶): 在非分组时,可能带来好处
- Asymmetric(非对称): Conv(1,3),Conv(1,5),Conv(1,7)属于非对称结构,这个技巧在OCR处理长宽非1:1的字体有用
- 各种形式的池化:Max Pooling(最大池化),Average Pooling(平均池化),Global Average Pooling(全局平均池化)
- Dilated/Atrous Convolution(空洞卷积):提供更大的感受野,获得更密集的数据
-
总结各个结构的特征:
- AlexNet/VGG: 普通
- VGG: 加深
- ResNet: 通过x+F(x)直接加法实现了Residual模块
- Wide ResNet: 加宽
- FractalNet: 结构复用,使用Concat
- ResNeXt: ResNet基础上对Conv(3,3)使用了分组,但是如果Conv(1,1)也分组甚至精度不降
- GoogleNet/Inception: 大量的非对称技巧
- DenseNet: 大量使用压缩
- SORT: 一个小trick使用elementwise x*F(x)实现高阶
- Compact Bilinear: 通过学习矩阵A实现x’Ay实现制造新的特征
- MobileNet(轻量级):深度可分离卷积
- Xception(轻量级): 深度可分离卷积
- ShuffleNet(轻量级):分组卷积
- SqueezeNet(轻量级): SE压缩激励块
图片分割设计的结构更关心单位像素点分类正确与否,因此编码器阶段后续有FCN、上下采样等设计思想。
3.2 解码器 -- 特征融合阶段
前言:为了能最多的检测出图像上的大小目标,图像算法有一下几种方法:
(1)图像金字塔:生成不同尺寸的图片,依次输入同一神经网络,得到对应的feature map,每个feature map分别进行预测,最后再整合预测结果。

(2)feature map:使用神经网络某一层输出的feature map进行预测,取最后网络一层的feature map做预测。【最初的分割网络:FCN】

(3)特征金字塔:使用不同层次的金字塔层feature map进行预测。【SSD采用这种多尺度特征融合方法】

(4)特征金字塔网络:对最底层的特征进行向上采样,并与该底层特征进行融合,得到高分辨率、强语义的特征(即加强了特征的提取)。
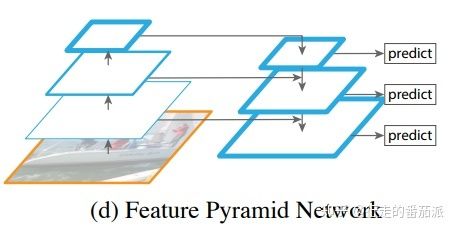
Feature Pyramid Networks--特征金字塔
思想:FPN一般将上一步生成的不同分辨率特征作为输入,输出经过融合后的特征。把高层的特征传下来,补充低层的语义,这样就可以获得高分辨率、强语义的特征,有利于小目标的检测。
FPN网络主要解决的问题是目标检测在处理多尺度变化问题的不足。

其中FPN自从被提出来,先后迭代了不少版本。大致迭代路径如下图:

1、无融合
无融合,又利用多尺度特征的典型代表就是2016年的鼎鼎有名的SSD,它直接利用不同stage的特征图分别负责不同scale大小物体的检测。

SSD首先尝试在多级金字塔特征上检测目标,它重用网络前馈中计算出的来自不同层级的多尺度特征图来预测不同尺寸的对象。但是,由于浅层特征图包含的语义信息不足,因此这种自下而上的途径在小目标上的准确性较低。
2、自上而下单向融合的FPN
当前物体检测模型的主流融合模式。如我们常见的Faster RCNN、Mask RCNN、Yolov3、RetinaNet、Cascade RCNN等,具体各个FPN的内部细节如下图。

3、简单双向融合
FPN自从提出来以后,均是只有从上向下的融合,PANet是第一个提出从下向上二次融合的模型,并且PANet就是在Faster/Master/Cascade RCNN中的FPN的基础上,简单增了从下而上的融合路径。看下图。

4、复杂的双向融合
PANet的提出证明了双向融合的有效性,而PANet的双向融合较为简单,因此不少文章在FPN的方向上更进一步,尝试了更复杂的双向融合,如ASFF、NAS-FPN和BiFPN。
4.1 ASFF
ASFF(论文:Learning Spatial Fusion for Single-Shot Object Detection)作者在YOLOV3的FPN的基础上,研究了每一个stage再次融合三个stage特征的效果。如下图。其中不同stage特征的融合,采用了注意力机制,这样就可以控制其他stage对本stage特征的贡献度。

4.2 Recursive-FPN
递归FPN:将传统FPN的融合后的输出,再输入给Backbone,进行二次循环,如下图。

4.3 NAS-FPN和BiFPN
NAS-FPN(基于搜索结构的FPN )和BiFPN,都是google出品,思路也一脉相承,都是在FPN中寻找一个有效的block,然后重复叠加,这样就可以弹性的控制FPN的大小。

其中BiFPN的具体细节如下图:

5、M2det中的SFAM
M2det中的SFAM,比较复杂,它是先把C3与C5两个stage的特征融合成一个与C3分辨率相同的特征图(下图中的FFM1模块),然后再在此特征图上叠加多个UNet(下图中的TUM模块),最后将每个UNet生成的多个分辨率中相同分辨率特征一起融合(下图中的SFAM模块),从而生成最终的P3、P4、P5、P6特征,以供检测头使用。具体如下图。

3.3 Attention -- 建立目标与其上下文之间的连接
CV任务中,最常用的注意力机制有空间域、通道域和混合域三种
- 【通道注意力、空间注意力、时间注意力和分支注意力】
- Attention论文和代码大全 - 知乎
通道注意力,它关注于选择重要的通道,而在深度特征图中,不同的通道往往表示不同的物体,所以它的含义是关注什么(物体),即what to attend。
同理,空间注意力对应 where to attend, 时间注意力对应 when to attend,分支注意力对应 which to attend。具体的注意力机制请参见论文。
(1) 通道注意力-- Channel attention
通道域注意力类似于给每个通道上的特征图都施加一个权重,来代表该通道与关键信息的相关度的话,这个权重越大,则表示相关度越高。在神经网络中,越高的维度特征图尺寸越小,通道数越多,通道就代表了整个图像的特征信息。如此多的通道信息,对于神经网络来说,要甄别筛选有用的通道信息是很难的,这时如果用一个通道注意力告诉该网络哪些是重要的,往往能起到很好的效果,这时CV领域做通道注意力往往比空间好的一个原因。代表的是SENet、SKNet、ECANet等。
1、SENet -- CV领域的真神

注意力机制主要分为三个部分:挤压(squeeze),激励(excitation),以及注意(scale )。
- 首先是 Squeeze 操作,从空间维度来进行特征压缩,将h*w*c的特征变成一个1*1*c的特征,得到向量某种程度上具有全域性的感受野,并且输出的通道数和输入的特征通道数相匹配,它表示在特征通道上响应的全域性分布。算法很简单,就是一个全局平均池化。
- 其次是 Excitation 操作,通过引入 w 参数来为每个特征通道生成权重,其中 w 就是一个多层感知器,是可学习的,中间经过一个降维,减少参数量。并通过一个 Sigmoid 函数获得 0~1 之间归一化的权重,完成显式地建模特征通道间的相关性。
- 最后是一个 Scale 的操作,将 Excitation 的输出的权重看做是经过选择后的每个特征通道的重要性,通过通道宽度相乘加权到先前的特征上,完成在通道维度上的对原始特征的重标定。
2、ECANet -- 一维卷积替换SENet中的MLP
要对SENet模块进行了一些改进,提出了一种不降维的局部跨信道交互策略(ECA模块)和自适应选择一维卷积核大小的方法
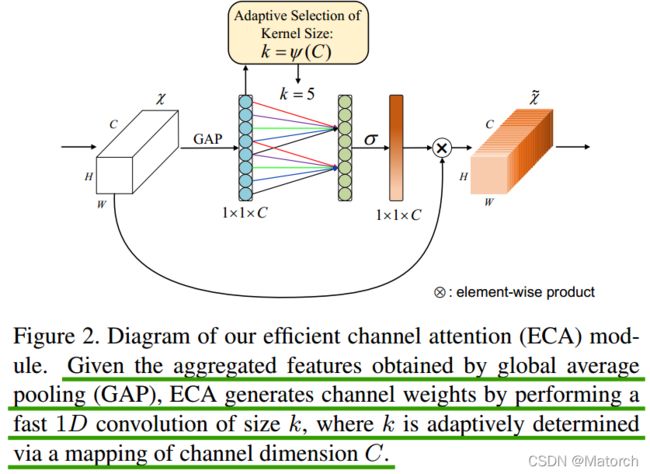
ECABlock创新点:
- 针对SEBlock的步骤(3),将MLP模块(FC->ReLU>FC->Sigmoid),转变为一维卷积的形式,有效减少了参数计算量(我们都知道在CNN网络中,往往连接层是参数量巨大的,因此将全连接层改为一维卷积的形式)
- 一维卷积自带的功效就是非全连接,每一次卷积过程只和部分通道的作用,即实现了适当的跨通道交互而不是像全连接层一样全通道交互。
3、SKNet
SKNet是基于SENet的改进,他的思路是在提高精度。而很多网络使用了各种Trick来降低计算量,比如SENet多层感知机间添加了降维。SKNet就是想如果不牺牲那么多计算量,能否精度提高一些呢?因此它设置了一组动态卷积选择来实现精度提升。
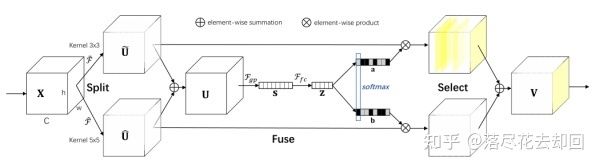
(2) 空间域注意力方法 Spatial attention
1、自注意力:Self-Attention
自注意力的结构下图所示,它是从NLP中借鉴过来的思想:

自注意力是基于特征图本身的关注而提取的注意力。对于卷积而言,卷积核的设置限制了感受野的大小,导致网络往往需要多层的堆叠才能关注到整个特征图。而自注意的优势就是它的关注是全局的,它能通过简单的查询与赋值就能获取到特征图的全局空间信息。
2、非局部注意力:Non-local Attention(CVPR2018)
Non-local Attention是研究self-attention在CV领域应用非常重要的文章。主要思想也很简单,CNN中的卷积单元每次只关注邻域kernel size 的区域,就算后期感受野越来越大,终究还是局部区域的运算,这样就忽略了全局其他片区(比如很远的像素)对当前区域的贡献。所以Non-local blocks 要做的是,捕获这种long-range 关系:对于2D图像,就是图像中任何像素对当前像素的关系权值;对于3D视频,就是所有帧中的所有像素,对当前帧的像素的关系权值。
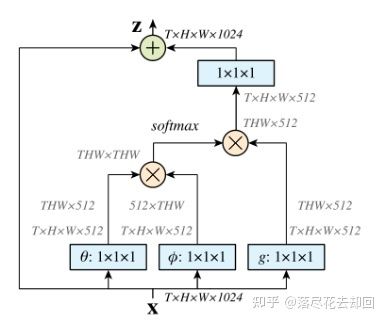
(3)混合域注意力方法
1、CBAM
CBAM也是基于SENet的改进论文中把 channel-wise attention 看成是教网络 Look ‘what’;而spatial attention 看成是教网络 Look ‘where’,所以它比 SE Module 的主要优势就多了后者。
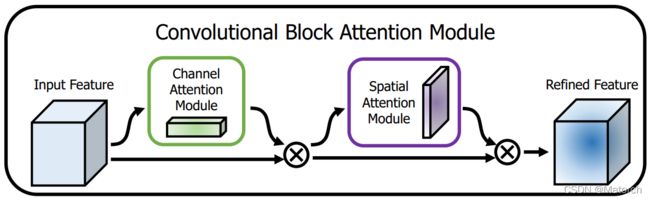
上图所示是CBAM的基本结构,前面是一个使用SENet的通道注意力模块,后面的空间注意力模块设计也参考了SENet,它将全局平均池化用在了通道上,因此作用后就得到了一个二维的空间注意力系数矩阵。值得注意的是,CBAM在空间与通道上同时做全局平均和全局最大的混合pooling,能够提取到更多的有效信息。
2、DANet
在CBAM 分别进行空间和通道self-attention的思想上,直接使用了non-local 的自相关矩阵Matmul 的形式进行运算,避免了CBAM 手工设计pooling,多层感知器等复杂操作。同时,把Self-attention的思想用在图像分割,可通过long-range上下文关系更好地做到精准分割。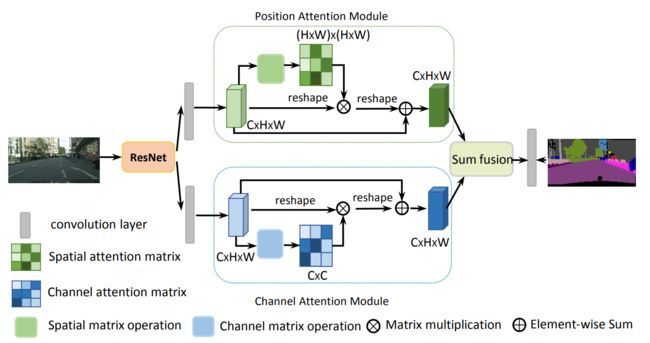
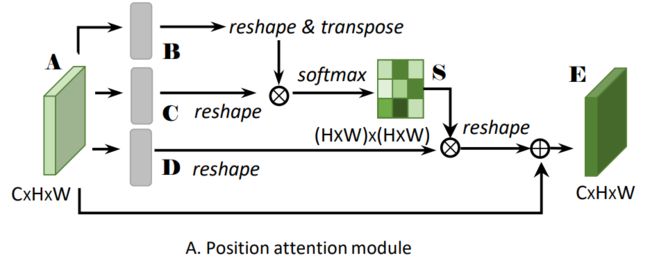
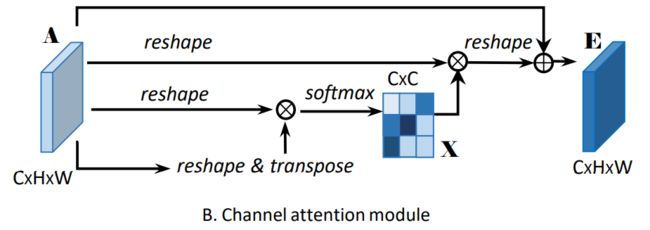
结构框架使用的是CBAM,使用了Position Attention Module 和 Channel Attention Module。两个模块使用的方法都是self-attention,只是作用的位置不同,一个是空间域的self-attention,一个是通道域的self-attention。
- Position Attention:通过所有位置处的特征的加权和来选择性地聚合每个位置的特征。无论距离如何,类似的特征都将彼此相关。
- Channel Attention:通过整合所有通道映射之间的相关特征来选择性地强调存在相互依赖的通道映射。
3、CCNet
亮点在于用了巧妙的方法减少了参数量。在DANet中,attention map计算的是所有像素与所有像素之间的相似性,空间复杂度为(HxW)x(HxW),而本文采用了criss-cross思想,只计算每个像素与其同行同列即十字上的像素的相似性,通过进行循环(两次相同操作),间接计算到每个像素与每个像素的相似性,将空间复杂度降为(HxW)x(H+W-1),以图为例为下:

整个网络的架构与DANet相同,只不过attention模块有所不同,在计算矩阵相乘时每个像素只抽取特征图中对应十字位置的像素进行点乘,计算相似度。
4、Residual Attention Network
软注意力基本的加掩码(mask)机制,但是不同的是,这种注意力机制的mask借鉴了残差网络的想法,不只根据当前网络层的信息加上mask,还把上一层的信息传递下来,这样就防止mask之后的信息量过少引起的网络层数不能堆叠很深的问题。
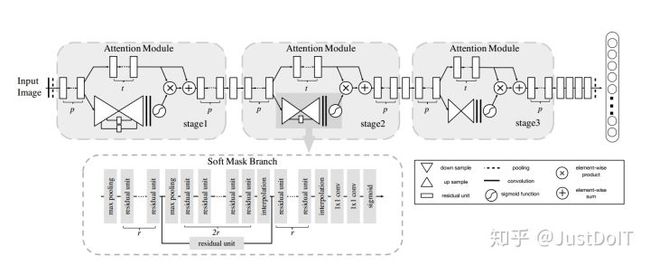
文提出的注意力mask,不仅仅只是对空间域或者通道域注意,这种mask可以看作是每一个特征元素(element)的权重。通过给每个特征元素都找到其对应的注意力权重,就可以同时形成了空间域和通道域的注意力机制。
四、训练过程
4.1 损失函数
深度学习中常用损失函数有:均方差损失、平均绝对误差损失、Huber损失、分位数损失、交叉熵损失、focal 损失和 dice损失等
图像分割最常用的损失函数为交叉熵,它在目标区域和非目标区域像素分布较为均衡的任务中,有较好的训练效果:
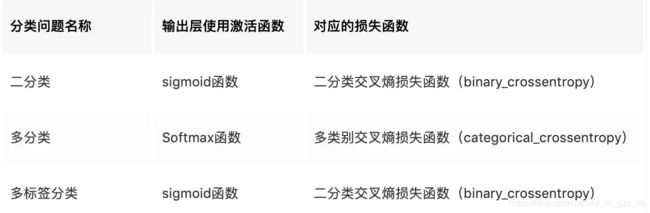
对于目标区域在整张图像中所占比例很小的时候,非目标区域会对交叉熵损失有较大的影响,此时可以考虑:
- Focal Loss:在数据类别不平衡的情况下,会让模型的注意力放在稀少的类别上。
- Dice Loss: 样本极度不均的情况。一般的情况下可能会对反向传播造成不利的影响,容易使训练变得不稳定。
4.2 数据预处理
1、数据生成
- 传统方法:图像融合,例如直接将缺陷裁剪下来到处贴,为了保证生成的逼真一点,还是需要一些融合的手段,例如泊松融合和边缘融合等。当然,有些场景,直接修改图片局部的灰度值也可以生成逼真的缺陷。
- 深度学习:GAN和VAE等生成模型,利用GAN可以直接从噪声生成数据,不过产生新的对网络训练有受益的信息比较有限。可以利用类似pix2pix的方案进行图片编辑。传统方法中的图片融合也可以利用GAN来做。
2、数据清洗
例如交叉验证。学术上也有一些噪声样本学习的方案。数据脏还比较好办,归根到底是数据标注的问题。随着训练迭代以及人工清洗,可以很好的改善这一情况。
五、常用的一些处理手段&定制特性:
- 多通道输入:适配多个光源的复杂场景
- 骨架任意切换:resnet、effecientnet
- 多个head:多任务,处理互斥类别
- attention辅助head: aspp、danet、senet、non_local
- refine module(Cascaded):结果精修,过滤虚检
- 不对等输出:256*256 > 8*8等,加速,牺牲定位精度,降低拟合难度
- attention机制:通道、空间、nonlocal,提升全局感知能力
- 通道剪枝:手动,network-slimming