图像分割(七):模型(U-Net、U-Net++)
文章目录
-
-
- 三、图像分割的模型
-
- 7.U-Net
- 8.U-Net++
-
三、图像分割的模型
7.U-Net
原论文
这是2015年,与FCN同一年提出的网络模型,U-Net主要解决的是医学领域的图像分割问题,由于其网络结构为一个U型,故名为U-Net。
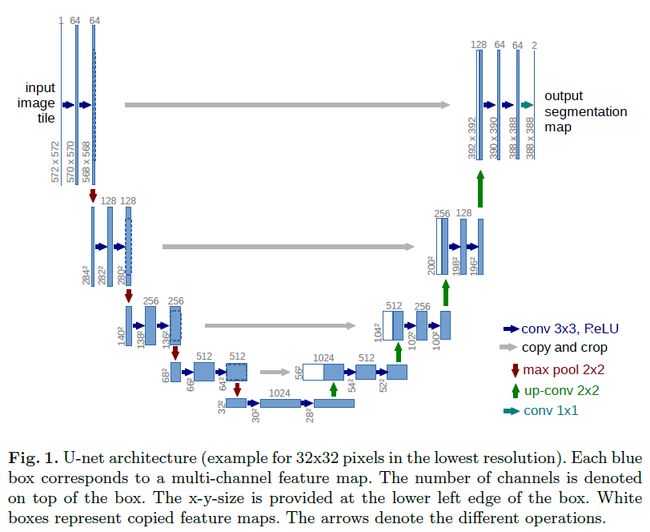
这是一个对称的生成模型,左边部分下采样进行特征提取,右边部分上采样,将浓缩的特征还原为图像。
从这个网络中可以看到,输入是一个572x572的,输出却是388x388的,输出比输入要小,这主要是因为医学领域分割的需要,这样做精度更高。
其模型继承FCN的思想改进而来,但是相较于FCN其有许多改进:
- U-Net是完全对称的,且对解码器进行了加卷积加深处理,FCN只是单纯的进行了上采样,decoder部分相对简单。
- 上采样的时候,使用了邻近插值,没有使用转置卷积。原因:转置卷积会使输出图像不均匀,出现象棋格子一样的黑白相间的效果(生成类模型使用该方法效果不好,尤其是卷积核为奇数的时候,转置卷积时,如果卷积核大小不能被步长整除,就会有棋盘格子的现象,如果步长和卷积核大小一致,就是完全均匀的)
- 跳跃连接使用了concat操作,将特征在channel维度拼接在一起,形成更厚的特征,将全局特征和局部特征进行结合,而不是简单的相加。
- 全程使用valid进行卷积(包括pooling),这样的话可以保证分割的结果都是基于没有缺失的上下文特征得到的,因此输入输出的图像尺寸不太一样。
这里有一些问题需要注意:
跳跃连接大小不一样如何拼接?
一般有3种思路:
- padding:将小图进行padding再拼接(这样直接填0进行padding没有什么用处)
- resize:将小图resize扩大或者大图resize缩小(这样位置信息改变了,像素会发生偏移,影响精度)
- crop:将大图裁小 ,这样会丢失一些局部的信息,不过每关系,因为它只是对全局的补充,为位置上矫正的辅助。
这里采用的是第3中crop的方法。
为什么输出会比输入更小?
因为这个模型是专为医学图像而生,有两点原因:
- 从卷积上来看,由于卷积核边缘信息提取不够,为了减少误差,提高可信度,所以直接把外层信息裁剪掉了
- Overlap-tile策略:像是下图,由于医学图像一般都很大,进行分割的时候不可能把原图输入网络,所以需要进行裁剪,把大图变成一张张的小图,而为了使图片拼接的部分分割得更加准确,从而采用了Overlap-tile策略,也就是有重叠的裁剪,具体可以看图中的解释,U-Net网络从输入到输出,需要overlap部分提供更多特征信息,将大图分割成小图的影响降到最低,最后标签也就是输出这么大,所以两者可以做损失,蓝色框就相当于这么大的一个卷积核。

损失:

使用交叉熵损失,但是作者提出了weighted loss,也就是赋予相互接触的两个细胞之间的background标签更高的权重,从而对边界像素有更好的学习效果,使得相同类别且互相接触的细胞得以分开。
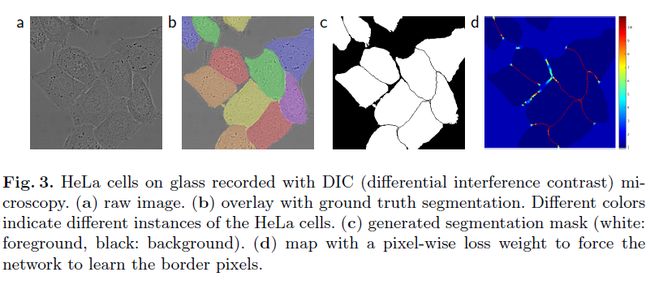
为什么说它很适合医学领域分割?
- 因为医学图像的边界模糊、梯度复杂,需要较多的高分辨率信息,用于精准分割。
- 人体内部结构相对固定,分割目标在人体图像中的分布很具有规律,语义简单明确,低分辨率信息能够提供这一信息,用于目标物体的识别。
- 医学图像数据相对较少,而U-Net模型较小,参数量少,不容易过拟合。
- 医学图像具有多模态的性质,这个模型结构可以较好的提取不同模态的特征。
简而言之,因为医学图像的特殊性,既需要高层次特征,也需要低层次特征。
归根结底还是因为U型结构与多次的跳跃连接 concat(同一stage尺度上的)。
UNet分割很精准,对细节很友好,可以看到,由于进行了多尺度融合,结合了低分辨率信息(提供物体类别识别依据)和高分辨率信息(提供精准分割定位依据),因而非常适用于医学图像的分割:

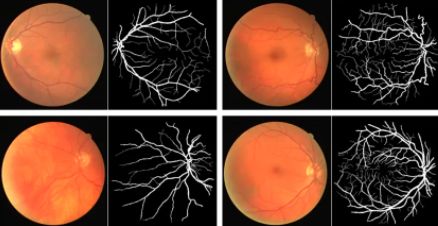
而且它还可以应用于其他自然图片分割,比如车辆分割、卫星影像分割等,效果也比较好。
相关代码:
Pytorch
TensorFlow
8.U-Net++
原论文
这是一个2018年提出的网络,是U-Net的一个强化版本,因此叫U-Net++。
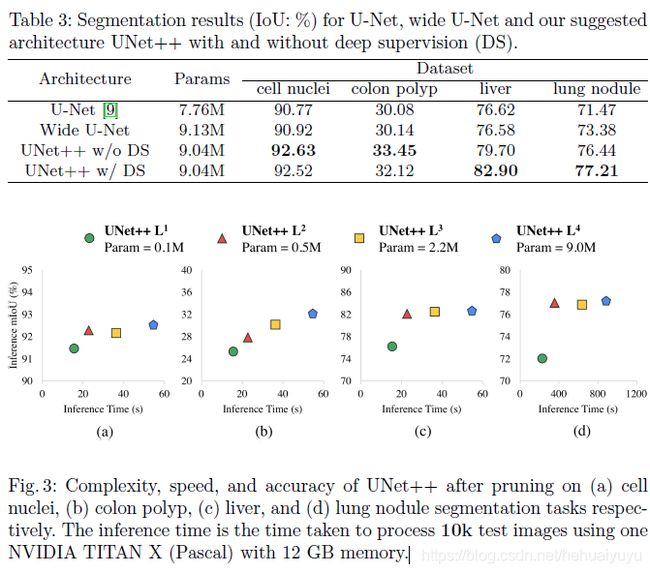
也是针对生物医学图像设计得模型,论文中做了四个分割任务的试验:
- 胸部低剂量CT扫描中的结节分割
- 显微镜图像中的细胞核分割
- 腹部CT扫描中的肝脏分割
- 结肠镜检查中的息肉分割
其相对U-Net改进之处主要为:
- 网络结合了类DenseNet结构,密集的跳跃连接提高了梯度流动性。
- 将空心结构填满,连接了编码器和解码器特征图之间的语义鸿沟。
- 使用了深度监督,因而可以剪枝。
它的网络结构是这样的:

那么我们来看一下为什么要这么设计。
参考:https://zhuanlan.zhihu.com/p/44958351
首先看一下U-Net的拓扑结构:
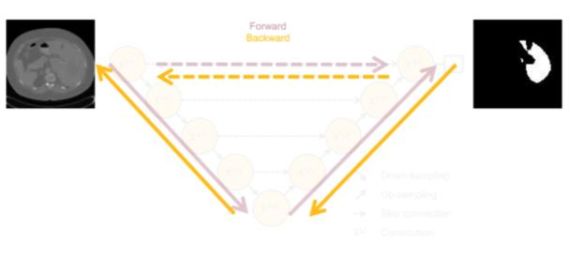
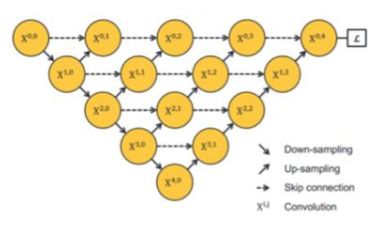
有一个问题是,网络要多深才合适,为什么这里给了四层上采样与下采样?
这其实是练丹练出来的,经验所得,作者觉得刚好够用而已 。
但是实际上卷积越多,不一定越好,因为越深像素偏移就越大,尤其是小物体的时候。
因为浅层特征更关注局部信息,深层特征更关注全局信息,感受野更大,U-net四层返回,就抓取的深层特征,而不是浅层特征,但实际上深层特征与浅层特征都很重要,有时候可能两三层就够了。
于是有了这样的结构:
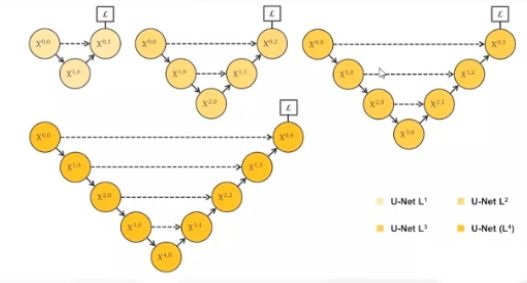
这里分成4个网络,求4个损失,分别对应不同的需求,但训练几个网络很麻烦,而且我希望数如图像能够自适应的匹配到对应层,哪一层效果好,就输入哪一个。
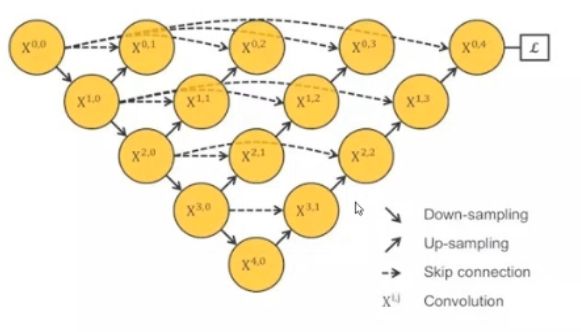
所以4个网络集合到一起,能够适应小面积和大面积分割任务,能学习不同深度的特征,只需要训练一个特征提取器就行了。
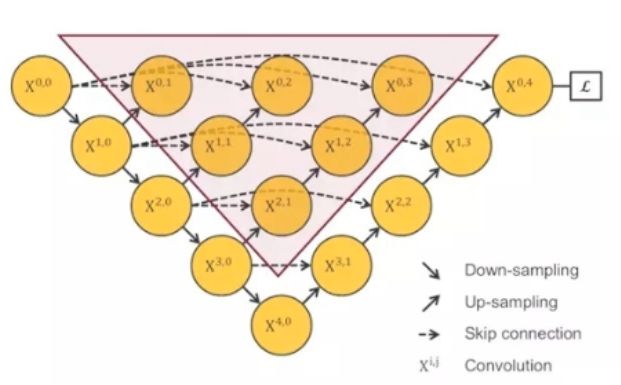
但是这么做又有问题,这样中间部分无法反向传播,训练不到,实际上就起不到作用。
所以把结构改成这个样子:
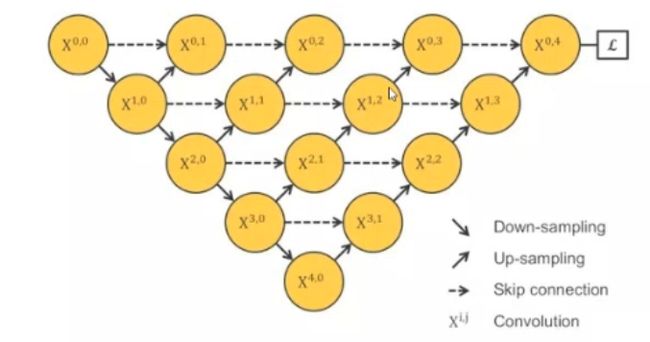
这样直接连起来,是可以做反向传播了,但是又没了跳跃连接【跳跃连接:把浅层(局部)信息与深层(全局)信息叠加起来,能让位置信息损失变得比较小,在开始卷积的时候位置信息偏移较小,越到后面越不准,于是添加浅层信息补充一下,有助于还原下采样带来的信息损失,跟残差有点类似】,变成了一系列的短连接。
于是进一步改进:
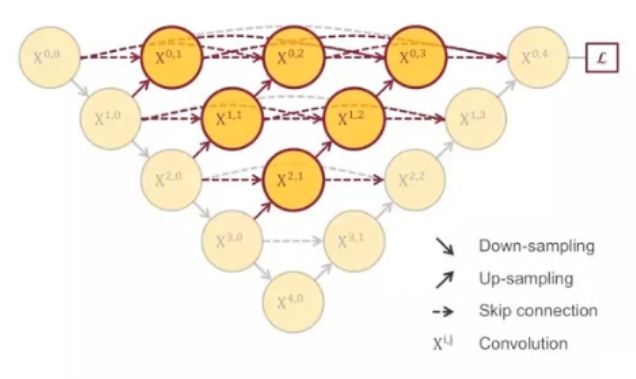
进一步把长短连接都加上,就变成了UNet++的结构。
它把空心的UNet填满了,水平层每一点都有连接,类似DenseNet,能抓取不同层次的特征,通过特征叠加整合到一起,因为不同大小的感受野对大小不同的目标敏感程度不一样,浅层的对小目标更敏感,深层对大目标更敏感,这样可以整合2者的优点。而且因为网络太深了,一次次下采样会不断丢失信息(大物体边缘信息和小物体本身),所以用感受野小的补充一下,让位置信息更准确。
在做损失的时候,强行加了几个梯度,因为只用最后的输出做损失,中间就没法反向,训练不到,于是就会在 X 0 , 1 X^{0,1} X0,1、 X 0 , 2 X^{0,2} X0,2、 X 0 , 3 X^{0,3} X0,3、 X 0 , 4 X^{0,4} X0,4,这四个地方做损失,加起来优化(也可以选择性的加权重),这样会有一个牵制,既考虑深层信息也考虑浅层信息。
但最上面一层直接做损失不太好的,因为可能会用一些relu之类的激活函数,但是做损失一般是个0、1之类的概率。
所以使用了深监督,在做损失之前再加一个1x1卷积,可以用一个sigmoid之类的激活,让输出和标签在同一个范围内,并且还有再提取一次特征,对通道进行改变等作用。

而且由于这种结构,它可以被剪枝。
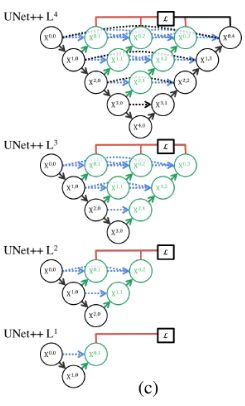
在深监督的过程中,每个子网络的输出(第一个水平层,除了第一个输入)都其实已经是图像的分割结果,如果前面已经足够好,就不需要再往后走了。
这里的剪枝只在测试的时候剪枝,训练的时候不剪枝,测试的时候只会前向而没有后向,所以没影响,而训练的时候后向的时候几个损失是相互促进的,所以有影响,不能剪掉。
看被测试的数据来剪枝,比如说我用图片测试,物体小,前面两层效果好,后面就剪掉不要了。
这就像是ResNet为什么会有152层的一样,它解决一个网络退化问题,让它成为一个恒等映射,虽然许多时候用不到这么深,但是它能够解决简单问题(可能随机学了几十层,剩下的就不要了),也能解决困难问题。
于是模型会有两种操作模式:
Accurate mode(精确模式):对所有分割分支的输出求平均值。
Fast mode(快速模式):从其中的所有的分支输出选择一个作为输出,其选择决定了模型修剪的程度和速度增益。
Loss:
使用了一个BCE和Dice Coefficient结合的损失,应用到每一个不同层次的输出:
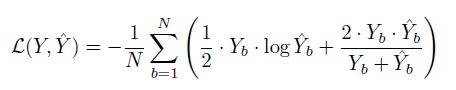
其中 Y ^ b \widehat{Y}_b Y b 是预测概率, Y b Y_b Yb是真实数据,N为Batch Size。
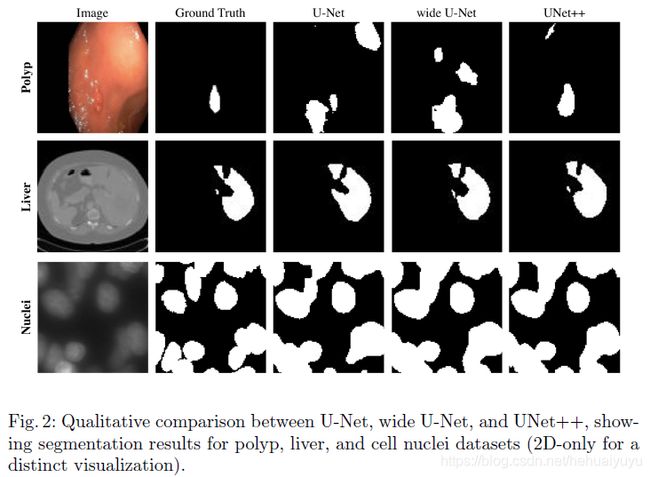
可以简单看一下效果对比: