经典语义分割网络总结之FCN、U-Net、DeepLab系列、PSPNet、BiseNet系列和ESPNet系列
FCN
论文链接:Fully Convolutional Networks for Semantic Segmentation
全卷机神经网络(FCN,Fully Convolutional Network)是第一次将端到端的卷积网络推广到了语义分割任务当中。
CNN做图像分类甚至做目标检测的效果已经被证明并广泛应用,图像语义分割本质上也可以认为是稠密的目标识别(需要预测每个像素点的类别)。
对于一般的分类CNN网络,如VGG和Resnet,都会在网络的最后加入一些全连接层,经过softmax后就可以获得类别概率信息。但是这个概率信息是1维的,即只能标识整个图片的类别,不能标识每个像素点的类别,所以这种全连接方法不适用于图像分割。
网络结构
FCN32s
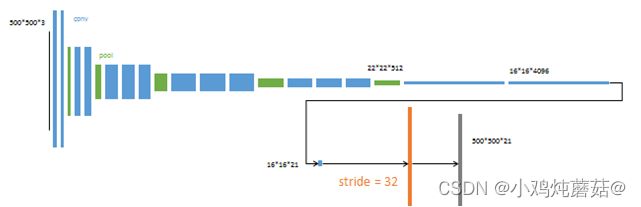
FCN16s
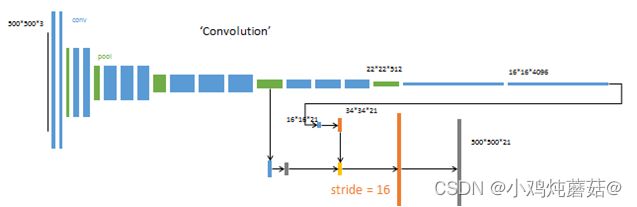
FCN8s

特点
分类使用的网络通常会在最后连接几层全连接层,它会将原来二维的矩阵(图片)压扁成一维的,从而丢失了空间信息,最后训练输出一个标量,这就是我们的分类标签。
而图像语义分割的输出需要是个分割图,且不论尺寸大小,但是至少是二维的。所以,我们需要丢弃全连接层,换上全卷积层,而这就是全卷积网络了。
FCN可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷积层的feature map进行上采样, 使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测, 同时保留了原始输入图像中的空间信息, 最后在上采样的特征图上进行逐像素分类(最后逐个像素计算softmax分类的损失, 相当于每一个像素对应一个训练样本)。
缺点:
- 分割的结果不够精细。进行8倍上采样虽然比32倍的效果好了很多,但是上采样的结果还是比较模糊和平滑,对图像中的细节不敏感。
- 因为模型是基于CNN改进而来的,即便使用卷积替换全连接,但是依旧是独立像素进行分类,没有充分的考虑像素与像素之间的关系,忽略了在通常的基于图像分类的分割方法中使用的空间规整(spatial regularization)步骤,缺乏空间一致性。
全卷积神经网络主要使用了3种技术:
1、卷积化:将普通的分类网络,比如VGG16,ResNet50/101等网络丢弃全连接层,换上对应的卷积层即可。因此这种全卷积形式的网络可以适应任意尺寸的输入(没有全连接层,全连接的结构是固定的)。
2、反卷积:反卷积(Deconvolution)也叫转置卷积(Transposed Convolution)。FCN作者在论文中讨论了三种上采样(upsample)方法,最后选用的是反卷积的方法(FCN作者称其为后卷积)使得图像实现end to end。
3、跳跃结构:这是特征融合的一种方式,未加入 跳跃结构 的模型是特别粗糙的,因为特征图直接扩大了 32 倍,所以论文中有一个改进,就是利用跳跃结构将网络中间的输入联合起来,即逐点相加,再进行反卷积,这样能够依赖更多的信息,将深层的信息与浅层的信息相结合,这样可以提高模型分割的准确性。
U-Net
论文链接:U-Net: Convolutional Networks for Biomedical Image Segmentation
深度网络训练之中需要大量的有标样本,Unet作者提供了一种新的训练方法,可以更有效的运用相应的有标样本,是模型在少量的训练图片中也可以进行精确的分割。这在生物医学领域具有很大的作用。
网络结构
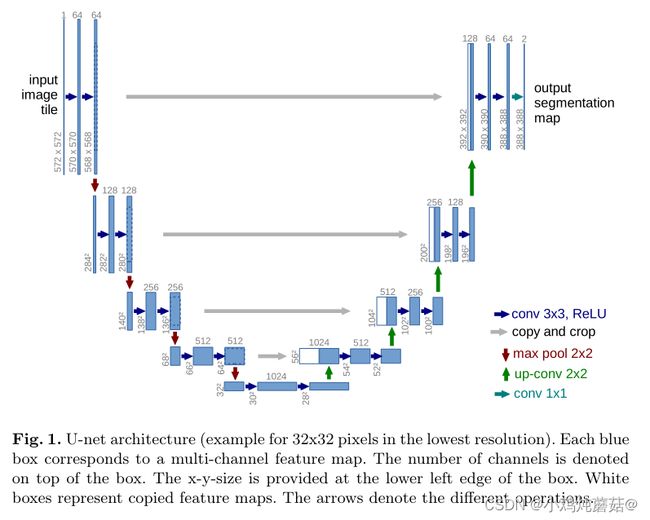
Unet网络结构整体呈现U字形,是一种编码器-解码器的结构。
编码阶段仍然是利用传统卷积神经网络的卷积池化组件,其中经过一次下采样之后,channels变为原来的2倍。
解码阶段由2 * 2的反卷积,反卷机的输出通道为原来通道数的一半,再与原来的feature map(裁剪之后)串联,得到和原来一样多的通道数的feature map,再经过2个尺寸为3 * 3的卷积和ReLU的作用。裁剪特征图是必要的,因为在卷积的过程中会有边界像素的丢失。在最后一层通过卷积核大小为1 * 1的卷积作用得到想要的目标种类。
在Unet中一共有23个卷积层。但是这个网络需要谨慎的选择输入图片的尺寸,以保证所有的Max Pooling操作作用于长宽为偶数的feature map。
特点
1、编码器-解码器结构。
2、有效的提升了使用少量数据集进行训练检测的效果。
3、Overlap-tile strategy:由于网络没有全连接层,并且只使用每个卷积的有效部分,所以只有分割图像完全包含在输入图像中可以获得完整的上下文像素。而这个策略允许通过重叠区块无缝分割任意大的图像,为了预测图像边界区域中的像素,通过镜像的输入图像来外推丢失的上下文。这种平铺策略对于将网络应用于大图像很重要,否则分辨率将受到GPU内存的限制。
4、数据增强:虽然数据增强在论文中提及较少,但是数据增强对于网络来讲非常重要,并且文中提到了非常实用的数据增强的方法。
DeepLab
DeepLabV1:Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs
DeepLabV2:
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
DeepLabV3:
Rethinking Atrous Convolution for Semantic Image Segmentation
DeepLabV3+:
Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
网络结构
DeepLabV1:
1、空洞卷积:为了获得较大的感受野,常用的方法就是通过池化或者带步长的卷积来降低特征图的分辨率,但是特征图的分辨率降低会导致信息丢失。为了防止信息丢失,需要一种不降低特征图分辨率获得大的感受野的方法,使用空洞卷积来增加感受野。
2、对于CNN的空间不变性导致的语义分割边缘分割不准确的问题,使用条件随机场(CRF:Conditional Random Field)解决了边界分割不精确的问题。
DeepLabV2:
相较于DeepLabV1,DeepLabV2提出了多孔空间金字塔池化(ASPP),并且以ResNet作为backbone。
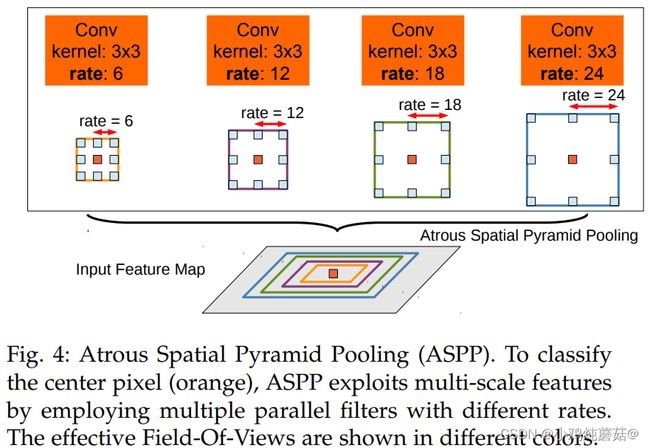
ASPP模块如图所示,卷积核采用不同的空洞大小,来增加感受野的同时,能够捕获不同大小的目标的语义信息。
并且,DeepLabV2使用了学习率多项式衰减策略,其中power=0.9
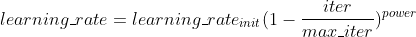
DeepLabV3:
主要还是解决分辨率不断降低和多尺度物体的问题。
连续的池化操作还有卷积stride使得特征分辨率逐渐降低。这种局部图像转换的不变性会阻碍密集预测任务(需要详细的空间信息)。因此作者提倡使用空洞卷积解决这个问题。

- 与DeepLabV2相比,DeepLabV3不再需要CRF后处理过程
- 受到SPP的启发,提出了ASPP模块,采用了四个并行的不同的扩张率的空洞卷积对特征图进行处理,并且加入了全局平均池化来捕获全局上下文信息,并且在ASPP模块中加入了BN层
ASPP源码如下:
class ASPPConv(nn.Sequential):
def __init__(self, in_channels: int, out_channels: int, dilation: int) -> None:
modules = [
nn.Conv2d(in_channels, out_channels, 3, padding=dilation, dilation=dilation, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
]
super().__init__(*modules)
class ASPPPooling(nn.Sequential):
def __init__(self, in_channels: int, out_channels: int) -> None:
super().__init__(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
size = x.shape[-2:]
for mod in self:
x = mod(x)
return F.interpolate(x, size=size, mode="bilinear", align_corners=False)
class ASPP(nn.Module):
def __init__(self, in_channels: int, atrous_rates: List[int], out_channels: int = 256) -> None:
super().__init__()
modules = []
modules.append(
nn.Sequential(nn.Conv2d(in_channels, out_channels, 1, bias=False), nn.BatchNorm2d(out_channels), nn.ReLU())
)
rates = tuple(atrous_rates)
for rate in rates:
modules.append(ASPPConv(in_channels, out_channels, rate))
modules.append(ASPPPooling(in_channels, out_channels))
self.convs = nn.ModuleList(modules)
self.project = nn.Sequential(
nn.Conv2d(len(self.convs) * out_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
nn.Dropout(0.5),
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
_res = []
for conv in self.convs:
_res.append(conv(x))
res = torch.cat(_res, dim=1)
return self.project(res)DeepLabV3+:
DeepLabV3+在DeepLabV3的基础上添加了一个简单有效的解码器模块来修正分割结果,对目标边界的修正效果更好。DeepLabV3+将深度可分离卷积应用到ASPP模块和解码器模块来提升运算速度。

在上图展示的DeepLabV3+网络中,Encoder为DeepLabV3,在这基础上加入了解码器模块来细化分割结果。
PSPNet
本文提出的金字塔池化模块( pyramid pooling module)能够聚合不同区域的上下文信息,从而提高获取全局信息的能力。实验表明这样的先验表示(即指代PSP这个结构)是有效的,在多个数据集上展现了优良的效果。
网络结构

PSPNet的整体架构
- 基础层经过预训练的模型(ResNet101)和空洞卷积策略提取feature map,提取后的feature map是输入的1/8大小。
- feature map经过Pyramid Pooling Module得到融合的带有整体信息的feature,在上采样与池化前的feature map相concat。
- 最后过一个卷积层得到最终输出。
本论文提出了一个具有层次全局优先级,包含不同子区域之间的不同尺度的信息,称之为pyramid pooling module。
在一般CNN中感受野可以粗略的认为是使用上下文信息的大小,论文指出在许多网络中没有充分的获取全局信息,所以效果不好。要解决这一问题,常用的方法是:
- 用全局平均池化处理。但这在某些数据集上,可能会失去空间关系并导致模糊。
- 由金字塔池化产生不同层次的特征最后被平滑的连接成一个FC层做分类。这样可以去除CNN固定大小的图像分类约束,减少不同区域之间的信息损失。
该模块融合了4种不同金字塔尺度的特征,第一行红色是最粗糙的特征–全局池化生成单个输出,后面三行是不同尺度的池化特征。为了保证全局特征的权重,如果金字塔共有N个级别,则在每个级别后使用1 × 1的卷积将对于级别通道降为原本的1/N。再通过双线性插值将特征图上采样到未池化前的大小,最终concat到一起。
金字塔等级的池化核大小是可以设定的,这与送到金字塔的输入有关。论文中使用的4个等级,核大小分别为1 × 1 , 2 × 2 , 3 × 3 , 6 × 6 。
特点
- 提出了能够获取全局场景的深度网络PSPNet,能够融合多尺度特征,并且将局部和全局信息融合到一起。
- 提出了一个适度监督损失的优化策略,在多个数据集上表现优异。
- 构建了一个实用的系统,用于场景解析和语义分割,并包含了实施细节
BiseNet
BiseNet:BiSeNet: Bilateral Segmentation Network for Real-time Semantic Segmentation
BiseNetV2:BiSeNet V2: Bilateral Network with Guided Aggregation for Real-time Semantic Segmentation
网络结构
BiseNet
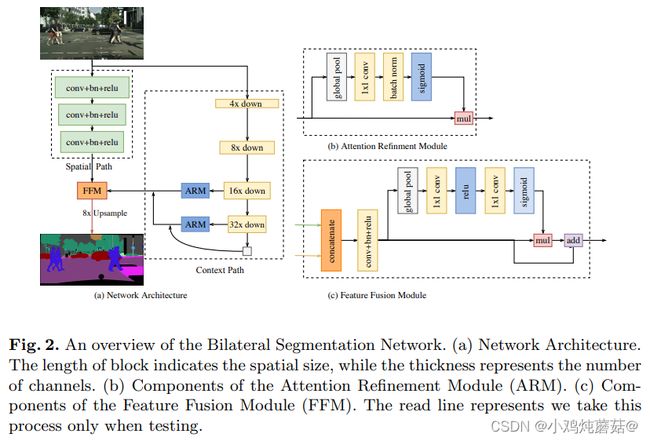
网络中Attention Refinement Module 和 Feature Fusion Module模块都引入了注意力机制。需要注意图 (a) 中右下角的白色方框表示global average pooling层。
Attention Refinement Module
通过注意力机制自适应选择合适的特征,代码如下:
class AttentionRefinementModule(nn.Module):
def __init__(self, in_chan, out_chan, *args, **kwargs):
super(AttentionRefinementModule, self).__init__()
self.conv = ConvBNReLU(in_chan, out_chan, ks=3, stride=1, padding=1)
self.conv_atten = nn.Conv2d(out_chan, out_chan, kernel_size= 1, bias=False)
self.bn_atten = BatchNorm2d(out_chan)
# self.sigmoid_atten = nn.Sigmoid()
self.init_weight()
def forward(self, x):
feat = self.conv(x)
atten = torch.mean(feat, dim=(2, 3), keepdim=True)
atten = self.conv_atten(atten)
atten = self.bn_atten(atten)
# atten = self.sigmoid_atten(atten)
atten = atten.sigmoid()
out = torch.mul(feat, atten)
return outFeature Fusion Module
detail分支和context分支的输出经过特征融合模块进行融合,其中用到了注意力机制。作者认为空间路径可以编码丰富的空间信息和细节信息,而上下文路径提供大的接受场,主要对上下文信息进行编码,也就是说空间路径的输出是低水平而上下文路径的输出是高水平的,2条路径的特征在特征表示的层次上是不同的。因此提出了一个特征融合模块用于融合这些特征。作者仿照SENet(通道注意力机制对特征进行重新加权),即特征的选择和组合。
class FeatureFusionModule(nn.Module):
def __init__(self, in_chan, out_chan, *args, **kwargs):
super(FeatureFusionModule, self).__init__()
self.convblk = ConvBNReLU(in_chan, out_chan, ks=1, stride=1, padding=0)
## use conv-bn instead of 2 layer mlp, so that tensorrt 7.2.3.4 can work for fp16
self.conv = nn.Conv2d(out_chan,
out_chan,
kernel_size = 1,
stride = 1,
padding = 0,
bias = False)
self.bn = nn.BatchNorm2d(out_chan)
self.init_weight()
def forward(self, fsp, fcp):
fcat = torch.cat([fsp, fcp], dim=1)
feat = self.convblk(fcat)
atten = torch.mean(feat, dim=(2, 3), keepdim=True)
atten = self.conv(atten)
atten = self.bn(atten)
atten = atten.sigmoid()
feat_atten = torch.mul(feat, atten)
feat_out = feat_atten + feat
return feat_outBiseNetV2
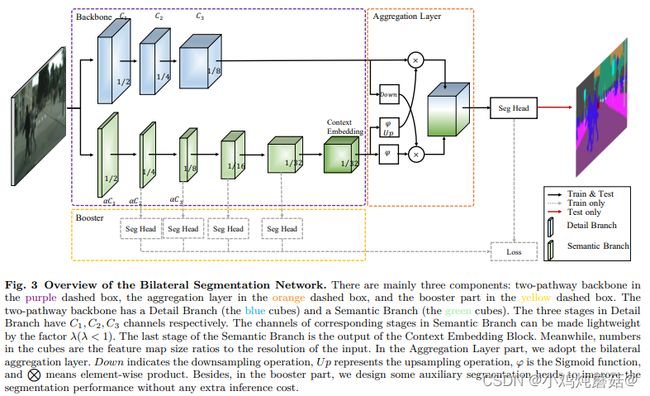
Detail Branch: Detail分支 的任务是保存低级特征的空间细节信息,所以该分支的设计理念就是通道多,层数少,下采样比率低。为了防止模型速度降低,没有采用residual connection。
Semantic Branch:Semantic分支 的目标是捕获高级的语义信息,为了得到较大的感受野和加快计算效率,所示他的设计理念是通道少,层数多,下采样比率大(增加感受野)。该分支可替换为其他的backbone。
Guided Aggregation Layer :Detail分支 和 Semantic分支 的特征图通过 Guided Aggregation Layer 进行融合,利用 Semantic分支得到的上下文信息来指导 Detail分支 的特征图输出,并且左右2个分支特征图尺度不同,这样可以得到多尺度信息。
特点
语义分割既需要丰富的空间信息,又需要相当大的感受野。然而,当前方法通常会牺牲空间分辨率来实现实时推理速度,从而导致性能低下。BiSeNet可以解决这个难题,将空间信息保存和感受野提供的功能解耦为两条路径:
- 设计一个小跨步的 空间路径 (SP) 来保存空间信息并生成高分辨率的特征。采用快速下采样策略的 上下文路径 (CP) 来获得足够的感受野。设计这两个组件是为了分别针对空间信息的丢失和感受野的减小。
- 为了在不损失速度的情况下获得更好的精度,我们还研究了两个组件的融合和最终预测的优化,并分别提出了特征融合模块(FFM)和注意细化模块(ARM)。
BiSeNetV2提出将这些空间细节和分类语义分开处理,以实现实时语义分割的高精度和高效率。该网络架构包括:
(1)一种高效的双路径结构,两条路径分别处理空间细节和分类语义;
(2)一个细节分支,具有宽的通道和浅层来捕获低层次的细节并生成高分辨率的特征表示;
(3)一个语义分支,设计了一种新的基于深度卷积的轻量级网络,以增强接受域和捕获丰富的上下文语义信息。由于减少了信道容量和快速下采样策略,语义分支是轻量级的。
(4)此外,我们设计了一个引导聚合层来增强相互连接和融合这两种类型的特征表示。此外,还设计了一种强化训练策略来改进分割效果姿态架构的性能优于一些最先进的实时语义分割方法。
ESPNet and ESPNetV2
ESPNet:ESPNet: Efficient Spatial Pyramid of Dilated Convolutions for Semantic Segmentation
ESPNetV2:ESPNetv2: A Light-weight, Power Efficient, and General Purpose Convolutional Neural Network
网络结构
ESPNet

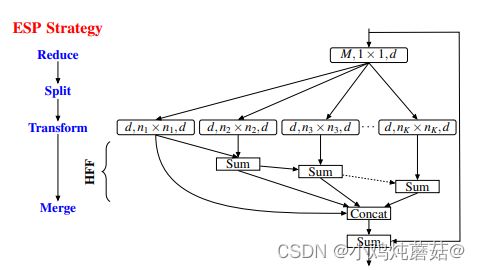
ESPNet采用的是非常典型的Encoder-Decoder结构,解码时加入了原图片,增加了细节,这里的特征图上采样使用了逆卷积,而非常用的插值。
ESPNetV1提出了ESP(Efficient spatial pyramid)模块,利用point-wise卷积和空洞卷积空间金字塔(Spatial pyramid of dilated convolutions)模块将标准的卷积拆分,并且引入HFF( hierarchical feature fusion)来移除空洞卷积的网格效应,能够在降低参数的同时保持很好的性能。
ESP(Efficient spatial pyramid)模块:对于输入通道为M的特征图,首先使用1x1的卷积压缩其通道至d,然后送入空洞卷积空间金字塔模块得到不同感受野的特征图,接着利用HFF将多个特征图融合,同时添加Skip connection引入多尺度信息,增加表达能力。
ESPNetV2
ESPNetV2是从ESPNetV1改进来的,利用深度扩展可分卷积和群点卷积的优点,文章提出了一种新的单元EESP,即深度扩展可分卷积的高效空间金字塔(Extremely Efficient Spatial Pyramid),它是专门为边缘器件设计的。
在 ESPNetV2中主要针对v1中的ESP模块进行改进,引入分组卷积从而衍生除了两个版本的EESP单元。
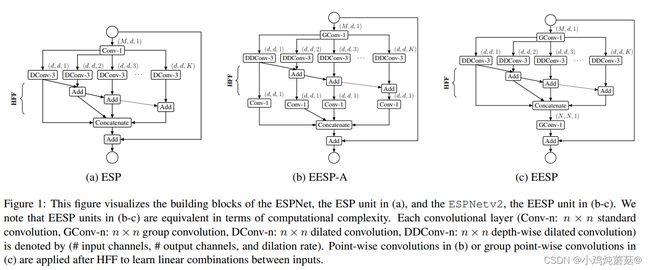
EESP-A:该模块为了使ESP模块的计算效率更高,我们首先用分组逐点卷积代替逐点卷积。然后,我们用高效的深度空洞可分离卷积代替3×3空洞卷积代替计算上昂贵的3×3空洞卷积,
为了消除由扩展卷积引起的网格伪影,我们使用计算效率高的层次特征融合(HFF)方法对特征图进行融合。
EESP:该模块在EESP-A的基础上将深度可分离空洞卷积替换为了组卷积,从而达到进一步减少参数与计算量的目的。
为了在多个尺度上有效地学习表示,我们对上图c中的EESP块进行了以下更改:
1、用带有stride对应的空洞卷积替换深度空洞卷积
2、添加平均池化操作而不是identity connection,实现维度匹配
3、将相加的特征融合方式替换为concat形式,增加特征的维度。
4、融合原始输入图像的下采样信息,使得特征信息更加丰富。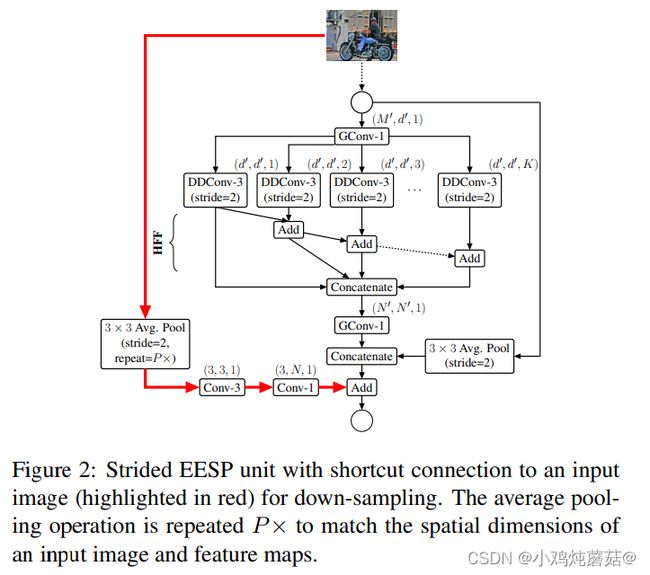
在下采样和卷积(滤波)操作期间,空间信息丢失。为了更好地编码空间关系并有效地学习表示,我们添加了输入图像和当前下采样单元之间的有效 long-range shortcut 连接。这种连接首先对图像进行下采样,使其与特征图的大小相同,然后使用两个卷积的堆栈学习表示。第一个卷积是学习空间表示的标准3×3卷积,而第二个卷积是学习输入之间的线性组合并将其投影到高维空间的逐点卷积。
特点
ESPNet:
这篇文章主要创新点也就是ESP模块的设计,将标准的卷积分解为2个部分
- point-wise convolutions 逐点卷积
- spatial pyramid of dilated convolutions 空间金字塔型空洞卷积
ESPNetV2:
- 将原来ESPNet的逐点卷积(point-wise conv) 替换为组逐点卷积(group point-wise conv);
- 将原来ESPNet的空洞卷积(dilated convolutions) 替换为深度可分离空洞卷积(depth-wise dilated convolution);
- HFF加在深度空洞卷积(depth-wise dilated separable conv) 和 逐点卷积(point-wise (or 1 × 1)) 之间,去除Gridding Artifacts ;
- 将深度空洞卷积(depth-wise dilated conv) 加入下采样操作;
- 加入平均池化(average pooling ),将输入图片信息加入EESP中;
- 使用级联(concatenation) 取代对应元素加法操作(element-wise addition operation )。
参考文献
【图像分割 之 开山之作】 2015-FCN CVPR
FCN论文学习
Unet论文总结
【论文笔记】DeepLab系列论文阅读笔记
Semantic Segmentation--Pyramid Scene Parsing Network(PSPNet)论文解读
BiSeNet V2论文及源码
实时语义分割网络 BiSeNet(附代码解读)
【论文笔记】BiSeNet论文阅读笔记
轻量级网络:ESPNet系列