Python Word2vec训练医学短文本字/词向量实例实现,Word2vec训练字向量,Word2vec训练词向量,Word2vec训练保存与加载模型,Word2vec基础知识
一、Word2vec概念
(1)Word2vec,是一群用来产生词向量的相关模型。这些模型为浅而双层的神经网络,用来训练以重新建构语言学之词文本。网络以词表现,并且需猜测相邻位置的输入词,在word2vec中词袋模型假设下,词的顺序是不重要的。训练完成之后,word2vec模型可用来映射每个词到一个向量,可用来表示词对词之间的关系,该向量为神经网络之隐藏层。
(2)一般分为CBOW(Continuous Bag-of-Words 与Skip-Gram两种模型。CBOW模型的训练输入是某一个特征词的上下文相关的词对应的词向量,而输出就是这特定的一个词的词向量;Skip-Gram模型和CBOW的思路是反着来的,即输入是特定的一个词的词向量,而输出是特定词对应的上下文词向量。CBOW对小型数据库比较合适,而Skip-Gram在大型语料中表现更好。

CBOW
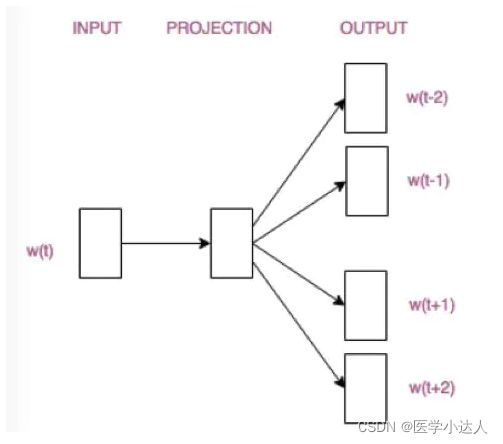
Skip-Gram模型
(3)CBOW(Continuous Bag-of-Words)
CBOW的训练模型如图所示:
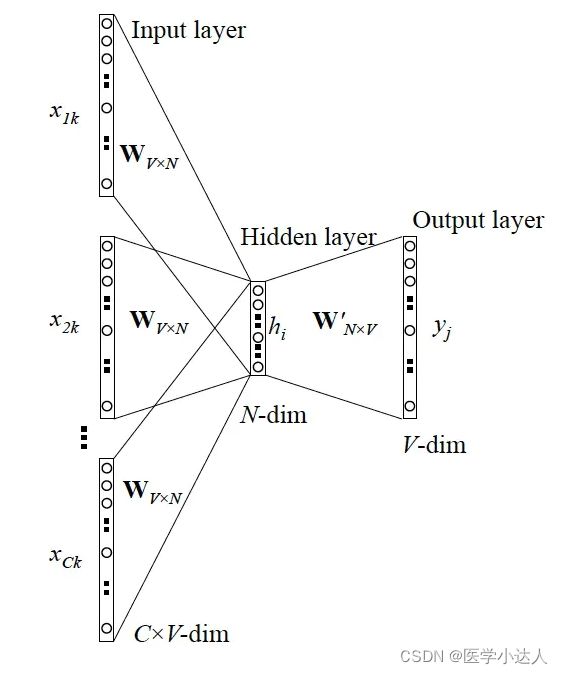
1 )输入层:上下文单词的onehot. {假设单词向量空间dim为V,上下文单词个数为C}
2 )所有onehot分别乘以共享的输入权重矩阵W. {VN矩阵,N为自己设定的数,初始化权重矩阵W}
3 )所得的向量 {因为是onehot所以为向量} 相加求平均作为隐层向量, size为1N.
4) 乘以输出权重矩阵W' {NV}
5 )得到向量 {1V} 激活函数处理得到V-dim概率分布 {PS: 因为是onehot嘛,其中的每一维斗代表着一个单词}
6 )概率最大的index所指示的单词为预测出的中间词(target word)与true label的onehot做比较,误差越小越好(根据误差更新权重矩阵)
(4)Skip-Gram
从直观上理解,Skip-Gram是给定input word来预测上下文。接下来我们来看看如何训练我们的神经网络。假如我们有一个句子“The dog barked at the mailman”。首先我们选句子中间的一个词作为我们的输入词,例如我们选取“dog”作为input word;有了input word以后,我们再定义一个叫做skip_window的参数,它代表着我们从当前input word的一侧(左边或右边)选取词的数量。如果我们设置skip_window=2,那么我们最终获得窗口中的词(包括input word在内)就是['The', 'dog','barked', 'at']。skip_window=2代表着选取左input word左侧2个词和右侧2个词进入我们的窗口,所以整个窗口大小span=2x2=4。另一个参数叫num_skips,它代表着我们从整个窗口中选取多少个不同的词作为我们的output word,当skip_window=2,num_skips=2时,我们将会得到两组 (input word, output word) 形式的训练数据,即 ('dog', 'barked'),('dog', 'the')。
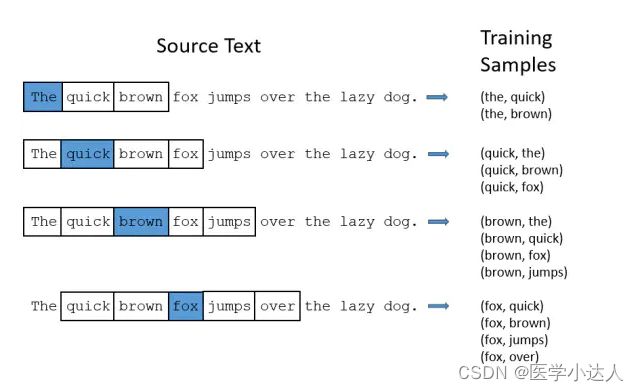
二、word2vec词向量和字向量训练实例:
1、word2vec词向量训练依赖的包:gensim
2、直接安装:
pip install gensim
清华镜像源安装:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple gensim
3、加载gensim,并训练模型,pandas为数据预处理,numpy转化为array
from gensim.models import Word2Vec
import pandas as pd
import numpy as np训练词向量过程model=Word2Vec(sentences,sg=1,size=100,window=5,min_count=5,negative=3,sample=0.001,hs=1,workers=4)
参数配置详情:
(1)sentences 第一个参数是预处理后的训练语料库,是可迭代列表,但是对于较大的语料库,可以直接从磁盘/网络传输句子迭代。
(2)sg=1是skip-gram算法,对于低频词敏感;默认sg=0为CBOW算法
(3)size(int) 是输出词向量的维数默认值是100,。这个维度的取值和我们的语料库大小有关,比如小于100M的文本语料库,则使用默认值就可以。如果是超大语料库,建议增大维度。值太小会导致词映射因为冲突而导致影响结果,值太大则会耗内存并使计算变慢,一般取值为100到200之间,不过见的比较多的也有300的维度
(4)window(int) 是一个句子中当前单词和预测单词之间的最大距离,window越大,则和某一较远的词也会产生上下文关系。默认值为5。window值越大所需要枚举的预测词越多,计算时间越长。
(5)min_count 忽略所有频率低于此值的但单词,默认值是5.
(6)workers表示训练词向量时使用的进程数,默认是但当前运行机器的处理器核数。
还有关于采样和学习率的,一般不常设置:
(1)negative和sample可根据训练结果进行微调,sample表示更高频率的词被随机下采样到所设置的阈值,默认值是 1e-3。
(2)hs=1 表示层级softmax将会被使用,默认hs=0且negative不为0,则负采样将会被使用。
df_01 = pd.read_excel('临床体征.xlsx')#加载数据
df_01.head()
我在这里训练的是医学短文本,有两种训练方式,一种是训练字向量,另一种训练词向量:
4、先看训练字向量,训练的都是excel表内第三列数据,转化为一维矩阵
list_ = list(set(df_01.value.to_list()))
array_ = np.array(list_).reshape(14156,)#转化为一维矩阵
array_
训练模型
model_dis = Word2Vec(array_,min_count=1,negative=4,sample=0.001,hs=1,workers=4)
#保存模型
model_dis.save('disease.model')当前目录生成如下文件:
![]()
加载训练好的模型:
#加载模型
model_ = Word2Vec.load("disease.model")
#查看相应字向量
vector= model_['汗']
print(vector) 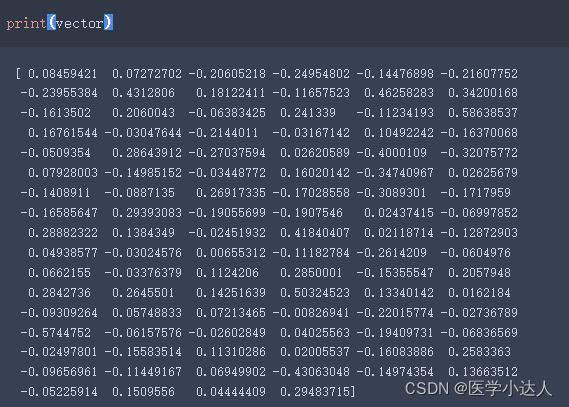
5、训练词向量:注意转化为二维矩阵
list_ = list(set(df_01.value.to_list()))
array_ = np.array(list_).reshape(14156,1)#转化为二维矩阵
array_
model_dis = Word2Vec(array_,min_count=1,negative=4,sample=0.001,hs=1,workers=4)
#保存
model_dis.save('disease_01.model')
#加载
model_ = Word2Vec.load("disease_01.model")
#查询词向量
vector_01= model_['患侧额部无汗']
print(vector_01)
总结:以上是word2vec短文本训练字/词向量的简单实现,本次实验主要针对医学文本,其实最有效的训练是词向量训练+字向量训练,就是在一个list里面既有词又有字,这个就需要应用jieba分词工具把每一个长词进行切词+1-gram切分,这样最有效,能够弥补医学语料的缺乏,没有之一!!!
后续的功能后面再讲,大家下期再见。