TCTrack: Temporal Contexts for Aerial Tracking
TcTrack
论文标题:TCTrack: Temporal Contexts for Aerial Tracking
论文地址:https://arxiv.org/pdf/2203.01885.pdf
论文源码:未开源
单位:同济大学,NUS,南洋理工,阿里达摩院
Introduction
现有的视觉跟踪器远未充分利用现有的时间上下文信息。在本文中提出了TCTrack,一个综合型的框架,以充分利用时间上下文的无人机跟踪算法。时间上下文包含在两个层面上:特征的提取和相似性映射的细化。
在特征提取方面,本文提出了一种在线时间自适应卷积的方法,利用时间信息,通过根据前一帧动态校准卷积权值来增强空间特征。对于相似图的细化,我们提出了一种自适应时间转换器,它首先有效地编码时间知识,然后解码时间信息以精确调整相似图。TCTrack是有效和高效的:对四个无人机跟踪基准的评估显示其令人惊讶的性能;真实世界的无人机测试显示,它在NVIDIA Jetson AGX Xavier上的高速超过27FPS。
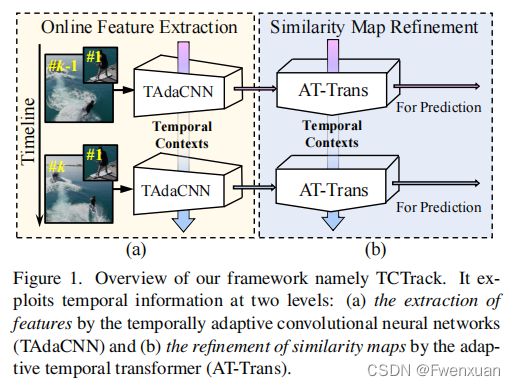
TCTrack在两个层次上引入了时间上下文信息到跟踪pipeline中,即特征和相似性映射。在特征层面,本文提出了一种在线时间自适应卷积(TAdaConv),在此基础上,将标准卷积网络转换为时间自适应网络(TAdaCNN)。由于在线TAdaConv中的校准是基于前一帧中特征的全局特征图信息,因此TAdaCNN只导致了可以忽略不计的帧率下降,但显著提高了跟踪性能。
在相似度图层面上,提出了一种自适应时间变换器(ATTrans),根据时间信息对相似度图进行细化。具体来说,AT-Trans采用编码-解码器结构,其中(i)编码器通过将之前的先验与当前相似图集成,产生当前时间步长的时间先验知识,(ii)解码器基于产生的时间先验知识以自适应的方式改进相似图。
对TCTrack的评估显示了该框架的有效性和效率。与51个最先进的跟踪器相比,在4个标准无人机跟踪基准上展现了优秀的性能,其中TCTrack在PC上也有高帧率125.6FPS。在NVIDIA Jetson AGX Xavier上的真实部署显示,TCTrack在无人机跟踪方面保持了非常高的稳定性和鲁棒性,在超过27FPS的帧率下运行。
Temporal Contexts for Aerial Tracking
此图为整体结构图
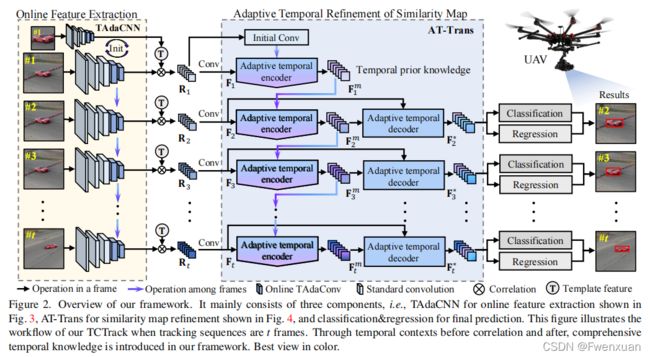
Feature extraction with online TAdaConv
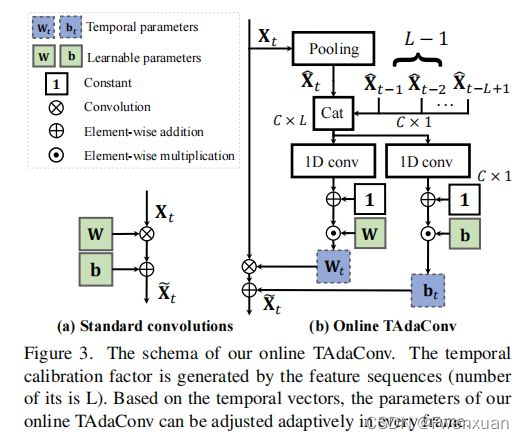
TAdaConv作为整体框架的重要组成部分,是用于特征提取过程来考虑时间上下文。形式上,给定第 t t h t_{th} tth帧中某一阶段对在线TAdaConv的输入特征 X t X_t Xt,TAdaConv X ^ \hat X X^的输出如下:
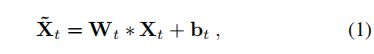
其中,算子 ∗ ∗ ∗表示卷积运算, W t , b t W_{t},b_{t} Wt,bt是卷积的时间权重和偏差。一个标准的卷积层使用可学习的参数来表示权重和偏差,并在整个跟踪序列中共享它们。不同的是,在线卷积层中,参数是由可学习参数( W b W_b Wb和 b b b_b bb)和校准因子计算的,这些校准因子因每一帧而不同,即, W t = W b ⋅ α t w W_{t}=W_{b}\cdot \alpha_{t}^{w} Wt=Wb⋅αtw和 b t = b b ⋅ α t b b_{t}=b_{b}\cdot \alpha_{t}^{b} bt=bb⋅αtb。与视频理解的原始结构不同,online TAdaConv一次处理一帧。
因此,它只考虑过去的时间背景,就像在现实世界中的跟踪一样。具体来说,在实验中保留了一个包含 L L L帧的特征图descriptors X ^ t ∈ R C \hat X_{t}\in \R^{C} X^t∈RC的时间上下文队列 X ^ t ∈ R L × C \hat X_{t}\in \R^{L \times C} X^t∈RL×C,包括当前框架的队列:
![]()
其中,Cat表示连接,而帧descriptors是通过在每个未来帧的特征上的全局平均池(GAP)获得的,即 X ^ t = G A P ( X t ) \hat X_{t}=GAP(X_{t}) X^t=GAP(Xt)。对于生成校准因子 α t w \alpha_{t}^{w} αtw和 α t b \alpha_{t}^{b} αtb,在卷积核大小为 L L L的时间上下文队列 X ^ \hat X X^上进行了两次卷积,即 α t w = F w ( X ^ ) + 1 \alpha_{t}^{w}=\mathcal {F}_{w}(\hat X)+1 αtw=Fw(X^)+1, α b t = F b ( X ^ ) + 1 \alpha_{b}^{t}=\mathcal {F}_{b}(\hat X)+1 αbt=Fb(X^)+1,其中 F i \mathcal {F}_{i} Fi表示卷积操作。
此外, F \mathcal {F} F的权值被初始化为零,因此在初始化时, W t = W b W_t=W_b Wt=Wb和 b t = b b b_t=b_b bt=bb。 t ≤ L − 1 t≤L−1 t≤L−1,如果之前没有足够的前帧,我们用第一帧 X ^ \hat X X^的特征填充。由于我们的主干 ϕ t a d a ϕ_{tada} ϕtada是在特征提取过程中考虑时间上下文的,因此可以得到第 t t t帧的相似度图 R t R_t Rt为:
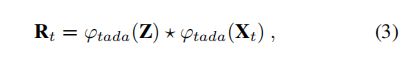
其中, Z Z Z表示template和 ⋆ \star ⋆表示深度相关性。然后, F t \mathbf {F}_{t} Ft可以通过卷积层得到,即 F t = F R t \mathbf {F}_{t}=\mathcal F_{R_{t}} Ft=FRt。
Similarity Refifinement with AT-Trans
除了在特征提取过程中考虑时间上下文外,在本工作中,还提出了一个AT-Trans来根据时间上下文来细化相似度映射 F t \mathbf {F}_{t} Ft。
在描述AT-Trans的细节之前,首先回顾多头注意力。多头注意力多头注意作为Transformer的基本要素,表述如下:
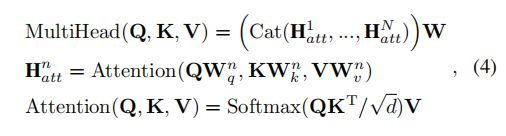
与CNN相比,transformer能更有效地对全局上下文信息进行编码。因此,为了更有效地利用全局时间上下文,我们提出了一种基于transformer的时间集成策略来对全局上下文信息进行连续编码。此外,现有的基于时间的方法通常存储输入特征用于时间建模,不可避免地会引入敏感参数和不必要的计算。在本工作中,为了消除不必要的操作和敏感参数,我们采用了在线更新策略。
Transformer encoder.
该编码器通过将先前的知识与当前的特征相结合来生成时间先验知识。通常,在应用时间信息滤波器之前,我们会堆叠两个多层注意层。通过进一步将过滤后的信息附加多头注意层来获得当前步骤的最终时间先验知识。
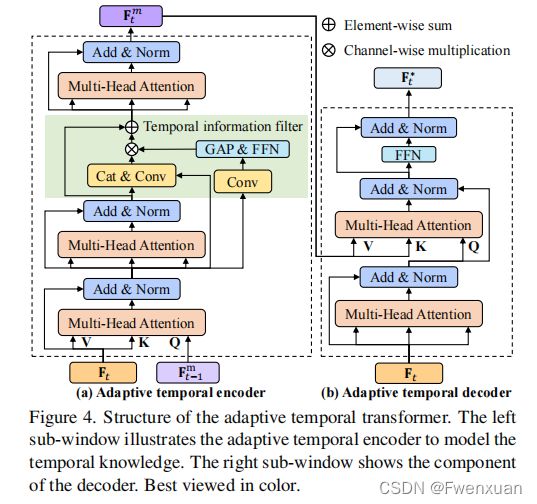
根据之前的时间先验知识 F t − 1 m \mathbf {F}_{t-1}^{m} Ft−1m和当前的相似度图 F t \mathbf {F}_{t} Ft,有两种方式结合当前帧信息和之前的时间先验信息。一个使用 F t − 1 m \mathbf {F}_{t-1}^{m} Ft−1m作为query,而 F t \mathbf {F}_{t} Ft作为key和value,而另一个则反向使用它们。在我们的方法中,采用前者,因为这本质上更强调当前的相似性图。因为当前帧的时间信息比之前的信息更有价值,以更准确地表示当前对象的特征。因此,通过以下方法得到了第 t t h t_{th} tth帧 F t 2 \mathbf {F}_{t}^{2} Ft2中堆叠的多头注意层的输出:
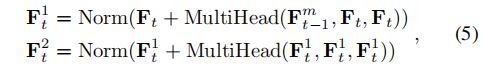
由于无人机跟踪可能经常会遇到由运动模糊或遮挡引起的不太有用的上下文,因此,如果我们在不进行任何过滤的情况下传递完整的时间信息,则可能会包含一些不必要的上下文。
为了消除不需要的信息,通过将前馈网络FFN附加到全局平均池化GAP获得的的全局特征 F t 1 \mathbf {F}_{t}^{1} Ft1,即 α = F F N ( G A P ( F ( F t 1 ) ) ) \alpha=FFN(GAP(\mathcal {F}(\mathbf {F}_{t}^{1}))) α=FFN(GAP(F(Ft1))),生成一个整洁的时间信息滤波器。过滤后的信息 F t f \mathbf {F}_{t}^{f} Ftf由:
![]()
其中, F \mathcal {F} F为卷积层。由此,可以得到第 t t h t_{th} tth帧、 F t m \mathbf {F}_{t}^{m} Ftm的信息如下:
![]()
因此,对于每一帧,我们都会更新的时间知识,而不是保存所有的时间知识。总的来说,由于这种策略以及时间过滤器和多头注意,AT-Trans以一种记忆高效的方式自适应地编码时间先验。
对于跟踪序列中的第一帧,由于不同目标的特征是不同的,因此对初始时间先验 F 0 m \mathbf {F}_{0}^{m} F0m使用统一的初始化是不合理的。观察到第一帧的相似映射本质上有效地代表了目标对象的语义特征,通过对初始相似映射 F 0 \mathbf {F}_{0} F0的卷积来设置初始时间先验,即 F 0 m = F ( F 0 ) \mathbf {F}_{0}^{m}=\mathcal {F}(\mathbf {F}_{0}) F0m=F(F0)。
Transformer decoder.
根据时间先验知识 F t m \mathbf {F}_{t}^{m} Ftm,解码器旨在细化相似度图。为了更好地探索时间信息与当前空间特征 F t F_{t} Ft之间的相互关系,我们采用了两个在输出前具有前馈的多层注意层。通过生成注意图,可以提取时间知识 F t m \mathbf {F}_{t}^{m} Ftm中的有效信息,细化相似度图 F t \mathbf {F}_{t} Ft,得到最终输出 F t ∗ \mathbf {F}_{t}^{*} Ft∗:

基于AT-Trans的编码器-解码器结构,可以有效地利用时间上下文来细化相似度图,以提高鲁棒性和准确性。
Experiments
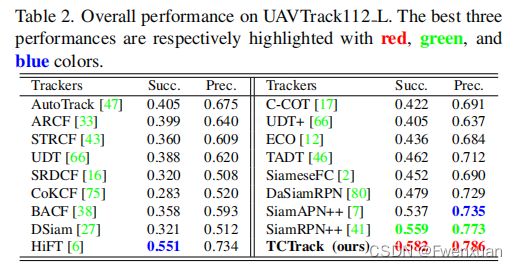
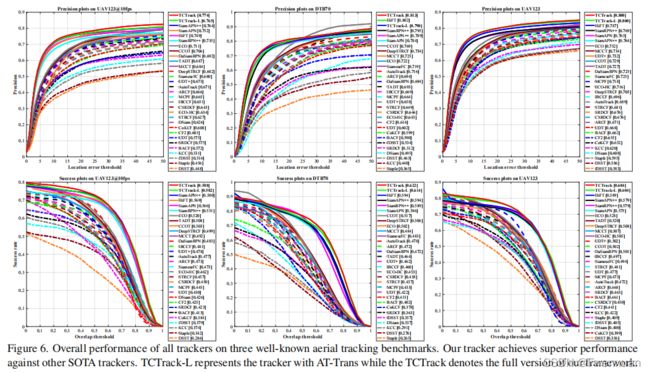
我们的框架在四个公共权威基准上进行评估,并在真实世界的空中跟踪条件下进行测试。我们的方法在四个著名的无人机跟踪基准上进行了全面的评估,即UAV123、UAVTrack112L、UAV123@10fps和DTB70。其中包括了51个现有的顶级跟踪器,以进行彻底的比较,它们的结果是通过运行官方代码及其相应的超参数来获得的。为了更清晰的比较,我们将它们分为两组跟踪器进行对比:(i)轻量级跟踪器和(ii)深度跟踪器。
我们使用AlexNet作为我们的跟踪器的主干,因为信息效率是无人机跟踪的关键。对比NVIDIA Jetson AGX Xavier平台上不同流行骨干网络的推理时间,AlexNet的延迟最低。对于初始化,我们为AlaxNet使用ImageNet预训练模型,并使用中相同的在线TadaConv的初始化。我们的TCTrack中的AT-Trans是随机初始化的。
具体的分解实验和对比数据可以看论文。