Explainable AI:Tensorboard可视化指南
Tensorboard可视化指南
- Tensorboard
-
- Tensorboard安装
- 使用教程
-
- Tensorboard Scalar
- Tensorboard Graphs
- Tensorboard Distribution
- Tensorboard Histograms
- Confusion Matrix
- 可视化训练集图像
- 微调超参数
参考:The complete guide to ML model visualization with Tensorboard
Tensorboard
当我们训练一个机器学习模型的时候,你需要做大量的实验去验证模型的性能,调试你的模型。在调试的过程中需要对模型计算过程进行可视化。Tensorboard是一种可以帮你可视化模型的工具,它可以可视化一些指标,比如训练和验证集的损失和正确率,权重和偏置、计算模型图等。
Tensorboard安装
Tensorboard安装过程比较简单,在conda环境中,可以通过以下命令进行安装:
conda install -c conda-forge tensorboard
当然可以使用pip进行安装:
pip install tensorboard
使用教程
使用的数据集是:Bank Marketing Data Set。该数据与银行营销团队打电话说服客户订阅定期存款有关。在这一个过程中,建立一个神经网络,预测客户是否会订阅定期存款。该数据也可以在kaggle上面进行下载,地址为:Bank Customers Survey。具体过程如下:
- 导入必要的包
import numpy as np
import pandas as pd
import tensorflow as tf
import datetime
from tensorflow.keras.callbacks import TensorBoard
- 加载数据
dataset = pd.read_csv('bank_customer_survey.csv')
X = dataset.iloc[:, :-1].values
y = dataset.iloc[:, -1].values
- 数据预处理,主要是one-hot编码
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
X[:, 2] = le.fit_transform(X[:, 2])
X[:, 4] = le.fit_transform(X[:, 4])
X[:, 6] = le.fit_transform(X[:, 6])
X[:, 7] = le.fit_transform(X[:, 7])
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder
ct = ColumnTransformer(transformers = [('encoder', OneHotEncoder(), [1,3,8,10,15])], remainder = 'passthrough')
X = np.array(ct.fit_transform(X))
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
- 创建
callbacks
tensorboard_callback = TensorBoard(
log_dir=log_dir,
histogram_freq=1,
write_graph=True,
write_images=False,
update_freq="epoch",
)
Tensorboard参数说明:
TensorBoard(
log_dir="logs",
histogram_freq=0,
write_graph=True,
write_images=False,
update_freq="epoch",
profile_batch=2,
embeddings_freq=0,
embeddings_metadata=None,
**kwargs
)
- log_dir – the path to the directory where we are going to store our logs.
- histogram_freq – this represents the frequency at which to calculate weight histograms and compute activation for each layer in the model. The default value is set to 0. If it isn’t set or it’s set to 0, the histogram won’t be computed. Validation data must be specified for histogram visualizations.
- write_graph – Whether to visualize the graph in Tensorboard. If set to True, it can make a log file large.
- write_images – Boolean, whether to visualize model weights as images in Tensorboard. The default value is False.
- update_freq – Default value is epoch, this parameter expects a batch, epoch or an integer. If a batch is supplied it means that losses and metrics will be written by a callback to Tensorboard after every batch or if epoch is supplied it’s going to write after every epoch. Otherwise, if an integer is supplied, let’s say 50, it means that losses and metrics will be written after every 50 batches.
- profile_batch – It sets the batch or batches to be profiled, the default value is 2, meaning the second batch will be profiled. To disable profiling, set the value to zero, profile_batch can only be a positive integer or a range let’s say (2,6) this will profile batches from 2 to 6.
- embeddings_freq – Default value is 0, this represents the frequency of visualizing embedding layers.
- embeddings_metadata – A dictionary that maps a layer to a file in which metadata for this embedding layer is saved, default value is None.
- 常见模型
ann = tf.keras.models.Sequential()
ann.add(tf.keras.layers.Dense(units=15, activation='relu'))
ann.add(tf.keras.layers.Dense(units=15, activation='relu'))
ann.add(tf.keras.layers.Dense(units=15, activation='relu'))
ann.add(tf.keras.layers.Dense(units=1, activation='sigmoid'))
模型的编译:
ann.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])
ann.fit(X_train, y_train, batch_size = 32, epochs = 50, callbacks=[tensorboard_callback])
- 使用tensorboard
打开Tensorboard的命令:
tensorboard --logdir logs/fit

访问以下网址:http://localhost:6006/#scalars打开tensorboard的可视面板。假设提示“No dashboards are active for the current data set”,说明数据还没被保存,训练还在继续。下图是以上训练过程中的数据,在面板上有“SCALARS”,“GRAPHS”等面板,接下来我们一起来看下。

Tensorboard Scalar
It shows changes in loss and accuracy after every epoch – When an entire dataset is passed through a neural network both forward and backward propagation – It is important to understand loss and accuracy as training progresses as it will be important to understand at what point these metrics are steady, understanding this will help prevent overfitting.

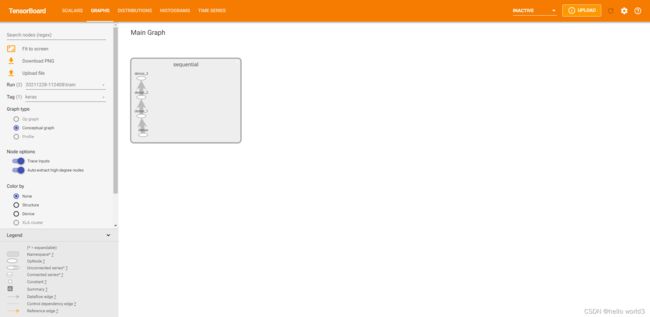
Tensorboard Graphs
“GRAPHS”面板显示计算图模型,可以直观了解它是否符合所需的设计。默认情况下,op级别图在标记上选择为“默认”,但您可以通过在标记上选择它来更改为“Keras”。op级别图显示TensorFlow如何理解您的程序,它可以作为如何更改模型的指南。
Tensorboard Distribution
这显示了张量的分布,并用于显示每个epoch中权重和偏差的分布:它们是否如预期的那样变化。

Tensorboard Histograms
这显示了直方图中张量的分布,并用于显示每个epoch中权重和偏差的分布——无论它们是否如预期的那样变化。

Confusion Matrix
混淆矩阵是用表格可视化的方式展示模型的性能,每一行都是模型预测的值,而每一列表示实际的值。当训练一个机器学习模型的时候,尤其是分类模型,都可以用混淆矩阵去显示模型的性能。而Tensorboard通过日志对每个epoch展示混淆矩阵,以mnist为例接下来我们看一下怎么处理。
- 导入必要的模块以及数据集
import numpy as np
import pandas as pd
import tensorflow as tf
import datetime
import sklearn
mnist = tf.keras.datasets.mnist
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train, X_test = X_train/255.0, X_test/255.0
class_names = ['Zero','One','Two','Three','Four','Five','Six','Seven','Eight','Nine']
- 使用matplotlib模块画出混淆矩阵
import itertools
import matplotlib.pyplot as plt
def plot_confusion_matrix(cm, class_names):
figure = plt.figure(figsize=(8, 8))
plt.imshow(cm, interpolation='nearest', cmap=plt.cm.Accent)
plt.title("Confusion matrix")
plt.colorbar()
tick_marks = np.arange(len(class_names))
plt.xticks(tick_marks, class_names, rotation=45)
plt.yticks(tick_marks, class_names)
cm = np.around(cm.astype('float') / cm.sum(axis=1)[:, np.newaxis], decimals=2)
threshold = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
color = "white" if cm[i, j] > threshold else "black"
plt.text(j, i, cm[i, j], horizontalalignment="center", color=color)
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
return figure
- 创建日志目录
logdir = "logs/image/"
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir = logdir, histogram_freq = 1)
file_writer_cm = tf.summary.create_file_writer(logdir + '/cm')
由于matplotlib文件格式不能转变为图像,因此这一步需要转换:
def plot_to_image(figure):
buf = io.BytesIO()
plt.savefig(buf, format='png')
plt.close(figure)
buf.seek(0)
digit = tf.image.decode_png(buf.getvalue(), channels=4)
digit = tf.expand_dims(digit, 0)
return digit
从日志中计算每一个epoch的混淆矩阵:
from tensorflow import keras
from sklearn import metrics
import io
def log_confusion_matrix(epoch, logs):
predictions = model.predict(X_test)
predictions = np.argmax(predictions, axis=1)
cm = metrics.confusion_matrix(y_test, predictions)
figure = plot_confusion_matrix(cm, class_names=class_names)
cm_image = plot_to_image(figure)
with file_writer_cm.as_default():
tf.summary.image("Confusion Matrix", cm_image, step=epoch)
- 通过LambdaCallback创建callbacks
cm_callback = tf.keras.callbacks.LambdaCallback(on_epoch_end=log_confusion_matrix)
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')])
model.compile(optimizer='sgd', loss='sparse_categorical_crossentropy',metrics=['accuracy'])
model.fit(X_train, y_train, batch_size = 32, validation_split=0.2, epochs = 30, callbacks=[tensorboard_callback, cm_callback])
最终展示如下所示:

可视化训练集图像
Tensorflow Image Summary API 可以可视化权重,tensors或者是输入数据。
logdir = "logs/single-image/"
file_writer = tf.summary.create_file_writer(logdir)
import numpy as np
with file_writer.as_default():
image = np.reshape(X_train[4], (-1, 28, 28, 1))
tf.summary.image("Single Image", image, step=0)

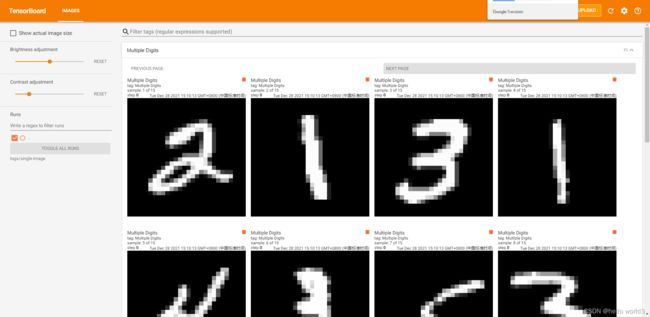
可视化多张训练数据:
import numpy as np
with file_writer.as_default():
images = np.reshape(X_train[5:20], (-1, 28, 28, 1))
tf.summary.image("Multiple Digits", images, max_outputs=16, step=0)
import io
import matplotlib.pyplot as plt
class_names = ['Zero','One','Two','Three','Four','Five','Six','Seven','Eight','Nine']
logdir = "logs/actual-images/"
file_writer = tf.summary.create_file_writer(logdir)
def image_grid():
figure = plt.figure(figsize=(12,8))
for i in range(25):
plt.subplot(5, 5, i + 1)
plt.xlabel(class_names[y_train[i]])
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(X_train[i], cmap=plt.cm.coolwarm)
return figure
def plot_to_image(figure):
buf = io.BytesIO()
plt.savefig(buf, format='png')
plt.close(figure)
buf.seek(0)
image = tf.image.decode_png(buf.getvalue(), channels=4)
image = tf.expand_dims(image, 0)
return image
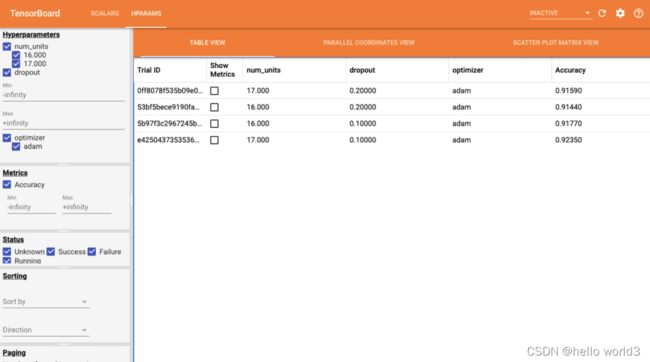
微调超参数
在机器学习中, 超参数可以控制学习的进程,超参数分为这两类:
- 模型超参数:模型超参数的值无法从数据中推算出来,如神经网络的拓扑结构和大小
- 算法参数:如学习率、批量大小等参数
导入相关的包:
from tensorboard.plugins.hparams import api as hp
logdir = "logs/hparamas"
需要调整的参数有:
- 第一层神经元的个数
- dropout rate
- 优化方法
HP_NUM_UNITS = hp.HParam('num_units', hp.Discrete([16, 17]))
HP_DROPOUT = hp.HParam('dropout', hp.RealInterval(0.1,0.2))
HP_OPTIMIZER = hp.HParam('optimizer', hp.Discrete(['adam', 'sgd', 'rmsprop']))
将信息写入到日志文件:
METRIC_ACCURACY = 'accuracy'
with tf.summary.create_file_writer(logdir).as_default():
hp.hparams_config(
hparams=[HP_NUM_UNITS, HP_DROPOUT, HP_OPTIMIZER],
metrics=[hp.Metric(METRIC_ACCURACY, display_name='Accuracy')],)
创建模型:
def create_model(hparams):
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(hparams[HP_NUM_UNITS], activation='relu'),
tf.keras.layers.Dropout(hparams[HP_DROPOUT]),
tf.keras.layers.Dense(10, activation='softmax')])
model.compile(optimizer=hparams[HP_OPTIMIZER],
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(X_train, y_train, epochs=5)
loss, accuracy = model.evaluate(X_test, y_test)
return accuracy
def experiment(experiment_dir, hparams):
with tf.summary.create_file_writer(experiment_dir).as_default():
hp.hparams(hparams)
accuracy = create_model(hparams)
tf.summary.scalar(METRIC_ACCURACY, accuracy, step=1)
experiment_no = 0
for num_units in HP_NUM_UNITS.domain.values:
for dropout_rate in (HP_DROPOUT.domain.min_value, HP_DROPOUT.domain.max_value):
for optimizer in HP_OPTIMIZER.domain.values:
hparams = {
HP_NUM_UNITS: num_units,
HP_DROPOUT: dropout_rate,
HP_OPTIMIZER: optimizer,}
experiment_name = f'Experiment {experiment_no}'
print(f'Starting Experiment: {experiment_name}')
print({h.name: hparams[h] for h in hparams})
experiment(logdir + experiment_name, hparams)
experiment_no += 1