SVM支持向量机
SVM
三部分:间隔,对偶,核方法
分类:hard-margin SVM, soft-margin SVM, kernel SVM
属于判别模型,在小样本的分类上表现非常好
1 Hard-margin
1.1 问题描述
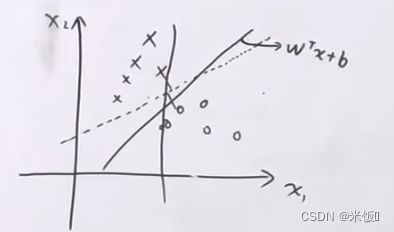
由线性可分引入:
两类是线性可分的,寻找最合适的边界 → \rightarrow →判别模型。该问题是求最大的分类间隔margin。其中:
d a t a = { ( x i , y i ) } i = 1 n , x i ∈ R p , y i ∈ { 1 , − 1 } data=\{(x_i,y_i)\}^n_{i=1}, x_i\in \mathbb{R}^p,y_i\in \{1,-1\} \\ data={(xi,yi)}i=1n,xi∈Rp,yi∈{1,−1}
规定 { y i = 1 w T x + b > 0 y i = − 1 w T x + b < 0 等价于 y i ( w T x i + b ) > 0 规定 \begin{cases} y_i=1& w^Tx+b>0 \\ y_i=-1& w^Tx+b<0 \end{cases} \quad等价于y_i(w^Tx_i+b)>0 规定{yi=1yi=−1wTx+b>0wTx+b<0等价于yi(wTxi+b)>0
数据 x i x_i xi到直线 w T x + b w^Tx+b wTx+b的距离是:
d i s = 1 ∣ ∣ w ∣ ∣ ∣ w T x i + b ∣ dis = \frac{1}{||w||}|w^Tx_i+b| dis=∣∣w∣∣1∣wTxi+b∣
margin被定义为两类中距离分类边界最近的点:
m i n w , b , x i i = 1 , . . . n 1 ∣ ∣ w ∣ ∣ ∣ w T x i + b ∣ \underset{i = 1,...n}{\underset{w,b,x_i}{min}}\ \frac{1}{||w||}|w^Tx_i+b| i=1,...nw,b,ximin ∣∣w∣∣1∣wTxi+b∣
则原问题转化为:
{ m a x w , b m i n x i i = 1 , . . . n 1 ∣ ∣ w ∣ ∣ ∣ w T x i + b ∣ s t . y i ( w T x i + b ) > 0 \begin{cases} \underset{w,b}{max}\underset{i = 1,...n}{\underset{x_i}{min}}\ \frac{1}{||w||}|w^Tx_i+b| \\ st.\ y_i(w^Tx_i+b)>0 \end{cases} ⎩ ⎨ ⎧w,bmaxi=1,...nximin ∣∣w∣∣1∣wTxi+b∣st. yi(wTxi+b)>0
w与x无关,可以提出来,同时距离与y相乘可以去掉绝对值,因为同号,因此原问题等价于:
{ m a x w , b 1 ∣ ∣ w ∣ ∣ m i n x i , y i i = 1 , . . . n y i ( w T x i + b ) ∃ r > 0 , s t . m i n x i , y i i = 1 , . . . n y i ( w T x i + b ) = r \begin{cases} \underset{w,b}{max} \frac{1}{||w||}\underset{i = 1,...n}{\underset{x_i,y_i}{min}}\ y_i(w^Tx_i+b) \\ \exists r>0, st. \underset{i = 1,...n}{\underset{x_i,y_i}{min}}\ y_i(w^Tx_i+b)=r \end{cases} ⎩ ⎨ ⎧w,bmax∣∣w∣∣1i=1,...nxi,yimin yi(wTxi+b)∃r>0,st.i=1,...nxi,yimin yi(wTxi+b)=r
由于距离公式 1 ∣ ∣ w ∣ ∣ ∣ w T x i + b ∣ \frac{1}{||w||}|w^Tx_i+b| ∣∣w∣∣1∣wTxi+b∣,可以令 w ′ = r w , b ′ = r b w' = rw, b'=rb w′=rw,b′=rb进行同比例缩放,上述的第二行约束条件可以变为 m i n y i ( w T x i + b ) = 1 min\ y_i(w^Tx_i+b)=1 min yi(wTxi+b)=1,也等价于 y i ( w T x i + b ) ≥ 1 y_i(w^Tx_i+b)\ge1 yi(wTxi+b)≥1。第一行的min部分变为约束,求 m a x 1 ∣ ∣ w ∣ ∣ max \frac{1}{||w||} max∣∣w∣∣1等价于求 m i n 1 2 w T w min\ \frac{1}{2}w^Tw min 21wTw。因此该问题可以最终表示为:
{ m i n w , b 1 2 w T w s t . y i ( w T x i + b ) ≥ 1 for i= 1,...n \begin{cases} \underset{w,b}{min}\ \frac{1}{2}w^Tw \\ st.\ y_i(w^Tx_i+b)\ge1 \quad \text{for i= 1,...n} \end{cases} ⎩ ⎨ ⎧w,bmin 21wTwst. yi(wTxi+b)≥1for i= 1,...n
这是一个凸优化问题(convex optimization)。
1.2 问题求解
1.1中问题的最终表示是原问题(primal problem),将其转化为对偶问题(dual problem),并使用拉格朗日乘数法求解。
拉格朗日乘数法简单可以描述为:对原函数 m i n f ( x ) min\ f(x) min f(x)的所有约束条件如 g ( x ) = 0 , h ( x ) ≤ 0 g(x)=0,h(x)\le0 g(x)=0,h(x)≤0,拉格朗日函数等于原函数加上拉格朗日乘子与约束条件表达式的乘积,即 L = f ( x ) + η g ( x ) + λ h ( x ) L=f(x)+\eta g(x)+\lambda h(x) L=f(x)+ηg(x)+λh(x)。(简单记为拉格朗日函数中,原函数是求最小值,原函数后面的约束都是负的,减大于0的约束等价于加小于0的约束)
同时有kkt条件(以上述h(x)为例,kkt条件细节见3.2.5):当 h ( x ) < 0 h(x)<0 h(x)<0时约束不起作用,等价于 λ = 0 \lambda=0 λ=0没有约束;当 h ( x ) = 0 h(x)=0 h(x)=0,此时约束条件起作用, λ > 0 \lambda>0 λ>0。因此存在条件 λ ≥ 0 \lambda\ge0 λ≥0。当 h ( x ) > 0 h(x)>0 h(x)>0时
此问题的拉格朗日函数为:
L ( w , b , λ ) = 1 2 w T w + ∑ i = 1 n λ i ( 1 − y i ( w T x i + b ) ) L(w,b,\lambda) = \frac{1}{2}w^Tw + \overset{n}{\underset{i=1}{\sum}}\lambda_i(1-y_i(w^Tx_i+b)) L(w,b,λ)=21wTw+i=1∑nλi(1−yi(wTxi+b))
问题转化为,此时w,b不再有约束:
{ m i n w , b m a x λ L ( w , b , λ ) s t . λ i ≥ 0 \begin{cases} \underset{w,b}{min}\ \underset{\lambda}{max}\ L(w,b,\lambda) \\ st.\ \lambda_i\ge0 \end{cases} ⎩ ⎨ ⎧w,bmin λmax L(w,b,λ)st. λi≥0
由于该问题是一个二次凸优化,满足强对偶关系,问题转化为:
{ m a x λ m i n w , b L ( w , b , λ ) s t . λ i ≥ 0 \begin{cases} \underset{\lambda}{max}\ \underset{w,b}{min}\ L(w,b,\lambda) \\ st.\ \lambda_i\ge0 \end{cases} ⎩ ⎨ ⎧λmax w,bmin L(w,b,λ)st. λi≥0
1.2.1 分类边界:
通过求解最小值问题 m i n w , b L ( w , b , λ ) \underset{w,b}{min}\ L(w,b,\lambda) w,bmin L(w,b,λ),可以得到分类边界 w ∗ T x + b ∗ w^{*T}x+b^* w∗Tx+b∗:
对b求偏导:
∂ L ∂ b = − ∑ i = 1 n λ i y i = 0 \frac{\partial L}{\partial b} = -\overset{n}{\underset{i=1}{\sum}} \lambda_iy_i=0 ∂b∂L=−i=1∑nλiyi=0
将原式括号拆开,b求偏导的结果带入原式(只消最后一项是因为b可以提出来,而倒数第二项的 w T x i w^Tx_i wTxi则不能):
L ( w , b , λ ) = 1 2 w T w + ∑ i = 1 n λ i − ∑ i = 1 n λ i y i w T x i − ∑ i = 1 n λ i y i b = 1 2 w T w + ∑ i = 1 n λ i − ∑ i = 1 n λ i y i w T x i \begin{aligned} L(w,b,\lambda) &= \frac{1}{2}w^Tw + \overset{n}{\underset{i=1}{\sum}}\lambda_i -\overset{n}{\underset{i=1}{\sum}}\lambda_i y_i w^Tx_i-\overset{n}{\underset{i=1}{\sum}}\lambda_i y_i b\\ &= \frac{1}{2}w^Tw + \overset{n}{\underset{i=1}{\sum}}\lambda_i -\overset{n}{\underset{i=1}{\sum}}\lambda_i y_i w^Tx_i \end{aligned} L(w,b,λ)=21wTw+i=1∑nλi−i=1∑nλiyiwTxi−i=1∑nλiyib=21wTw+i=1∑nλi−i=1∑nλiyiwTxi
接下来对w求偏导:
∂ L ∂ w = w − ∑ i = 1 n λ i y i x i = 0 → w ∗ = ∑ i = 1 n λ i y i x i \frac{\partial L}{\partial w} = w-\overset{n}{\underset{i=1}{\sum}}\lambda_i y_i x_i=0 \rightarrow \quad w^*=\overset{n}{\underset{i=1}{\sum}}\lambda_i y_i x_i ∂w∂L=w−i=1∑nλiyixi=0→w∗=i=1∑nλiyixi
距离分类边界最近的点满足 y i ( w T x i + b ) = 1 y_i(w^Tx_i+b)=1 yi(wTxi+b)=1,如图所示:(虚线所示,即满足约束条件的边界点,这些点被称为支持向量,support vector)

因此可由此求出 b ∗ b^* b∗,( y k 2 y_k^2 yk2=1,这里的 ( x k , y k ) (x_k,y_k) (xk,yk)并不是点坐标,而是数据和他的标签):
∃ ( x k , y k ) s . t . y k ( w T x k + b ) = 1 ↓ y k 2 ( w T x k + b ) = y k b ∗ = y k − ∑ i = 1 n λ i y i x i T x k \exists (x_k,y_k)\ s.t.\ y_k(w^Tx_k+b)=1\\ \downarrow\\ y_k^2 (w^Tx_k+b) =y_k \\ b^* = y_k-\overset{n}{\underset{i=1}{\sum}}\lambda_i y_i x_i^Tx_k ∃(xk,yk) s.t. yk(wTxk+b)=1↓yk2(wTxk+b)=ykb∗=yk−i=1∑nλiyixiTxk
因此决策函数和决策平面为:
f ( x ) = s i g n ( w ∗ T x + b ∗ ) w ∗ T x + b ∗ f(x)=sign(w^{*T}x+b^*)\qquad w^{*T}x+b^* f(x)=sign(w∗Tx+b∗)w∗Tx+b∗
参数w*可以看做是数据的线性组合结果。对于 λ i \lambda_i λi,只有当数据是支持向量的时候(在决策边界上,约束条件起作用时), λ i > 0 \lambda_i>0 λi>0,其余时间 λ i = 0 \lambda_i=0 λi=0。如上图所示,由于大部分数据点在决策边界内而不是决策边界上,因此大部分 λ i = 0 \lambda_i=0 λi=0,这也证明SVM生成的边界是由少数数据决定的。
注意:
由于这是硬分类,因此 b ∗ b^* b∗是唯一的。在软分类中,支持向量的距离是不唯一的,因此要对所有的支持向量都求一次 b ∗ b^* b∗,再取平均值。
1.2.2 原问题转化:
带入w*,其中 λ i , y i \lambda_i,y_i λi,yi为标量, x i x_i xi为向量:
L ( w , b , λ ) = 1 2 ( ∑ i = 1 n λ i y i x i ) T ( ∑ j = 1 n λ j y j x j ) − ∑ i = 1 n λ i y i ( ∑ i = 1 n λ i y i x i ) T x i + ∑ i = 1 n λ i = − 1 2 ∑ i = 1 n ∑ j = 1 n λ i λ j y i y j x i T x j + ∑ i = 1 n λ i \begin{aligned} L(w,b,\lambda) &= \frac{1}{2}(\overset{n}{\underset{i=1}{\sum}}\lambda_i y_i x_i)^T(\overset{n}{\underset{j=1}{\sum}}\lambda_j y_j x_j) - \overset{n}{\underset{i=1}{\sum}}\lambda_i y_i (\overset{n}{\underset{i=1}{\sum}}\lambda_i y_i x_i)^Tx_i+\overset{n}{\underset{i=1}{\sum}}\lambda_i\\ &=-\frac{1}{2}\overset{n}{\underset{i=1}{\sum}}\overset{n}{\underset{j=1}{\sum}}\lambda_i \lambda_jy_iy_jx_i^Tx_j+\overset{n}{\underset{i=1}{\sum}}\lambda_i \end{aligned} L(w,b,λ)=21(i=1∑nλiyixi)T(j=1∑nλjyjxj)−i=1∑nλiyi(i=1∑nλiyixi)Txi+i=1∑nλi=−21i=1∑nj=1∑nλiλjyiyjxiTxj+i=1∑nλi
将原函数取负转化为求最小值,因此原问题转化为:
{ m i n λ 1 2 ∑ i = 1 n ∑ j = 1 n λ i λ j y i y j x i T x j − ∑ i = 1 n λ i s t . λ i ≥ 0 s t . ∑ i = 1 n λ i y i = 0 \begin{cases} \underset{\lambda}{min}\ \frac{1}{2}\overset{n}{\underset{i=1}{\sum}}\overset{n}{\underset{j=1}{\sum}}\lambda_i \lambda_jy_iy_jx_i^Tx_j-\overset{n}{\underset{i=1}{\sum}}\lambda_i \\ st.\ \lambda_i\ge0 \\ st.\ \overset{n}{\underset{i=1}{\sum}} \lambda_iy_i=0 \end{cases} ⎩ ⎨ ⎧λmin 21i=1∑nj=1∑nλiλjyiyjxiTxj−i=1∑nλist. λi≥0st. i=1∑nλiyi=0
这个问题的解法将在4.3部分介绍。
2 Soft margin
当数据集不可分,或者存在噪声的时候,hard margin效果不好。
soft:允许一点错误
原问题变成:
m i n w , b 1 2 w T w + l o s s \underset{w,b}{min}\ \frac{1}{2}w^Tw +loss w,bmin 21wTw+loss
2.1 loss的选择
a. 错误个数
缺点:不连续
b. 距离(hinge loss)
l o s s i = m a x { 0 , 1 − y i ( w T x i + b ) } loss_i = max\{0,1-y_i(w^Tx_i+b)\} lossi=max{0,1−yi(wTxi+b)}
令 ξ i = 1 − y i ( w T x i + b ) \xi_i=1-y_i(w^Tx_i+b) ξi=1−yi(wTxi+b),即 ξ i \xi_i ξi代表当数据不在约束范围内,该数据点到约束边界的距离,因此有 ξ i ≥ 0 \xi_i\ge0 ξi≥0。如图:

则原问题变为:
{ m i n w , b 1 2 w T w + C ∑ i = 1 n ξ i s t . y i ( w T x i + b ) ≥ 1 − ξ i for i= 1,...n \begin{cases} \underset{w,b}{min}\ \frac{1}{2}w^Tw+C\overset{n}{\underset{i=1}{\sum}}\xi_i \\ st.\ y_i(w^Tx_i+b)\ge1-\xi_i \quad \text{for i= 1,...n} \end{cases} ⎩ ⎨ ⎧w,bmin 21wTw+Ci=1∑nξist. yi(wTxi+b)≥1−ξifor i= 1,...n
3. 对偶问题(dual problem)
这一节属于知识补充,不想看可以跳过。
在1.2中涉及到了对偶问题:
m i n w , b m a x λ L ( w , b , λ ) → m a x λ m i n w , b L ( w , b , λ ) \underset{w,b}{min}\ \underset{\lambda}{max}\ L(w,b,\lambda) \rightarrow \underset{\lambda}{max}\ \underset{w,b}{min}\ L(w,b,\lambda) w,bmin λmax L(w,b,λ)→λmax w,bmin L(w,b,λ)
在没有其他条件的情况下(未说明是凸二次优化问题),该对偶问题与原问题是弱对偶关系,满足:
m i n w , b m a x λ L ( w , b , λ ) ≥ m a x λ m i n w , b L ( w , b , λ ) \underset{w,b}{min}\ \underset{\lambda}{max}\ L(w,b,\lambda) \ge \underset{\lambda}{max}\ \underset{w,b}{min}\ L(w,b,\lambda) w,bmin λmax L(w,b,λ)≥λmax w,bmin L(w,b,λ)
如果是强对偶关系,则满足:
m i n w , b m a x λ L ( w , b , λ ) = m a x λ m i n w , b L ( w , b , λ ) \underset{w,b}{min}\ \underset{\lambda}{max}\ L(w,b,\lambda) =\underset{\lambda}{max}\ \underset{w,b}{min}\ L(w,b,\lambda) w,bmin λmax L(w,b,λ)=λmax w,bmin L(w,b,λ)
3.1 公式证明(弱对偶关系):
先考虑里层函数,无论将谁作为自变量,都满足最大值大于函数本身大于最小值:
m a x λ L ( w , b , λ ) ≥ L ( w , b , λ ) ≥ m i n w , b L ( w , b , λ ) \underset{\lambda}{max}\ L(w,b,\lambda)\ge L(w,b,\lambda) \ge \underset{w,b}{min}\ L(w,b,\lambda) λmax L(w,b,λ)≥L(w,b,λ)≥w,bmin L(w,b,λ)
由于 m a x λ L ( w , b , λ ) \underset{\lambda}{max}\ L(w,b,\lambda) λmax L(w,b,λ)已经选择了符合条件的 λ \lambda λ,因此该函数变为w和b的函数,因此可以令 m a x λ L ( w , b , λ ) = A ( w , b ) \underset{\lambda}{max}\ L(w,b,\lambda) = A(w,b) λmax L(w,b,λ)=A(w,b)。同理,令 m i n w , b L ( w , b , λ ) = B ( λ ) \underset{w,b}{min}\ L(w,b,\lambda)=B(\lambda) w,bmin L(w,b,λ)=B(λ)。因此 A ( w , b ) ≥ B ( λ ) A(w,b)\ge B(\lambda) A(w,b)≥B(λ)。由于函数A整体大于等于函数B,因此 m i n w , b A ( w , b ) ≥ m a x λ B ( λ ) \underset{w,b}{min}A(w,b) \ge \underset{\lambda}{max}B(\lambda) w,bminA(w,b)≥λmaxB(λ)。即:
m i n w , b m a x λ L ( w , b , λ ) ≥ m a x λ m i n w , b L ( w , b , λ ) \underset{w,b}{min}\ \underset{\lambda}{max}\ L(w,b,\lambda) \ge \underset{\lambda}{max}\ \underset{w,b}{min}\ L(w,b,\lambda) w,bmin λmax L(w,b,λ)≥λmax w,bmin L(w,b,λ)
3.2 几何证明:
设原问题为:
{ m i n f ( x ) x ∈ R p s . t . m ( x ) ≤ 0 \begin{cases} min\ f(x)\quad x\in \mathbb{R^p} \\ s.t. \ m(x)\le0 \end{cases} {min f(x)x∈Rps.t. m(x)≤0
转化为Lagrange: L ( x , λ ) = f ( x ) + λ m ( x ) , λ ≥ 0 L(x,\lambda)=f(x)+\lambda m(x), \lambda\ge0 L(x,λ)=f(x)+λm(x),λ≥0
原始问题(primal problem): p ∗ = m i n f ( x ) p^*=min\ f(x) p∗=min f(x)
对偶问题(dual problem): d ∗ = m a x λ m i n x L ( x , λ ) d^*=\underset{\lambda}{max} \ \underset{x}{min}\ L(x,\lambda) d∗=λmax xmin L(x,λ)
为了简化,令u = m(x), t = f(x)。令G为(u,x)组成的二维坐标系的区域。为不失一般性,假设G为非凸区域。图示以及符号表示如下(inf为集合下确界,令 g ( λ ) = i n f { t + λ u ∣ ( u , t ) ∈ G } g(\lambda)=inf\{t+\lambda u|(u,t)\in G\} g(λ)=inf{t+λu∣(u,t)∈G}):
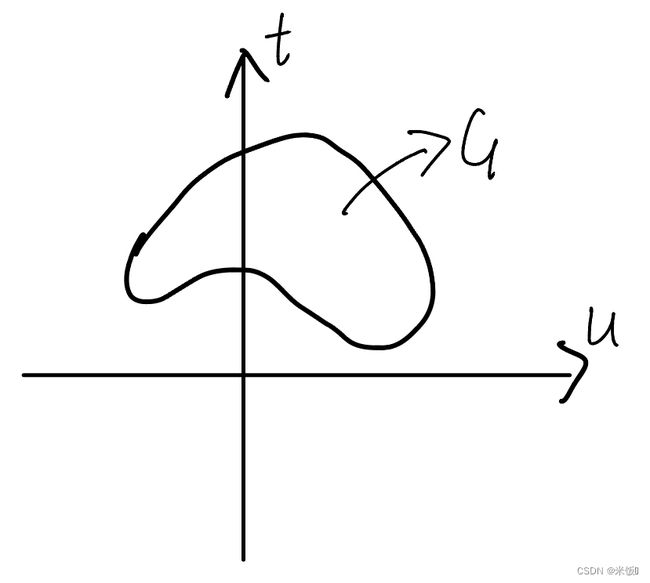
D = d o m f ∩ d o m m G = { ( m ( x ) , f ( x ) ) ∣ x ∈ D } = { ( u , t ) ∣ x ∈ D } p ∗ = m i n f ( x ) = i n f { t ∣ ( u , t ) ∈ G , u ≤ 0 } d ∗ = m a x λ m i n x f ( x ) + λ m ( x ) = m a x λ m i n x ( t + λ u ) = m a x λ i n f { t + λ u ∣ ( u , t ) ∈ G } = m a x λ g ( λ ) \begin{aligned} D &= dom\ f \cap dom\ m \\ &\\ G &= \{(m(x),f(x))|x\in D\}\\&= \{(u,t)|x\in D\}\\ &\\ p^* &= min\ f(x)\\ &=inf\{t|(u,t)\in G,u\le0\}\\ &\\ d^*&=\underset{\lambda}{max} \ \underset{x}{min}f(x)+\lambda m(x)\\ &=\underset{\lambda}{max}\ \underset{x}{min} (t+\lambda u)\\ &=\underset{\lambda}{max}\ inf\{t+\lambda u|(u,t)\in G\}\\ &=\underset{\lambda}{max}\ g(\lambda) \end{aligned}\\ DGp∗d∗=dom f∩dom m={(m(x),f(x))∣x∈D}={(u,t)∣x∈D}=min f(x)=inf{t∣(u,t)∈G,u≤0}=λmax xminf(x)+λm(x)=λmax xmin(t+λu)=λmax inf{t+λu∣(u,t)∈G}=λmax g(λ)
3.2.1 p*
p ∗ = i n f { t ∣ ( u , t ) ∈ G , u ≤ 0 } p^* =inf\{t|(u,t)\in G,u\le0\}\\ p∗=inf{t∣(u,t)∈G,u≤0}
u ≤ 0 u\le0 u≤0是区域G中u的负半轴部分,而最小值p*则如图中所示:

3.2.2 g ( λ ) g(\lambda) g(λ)
g ( λ ) = i n f { t + λ u ∣ ( u , t ) ∈ G } g(\lambda)=inf\{t+\lambda u|(u,t)\in G\} g(λ)=inf{t+λu∣(u,t)∈G}
t + λ u t+\lambda u t+λu代表的是一条截距不定的直线, λ \lambda λ是斜率,设截距为k,则该直线为 t = − λ u + k t=-\lambda u+k t=−λu+k。
这里以 λ > 0 \lambda>0 λ>0的情况为例, λ = 0 \lambda=0 λ=0时直线与u轴平行,道理相同。
由 λ > 0 \lambda>0 λ>0可知直线的斜率小于0。当 t + λ u = 0 t+\lambda u=0 t+λu=0时,该直线过原点,图中表示为绿线。符合条件的直线是由绿线平移得到的。图中两个蓝线分别与区域G相切,蓝线之间的所有斜率为 − λ -\lambda −λ的直线都是符合条件的直线,他们的截距k的最小值为 g ( λ ) g(\lambda) g(λ)。如下图所示:

3.2.3 d*
d ∗ = m a x λ g ( λ ) d^*=\underset{\lambda}{max}\ g(\lambda) d∗=λmax g(λ)
由3.2.2可知 g ( λ ) g(\lambda) g(λ)是直线 t + λ u t+\lambda u t+λu与区域G相切的直线截距最小值,要让这个最小值更大,就要不断调整斜率 − λ -\lambda −λ,使得直线能够上移更多。如图,直线与区域G切点更多的时候d*越大。
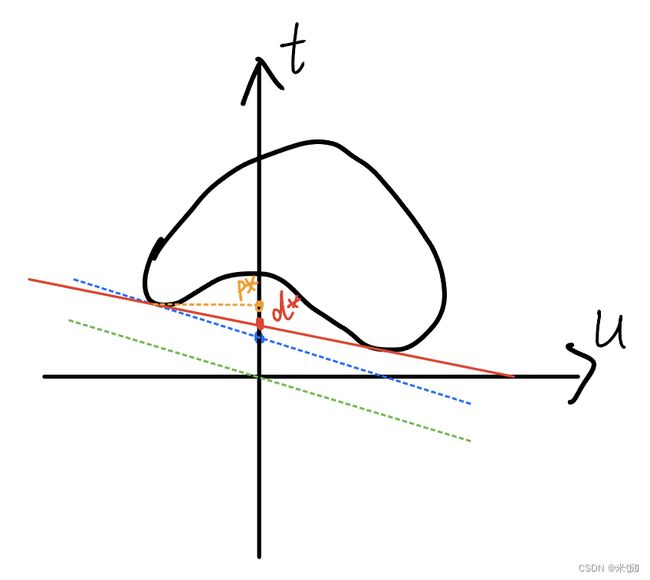
由此可知, d ∗ ≤ p ∗ d^*\le p^* d∗≤p∗(这个非凸区域的示例中 d ∗ < p ∗ d^*< p^* d∗<p∗。等号成立有多种情况,例如上图非凸部分满足斜率 λ = 0 \lambda=0 λ=0的直线为所求,或涉及的区域部分是凸函数)。
3.2.4 slater条件与强对偶
slater条件:
∃ x ^ ∈ r e l i n t D s . t . ∀ i = 1 , . . . n m i ( x ^ ) < 0 \exists \hat{x}\in relint\ D\quad s.t. \forall i=1,...n\quad m_i(\hat{x})<0 ∃x^∈relint Ds.t.∀i=1,...nmi(x^)<0
relint是relative interior相对内部,即不包括边界的区域。
这意味着区域G中至少有一个点是在t轴左侧的(u=m(x)<0),保证了p*的存在,且切线不与u轴垂直。
放松的slater条件:
n中有k个仿射函数,则只需验证另外n-k个约束是否满足slater条件。仿射函数形如 f ( x ) = A x + b f(x)=Ax+b f(x)=Ax+b,其中A是m*k的矩阵,x是k维向量,b是m维向量,本质上是一种k维到m维的映射关系。
凸优化,slater条件与强对偶的关系:
凸函数+slater条件 → \rightarrow →强对偶关系
(是充分条件,slater条件相当于是凸函数的一个约束,关系不可反推)
SVM中
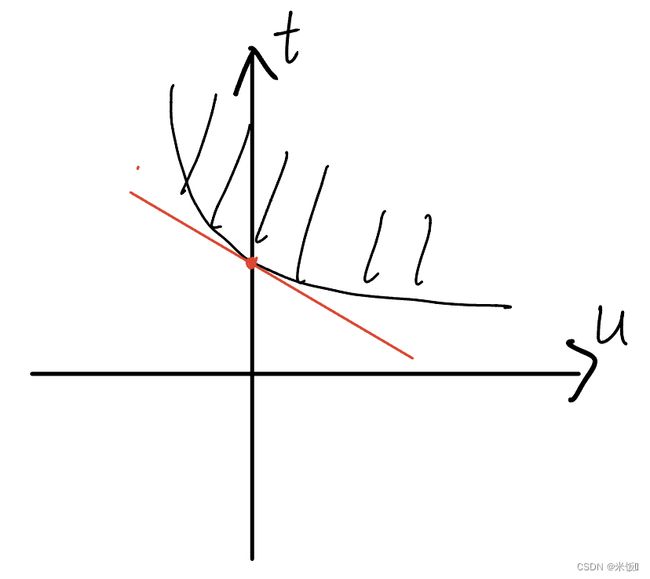
SVM是二次凸优化,如图 p ∗ = d ∗ p^*=d^* p∗=d∗,其约束条件是仿射函数满足slater条件,因此是强对偶关系,也就可以做如下转化求解:
{ m i n w , b 1 2 w T w s t . y i ( w T x i + b ) ≥ 1 → m i n w , b m a x λ L ( w , b , λ ) → m a x λ m i n w , b L ( w , b , λ ) \begin{cases} \underset{w,b}{min}\ \frac{1}{2}w^Tw \\ st.\ y_i(w^Tx_i+b)\ge1 \end{cases} \rightarrow \underset{w,b}{min}\ \underset{\lambda}{max}\ L(w,b,\lambda) \rightarrow \underset{\lambda}{max}\ \underset{w,b}{min}\ L(w,b,\lambda) ⎩ ⎨ ⎧w,bmin 21wTwst. yi(wTxi+b)≥1→w,bmin λmax L(w,b,λ)→λmax w,bmin L(w,b,λ)
3.2.5 总结与kkt条件的补充
以下内容来自链接:kkt条件






4 Kernel
4.1 背景
| 线性可分 | 有噪音 | 严格线性不可分 |
|---|---|---|
| PLA | Pocket Algorithm | MLP/神经网 |
| hard-margin SVM | soft-margin SVM | kernel |
优点:
- 非线性形成高维转换(模型分类角度)
- 对偶表示形成内积(优化计算角度)
4.1.1 非线性的高维转换(kernel method)
对线性不可分的情况做非线性转换 ϕ ( x ) \phi(x) ϕ(x),变成线性可分问题(映射到高维)
cover theorem: 高维比低维更易线性可分
如下分类问题(以异或问题为例):

使用的非线性转换如下(此处是二维到三维,转换方式不唯一,可以自己随意指定):
x = ( x 1 , x 2 ) → ϕ ( x ) x ′ = ( x 1 , x 2 , ( x 1 − x 2 ) 2 ) x=(x_1,x_2)\overset{\phi(x)}{\rightarrow}x'=(x_1,x_2,(x_1-x_2)^2) x=(x1,x2)→ϕ(x)x′=(x1,x2,(x1−x2)2)
分类平面如右图红色表示。
4.1.2 对偶形式的内积(kernel trick)
对于1.2.2中最终的原问题转化结果:
{ m i n λ 1 2 ∑ i = 1 n ∑ j = 1 n λ i λ j y i y j x i T x j − ∑ i = 1 n λ i s t . λ i ≥ 0 s t . ∑ i = 1 n λ i y i = 0 for all i = 1,...,n \begin{cases} \underset{\lambda}{min}\ \frac{1}{2}\overset{n}{\underset{i=1}{\sum}}\overset{n}{\underset{j=1}{\sum}}\lambda_i \lambda_jy_iy_jx_i^Tx_j-\overset{n}{\underset{i=1}{\sum}}\lambda_i \\ st.\ \lambda_i\ge0 \\ st.\ \overset{n}{\underset{i=1}{\sum}} \lambda_iy_i=0 \quad \text{for all i = 1,...,n } \end{cases} ⎩ ⎨ ⎧λmin 21i=1∑nj=1∑nλiλjyiyjxiTxj−i=1∑nλist. λi≥0st. i=1∑nλiyi=0for all i = 1,...,n
经过非线性变化以后可以得到:
{ m i n λ 1 2 ∑ i = 1 n ∑ j = 1 n λ i λ j y i y j ϕ ( x i ) T ϕ ( x j ) − ∑ i = 1 n λ i s t . λ i ≥ 0 s t . ∑ i = 1 n λ i y i = 0 for all i = 1,...,n \begin{cases} \underset{\lambda}{min}\ \frac{1}{2}\overset{n}{\underset{i=1}{\sum}}\overset{n}{\underset{j=1}{\sum}}\lambda_i \lambda_jy_iy_j\phi(x_i)^T\phi(x_j)-\overset{n}{\underset{i=1}{\sum}}\lambda_i \\ st.\ \lambda_i\ge0 \\ st.\ \overset{n}{\underset{i=1}{\sum}} \lambda_iy_i=0 \quad \text{for all i = 1,...,n } \end{cases} ⎩ ⎨ ⎧λmin 21i=1∑nj=1∑nλiλjyiyjϕ(xi)Tϕ(xj)−i=1∑nλist. λi≥0st. i=1∑nλiyi=0for all i = 1,...,n
其中 ϕ ( x i ) T ϕ ( x j ) \phi(x_i)^T\phi(x_j) ϕ(xi)Tϕ(xj)是一个内积的形式,单独求解 ϕ ( x i ) \phi(x_i) ϕ(xi)非常困难,其维度可能非常高。因此直接求解 ϕ ( x i ) T ϕ ( x j ) \phi(x_i)^T\phi(x_j) ϕ(xi)Tϕ(xj),此处用到了核方法(kernel function)。
4.2 Kernel function
4.2.1 定义
一般情况下,核函数指正定核函数。内积写法: < ϕ ( x ) , ϕ ( z ) > = ϕ ( x ) T ϕ ( z ) <\phi(x),\phi(z)>=\phi(x)^T\phi(z) <ϕ(x),ϕ(z)>=ϕ(x)Tϕ(z)
定义1
χ : input space , χ ⊆ R p k : χ ∗ χ → R ∀ x , z ∈ χ , 有 k ( x , z ) 如果 ∃ ϕ : x → R , ϕ ∈ H s . t . k ( x , z ) = < ϕ ( x ) , ϕ ( z ) > 那么称 k ( x , z ) 是正定核函数 \chi:\text{input\ space}, \chi \subseteq \mathbb{R^p} \\ k:\chi*\chi\rightarrow\mathbb{R}\\ \forall x,z\in \chi, 有k(x,z) \\ 如果\ \exist\ \phi:x \rightarrow \mathbb{R},\phi\in H \\ s.t.\ k(x,z) = <\phi(x),\phi(z)>\\ 那么称k(x,z)是正定核函数 χ:input space,χ⊆Rpk:χ∗χ→R∀x,z∈χ,有k(x,z)如果 ∃ ϕ:x→R,ϕ∈Hs.t. k(x,z)=<ϕ(x),ϕ(z)>那么称k(x,z)是正定核函数
其中 H H H代表Hilbert space,是一个完备的,可能是无限维的,被赋予内积的线性空间。 H H H中的元素都是函数。其中:
- 完备的:对极限是封闭的。对于 { K n } ⊂ H , l i m n → ∞ K n = k ∈ H \{K_n\}\subset H, \underset{n\rightarrow\infty}{lim}K_n=k\in H {Kn}⊂H,n→∞limKn=k∈H
- 内积( f , g ∈ H , r f,g\in H,r f,g∈H,r是标量):
对称性: < f , g > = < g , f >
正定性: < f , f > ≥ 0 , 当且仅当 f = 0 时等号成立
线性: < r 1 f 1 + r 2 f 2 , g > = r 1 < f 1 , g > + r 2 < f 2 , g > - 线性空间:向量空间,对加法和数乘运算封闭
定义2
χ : input space , χ ⊆ R p k : χ ∗ χ → R ∀ x , z ∈ χ , 有 k ( x , z ) 如果 k ( x , z ) 有如下两条性质: 1. 对称性 2. 正定性 那么称 k ( x , z ) 是正定核函数 \chi:\text{input\ space}, \chi \subseteq \mathbb{R^p} \\ k:\chi*\chi\rightarrow\mathbb{R}\\ \forall x,z\in \chi, 有k(x,z) \\ 如果k(x,z)有如下两条性质: \\ 1.对称性\\ 2.正定性\\ 那么称k(x,z)是正定核函数 χ:input space,χ⊆Rpk:χ∗χ→R∀x,z∈χ,有k(x,z)如果k(x,z)有如下两条性质:1.对称性2.正定性那么称k(x,z)是正定核函数
其中:
- 对称性: k ( x , z ) = k ( z , x ) k(x,z)=k(z,x) k(x,z)=k(z,x)
- 正定性:任取n个元素 x 1 . . . x n ∈ χ x_1...x_n\in \chi x1...xn∈χ,对应的Gram matrix是半正定的。(Gram matrix: K = [ k ( x i , x j ) ] n ∗ n K=[k(x_i,x_j)]_{n*n} K=[k(xi,xj)]n∗n)
定义1与定义2等价
也就是:正定核 ⇔ \Leftrightarrow ⇔对称,Gram矩阵半正定
后续证明不想看可以跳过。
必要性证明:
已知 k ( x , z ) = < ϕ ( x ) , ϕ ( z ) > , 证: k ( x , z ) 对称,且 G r a m m a t r i x 半正定 已知k(x,z)=<\phi(x),\phi(z)>,证:k(x,z)对称,且Gram matrix半正定 已知k(x,z)=<ϕ(x),ϕ(z)>,证:k(x,z)对称,且Grammatrix半正定
对称性:
∵ k ( x , z ) = < ϕ ( x ) , ϕ ( z ) > k ( z , x ) = < ϕ ( z ) , ϕ ( x ) > H 有内积的对称性,即 < ϕ ( x ) , ϕ ( z ) > = < ϕ ( z ) , ϕ ( x ) > ∴ k ( x , z ) = k ( z , x ) k ( x , z ) 满足对称性 \begin{aligned} \because &k(x,z)=<\phi(x),\phi(z)>\\ & k(z,x)=<\phi(z),\phi(x)>\\ &H有内积的对称性,即<\phi(x),\phi(z)>=<\phi(z),\phi(x)>\\ \therefore &k(x,z)=k(z,x)\\ &k(x,z)满足对称性 \end{aligned} ∵∴k(x,z)=<ϕ(x),ϕ(z)>k(z,x)=<ϕ(z),ϕ(x)>H有内积的对称性,即<ϕ(x),ϕ(z)>=<ϕ(z),ϕ(x)>k(x,z)=k(z,x)k(x,z)满足对称性
Gram matrix半正定:
相关概念:
G r a m m a t r i x :任取 n 个元素 x 1 . . . x n ∈ χ , K = [ k ( x i , x j ) ] n ∗ n A n ∗ n 半正定: { 特征值 λ ≥ 0 ∀ u ∈ R p , u T A u ≥ 0 Gram\ matrix:任取n个元素x_1...x_n\in \chi,\ K=[k(x_i,x_j)]_{n*n}\\ A_{n*n}半正定: \begin{cases} 特征值\lambda \ge0 \\ \forall u \in \mathbb{R^p}, u^TAu\ge 0 \end{cases} Gram matrix:任取n个元素x1...xn∈χ, K=[k(xi,xj)]n∗nAn∗n半正定:{特征值λ≥0∀u∈Rp,uTAu≥0
因此即证: ∀ u ∈ R p , u T K u ≥ 0 \forall u \in \mathbb{R^p}, u^TKu\ge 0 ∀u∈Rp,uTKu≥0
u T K u = ( u 1 , u 2 , . . . u n ) ( K 11 K 12 ⋯ K 1 n K 21 K 22 ⋯ K 2 n ⋮ ⋮ ⋱ ⋮ K n 1 K n 2 ⋯ K n n ) ( u 1 u 2 ⋮ u n ) = ∑ i = 1 n ∑ j = 1 n u i u j K i j 其中 K i j = k ( x i , x j ) = ∑ i = 1 n ∑ j = 1 n u i u j < ϕ ( x i ) , ϕ ( x j ) > = [ ∑ i = 1 n u i ϕ ( x i ) ] T ∑ j = 1 n u j ϕ ( x j ) = ∣ ∣ ∑ i = 1 n u i ϕ ( x i ) ∣ ∣ 2 ≥ 0 \begin{aligned} u^TKu&=(u_1,u_2,...u_n) \begin{pmatrix} K_{11} & K_{12} & \cdots & K_{1n} \\ K_{21} & K_{22} & \cdots & K_{2n} \\ \vdots & \vdots & \ddots & \vdots \\ K_{n1} & K_{n2} & \cdots & K_{nn} \\ \end{pmatrix} \begin{pmatrix} u_1 \\ u_2 \\ \vdots \\ u_n \end{pmatrix}\\ &=\overset{n}{\underset{i=1}{\sum}}\overset{n}{\underset{j=1}{\sum}}u_iu_jK_{ij}\quad 其中K_{ij}=k(x_i,x_j)\\ &=\overset{n}{\underset{i=1}{\sum}}\overset{n}{\underset{j=1}{\sum}}u_iu_j<\phi(x_i),\phi(x_j)>\\ &=[\overset{n}{\underset{i=1}{\sum}}u_i\phi(x_i)]^T\overset{n}{\underset{j=1}{\sum}}u_j\phi(x_j)\\ &=||\overset{n}{\underset{i=1}{\sum}}u_i\phi(x_i)||^2 \ge 0 \end{aligned}\\ uTKu=(u1,u2,...un)⎝ ⎛K11K21⋮Kn1K12K22⋮Kn2⋯⋯⋱⋯K1nK2n⋮Knn⎠ ⎞⎝ ⎛u1u2⋮un⎠ ⎞=i=1∑nj=1∑nuiujKij其中Kij=k(xi,xj)=i=1∑nj=1∑nuiuj<ϕ(xi),ϕ(xj)>=[i=1∑nuiϕ(xi)]Tj=1∑nujϕ(xj)=∣∣i=1∑nuiϕ(xi)∣∣2≥0
∴ K 是半正定的 \therefore K是半正定的 ∴K是半正定的
4.3 SVM Kernel
引入核函数后,原问题变成了:(soft)
{ m i n λ 1 2 ∑ i = 1 n ∑ j = 1 n λ i λ j y i y j k ( x i , x j ) − ∑ i = 1 n λ i s t . C ≥ λ i ≥ 0 s t . ∑ i = 1 n λ i y i = 0 for all i = 1,...,n w ∗ = ∑ i = 1 n λ i y i ϕ ( x i ) b ∗ = 1 s ∑ k = 1 s [ y k − ∑ i = 1 n λ i y i k ( x i , x k ) ] 其中 s 为支持向量个数 超平面为 ∑ i = 1 n a i ∗ y i k ( x , x i ) + b ∗ = 0 分类决策函数为 s i g n ( ∑ i = 1 n a i ∗ y i k ( x , x i ) + b ∗ ) \begin{cases} \underset{\lambda}{min}\ \frac{1}{2}\overset{n}{\underset{i=1}{\sum}}\overset{n}{\underset{j=1}{\sum}}\lambda_i \lambda_jy_iy_jk(x_i,x_j)-\overset{n}{\underset{i=1}{\sum}}\lambda_i \\ st.\ C\ge \lambda_i\ge0 \\ st.\ \overset{n}{\underset{i=1}{\sum}} \lambda_iy_i=0 \quad \text{for all i = 1,...,n } \end{cases}\\ w^*=\overset{n}{\underset{i=1}{\sum}}\lambda_i y_i \phi(x_i)\\ b^* = \frac{1}{s}\overset{s}{\underset{k=1}{\sum}}[y_k-\overset{n}{\underset{i=1}{\sum}}\lambda_i y_i k(x_i,x_k)]\\ 其中s为支持向量个数\\ 超平面为\overset{n}{\underset{i=1}{\sum}}a_i^*y_ik(x,x_i)+b*=0\\ 分类决策函数为sign(\overset{n}{\underset{i=1}{\sum}}a_i^*y_ik(x,x_i)+b*) ⎩ ⎨ ⎧λmin 21i=1∑nj=1∑nλiλjyiyjk(xi,xj)−i=1∑nλist. C≥λi≥0st. i=1∑nλiyi=0for all i = 1,...,n w∗=i=1∑nλiyiϕ(xi)b∗=s1k=1∑s[yk−i=1∑nλiyik(xi,xk)]其中s为支持向量个数超平面为i=1∑nai∗yik(x,xi)+b∗=0分类决策函数为sign(i=1∑nai∗yik(x,xi)+b∗)
scikit-learn中包括如下核函数:( γ , r , d \gamma,r,d γ,r,d都需要自己调参)
- 线性核函数linear
K ( x , z ) = x ∙ z K(x,z)=x\bullet z K(x,z)=x∙z - 多项式核函数poly
K ( x , z ) = ( γ x ∙ z + r ) d K(x,z)=(\gamma x\bullet z+r)^d K(x,z)=(γx∙z+r)d - 高斯核函数rbf
K ( x , z ) = e x p ( − γ ∣ ∣ x − z ∣ ∣ 2 ) K(x,z)=exp(-\gamma||x-z||^2) K(x,z)=exp(−γ∣∣x−z∣∣2) - sigmoid
K ( x , z ) = t a n h ( γ x ∙ z + r ) K(x,z)=tanh(\gamma x\bullet z+r) K(x,z)=tanh(γx∙z+r)
剩下问题是如何求出 λ \lambda λ,通过SMO算法。
全部内容也可参见:SVM