EMR-StarRocks 与 Flink 在汇量实时写入场景的最佳实践
作者:
刘腾飞 汇量后端开发工程师
阿里云开源OLAP研发团队
EMR-StarRocks介绍
阿里云EMR在年初推出了StarRocks服务,StarRocks是新一代极速全场景MPP(Massively Parallel Processing)数据仓库,致力于构建极速和统一分析体验。EMR StarRocks具备如下特点:
- 兼容MySQL协议,可使用MySQL客户端和常用BI工具对接StarRocks来分析数据
- 采用分布式架构:
- 对数据表进行水平划分并以多副本存储
- 集群规模可以灵活伸缩,支持10 PB级别的数据分析
- 支持MPP框架,并行加速计算
- 支持多副本,具有弹性容错能力
- 支持向量化引擎和CBO
- 支持弹性扩缩容
- 支持明细模型、聚合模型、主键模型和更新模型
更多详细信息可以参考https://help.aliyun.com/document_detail/405463.html
Flink-CDC概念介绍

CDC的全称是Change Data Capture,面向的场景包括数据同步、数据分发、数据采集,Flink CDC 主要面向数据库的变更,可以将上游数据和Schema的变更同步到下游数据湖和数据仓库中。2020年7月,Flink CDC项目提交了第一个Commit,去年8月,Flink社区发布了CDC2.0,经过两年时间的打磨,在商业化使用上已经非常成熟。本文主要以Mysql CDC为例,介绍StarRocks+Flink CDC实时入仓中用户遇到的痛点,以及在Flink和StarRocks层面进行的对应优化和解决方案。
使用CDC将一张Mysql表中的数据导入到StarRocks的表中,首先需要在StarRocks上建立用来承接Mysql数据的目标表,然后在Flink上分别创建Mysql表和StarRocks表在Flink中Sink和Source表的映射,然后执行一条insert into sink_table from source_table语句。执行完Insert into之后,会生成一个CDC任务,CDC任务首先向目标表同步源表的全量数据,完成后继续基于Binlog进行增量数据的同步。通过一个任务,完成数据的全量+增量同步,对于用户来讲是非常友好的。但是在使用的过程中,依然发现了一些痛点。
实时写入场景的用户痛点
SQL开发工作量大
对于一些还没有完成数仓建设的新业务,或是刚刚开始依托StarRocks进行OLAP平台建设的用户而言,在StarRocks中建表以承载Mysql同步过来的数据是第一步。在一些复杂的业务中,Mysql中的表往往有几十上百张,每张表又有数十个字段,要把它们对应的StarRocks表的建表语句全部编写出来是一个很大的工作量。第一个痛点StarRocks建表的工作量大。
Flink字段的数据类型映射关系复杂易错
在StarRocks中建表是第一步,建表完成之后,为了启动CDC任务,还需要在Flink中建立Mysql对应的Source表,以及StarRocks对应的Sink表,其中Flink建表时,每个字段的字段类型与Mysql、与StarRocks的映射关系需要严格注意,对于动辄几十上百个需要字段的表,每个字段都需要查找对应在Flink的类型映射关系,尤其令开发人员痛苦。因此,第二个痛点是上下游表与Flink字段的数据类型映射关系复杂,容易出错。
Schema变更操作繁琐
第三个痛点来自于业务数据Schema的变化,据Fivetran公司调查,约有60%的公司数据Schema每个月都会发生变化,30%的公司数据Schema每周都会发生变化。对于Mysql表中字段的增删改,用户希望在不影响CDC任务的情况下,将Schema变化同步到下游的StarRocks。目前常用的方案,是在手动停止任务后,更改StarRocks和Mysql的Schema,更改Flink侧的Sink和Source表结构,通过指定savepoints的方式再次启动任务。Schema变更的操作繁琐,无法自动化是第三个痛点。
数据同步任务占用资源多
第四个痛点,是在表的数量多、实时增量数据量大的场景下,CDC任务占用的内存和cpu资源较高,出于节省成本的考虑,用户希望尽可能的在资源利用方面进行优化。
接下来,我们来看针对这些痛点,EMR-StarRocks在与Flink深度结合方面做了哪些优化,提供了什么样的解决方案。
CTAS&CDAS
EMR-StarRocks与Flink团队推出的CTAS&CDAS功能主要是针对前三个痛点研发的一个解决方案。通过CTAS&CDAS,可以使用一条SQL语句,完成StarRocks建表、Flink-CDC任务创建、实时同步Schema变更等原本需要多项繁杂操作的任务,令开发和运维的工作量大大降低。
CTAS介绍
CTAS的全称是create table as,语法结构如下:
CREATE TABLE IF NOT EXISTS runoob_tbl1 with (
'starrocks.create.table.properties'=' engine = olap primary key(runoob_id) distributed by hash(runoob_id ) buckets 8',
'database-name'='test_cdc',
'jdbc-url'='jdbc:mysql://172.16.**.**:9030',
'load-url'='172.16.**.**:8030',
'table-name'='runoob_tbl_sr',
'username'='test',
'password' = '123456',
'sink.buffer-flush.interval-ms' = '5000'
)
as table mysql.test_cdc.runoob_tbl /*+ OPTIONS ( 'connector' = 'mysql-cdc',
'hostname' = 'rm-2zepd6e20u3od****.mysql.rds.aliyuncs.com',
'port' = '3306',
'username' = 'test',
'password' = '123456',
'database-name' = 'test_cdc',
'table-name' = 'runoob_tbl' )*/;
通过CTAS的语法结构可以看到,除了集群信息和DataBase信息外,还有一个特殊配置“starrocks.create.table.properties”,这是由于Mysql与StarRocks的表结构有一些不同,如Key Type、分区、Bucket Number等特殊配置,因此用它来承接StarRocks建表语句中字段定义后面的内容。
为了方便用户更快的建表,还设置了一个Simple Mode,配置方式如下:
CREATE TABLE IF NOT EXISTS runoob_tbl1 with (
'starrocks.create.table.properties'=' buckets 8',
'starrocks.create.table.mode'='simple',
'database-name'='test_cdc',
'jdbc-url'='jdbc:mysql://172.16.**.**:9030',
'load-url'='172.16.**.**:8030',
'table-name'='runoob_tbl_sr',
'username'='test',
'password' = '123456',
'sink.buffer-flush.interval-ms' = '5000'
)
as table mysql.test_cdc.runoob_tbl /*+ OPTIONS ( 'connector' = 'mysql-cdc',
'hostname' = 'rm-2zepd6e20u3od****.mysql.rds.aliyuncs.com',
'port' = '3306',
'username' = 'test',
'password' = '123456',
'database-name' = 'test_cdc',
'table-name' = 'runoob_tbl' )*/;
开启Simple Mode之后,将默认使用Primary Key模型,默认使用Mysql中的主键作为Primary Key,默认使用哈希(主键)进行分桶,这样,用户在启动Simple Mode对表使用CTAS语句时,就完全不需要关心Mysql中原表有哪些字段,字段名称是什么,主键是什么,只需要知道表名,就可以高效的完成SQL编写。
CTAS的原理
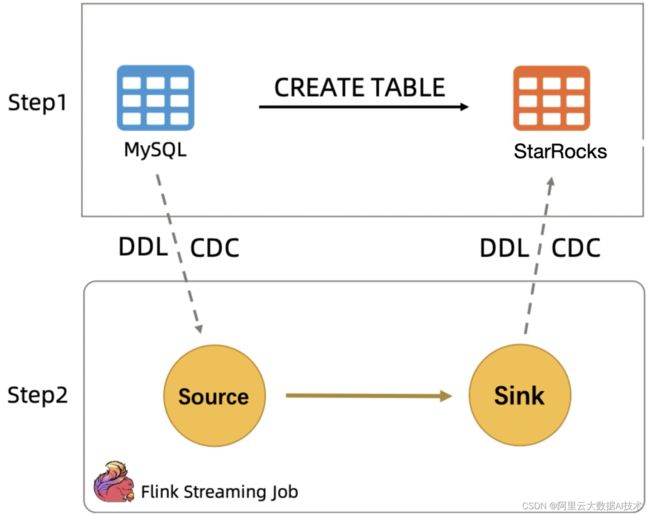
如图所示,在执行了CTAS语句后,首先Flink会自动在StarRocks中创建一个与Mysql源表的Schema相同的目标表,然后建立Mysql与StarRocks表在Flink中的Sink和Source映射,接下来启动一个CDC任务,该任务将同步源表数据到目标表,并在运行时监测Mysql源表发送过来的数据发生的Schema变更,自动将Schema变更同步到StarRocks目标表中。CTAS功能实际上是用一个SQL,完成了原本需要手动编写SQL和执行的多项操作。
接下来介绍CTAS的实现原理。CTAS的实现主要依赖了Flink CDC、Flink Catalog和Schema Evolution。Flink的CDC功能前面已经介绍过了。其中的Catalog功能,使Flink可以感知到StarRocks中所有的DataBase和所有table的Schema,并对它们进行DDL操作。而Schema Evolution功能,是通过对数据的Schema变化进行检测和记录实现的,例如,当Mysql发生增列操作时,CTAS任务并不会根据Mysql的DDL变化,立刻对下游StarRocks进行添加列的操作,而是当第一条使用了新Schema的数据被处理时,才会通过对比新旧数据Schema的区别,生成对应的Alter Table Add Column语句,对StarRocks进行增列操作,在等待StarRocks的Schema变更完成之后,新的数据才会被推送到下游。
CDAS介绍
CDAS是CTAS的一个语法糖。通过CDAS语句,可以实现Mysql中的整库同步,即生成一个Flink Job,Source是Mysql中的database,目标表是StarRocks中对应的多张表。
CREATE DATABASE IF NOT EXISTS sr_db with (
'starrocks.create.table.properties'=' buckets 8',
'starrocks.create.table.mode'='simple',
'database-name'='test_cdc',
'jdbc-url'='jdbc:mysql://172.16.**.**:9030',
'load-url'='172.16.**.**:8030',
'username'='test',
'password' = '123456',
'sink.buffer-flush.interval-ms' = '5000'
)
as table mysql.test_cdc.runoob_tbl including table
'tabl1','tbl2','tbl3' /*+ OPTIONS ( 'connector' = 'mysql-cdc',
'hostname' = 'rm-2zepd6e20u3od****.mysql.rds.aliyuncs.com',
'port' = '3306',
'username' = 'test',
'password' = '123456',
'database-name' = 'test_cdc' )*/;
由于我们期望使用一条SQL生成多张表的Schema和CDC任务,因此需要统一使用Simple模式。在实际使用过程中,一个DataBase中可能有些表不需要同步、有些表需要自定义配置,因此我们可以使用Including Table语法,只选择一个DataBase中的部分表进行CDAS操作,对于需要自定义属性配置的表,则使用CTAS语句进行操作。
重要特性
CTAS&CDAS的几个重要特性包括:
- 支持将多个CDC任务使用同一个Job执行,节省了大量的内存和CPU资源。
- 支持Source合并,在使用CDAS进行数据同步时,会使用一个Job管理所有表的同步任务,并自动将所有表的Source合并为一个,减少Mysql侧并发读取的压力。
- 支持的Schema Change类型包括增加列、删除列和修改列名。这里需要注意的是,当前所支持的删除列操作,是通过将对应字段的值置空来实现的,例如上游Mysql表删除了一个字段,在Flink检测到数据Schema变更后,并不会将StarRocks中对应的列删除,而是在将数据写入到StarRocks时,把对应的字段的值填为空值。而修改列名的操作,也是通过增加一个新列,并把新数据中原来的列的值置空来实现的。
Connector-V2介绍
Connector-V2是为了解决第四个痛点而研发的,可以帮助用户降低通过Flink导入StarRocks时的内存消耗,提升任务的稳定性。

如图所示,在V1版本中,为了保证Exactly-Once,我们需要将一次Checkpoint期间的所有数据都憋在Flink的Sink算子的内存中,由于Checkpoint时间不能设置的太短,且无法预测单位时间内数据的流量,因此不仅造成了内存资源的严重消耗,还经常因OOM带来稳定性问题。
V2版本通过两阶段提交的特性解决了这个问题,两阶段提交指的是,数据的提交分为两个阶段,第一阶段提交数据写入任务,在数据写入阶段数据都是不可见的,并且可以分批多次写入,第二阶段是提交阶段,通过Commit请求将之前多批次写入的数据同时置为可见。StarRocks侧提供了Begin、Prepare、Commit等接口,支持将多次数据写入请求作为同一个事务提交,保证了同一事务内数据的一致性。
通过显示的调用Transaction接口的方式,可以由原来在Flink侧积攒大批数据、一次性发送数据的方式,改进为连续小批量提交数据,在保证Exactly-Once的同时,大大降低了Flink侧用于存储数据Buffer的内存消耗问题,也提高了Flink任务的稳定性。
StarRocks + Flink在汇量的实践
在汇量的广告投放分析业务中,使用了CDAS特性来完成Mysql到Flink数据的实时变更。

此前,该业务主要依托某闭源数据仓库进行OLAP分析,随着数据量的增长,在单表查询和多表Join场景都出现了较大的瓶颈,查询耗时达到无法容忍的分钟级,因此重新选型采用了StarRocks进行数据分析,在对应场景下表现十分优异。
在汇量的业务场景下,StarRocks中有几十张涉及操作元数据的小表是使用CDAS进行实时同步的,另外几张数据量较大的明细表是以离线导入的形式按天更新的。使用CDAS的主要是数据更新和Schema变化较为频繁的小表和维度表,进行业务查询时,将这些实时更新的表与离线的数据表进行Join,通过小表实时更新、大表离线更新、大小表联合查询的方式,实现了实时性、成本以及导入与查询性能的取舍均衡。由于业务对数据的准确性要求较高,因此使用了Exactly-once语义,通过Flink的Checkpoint机制来保证数据的不丢不重。