对于SEMI-SUPERVISED CLASSIFICATION WITH GRAPH CONVOLUTIONAL NETWORKS的理解
SEMI-SUPERVISED CLASSIFICATION WITH GRAPH CONVOLUTIONAL NETWORKS的理解笔记总结
文章目录
- SEMI-SUPERVISED CLASSIFICATION WITH GRAPH CONVOLUTIONAL NETWORKS的理解笔记总结
-
- 前言
- 必备知识: GCN(Graph Convolutional network)
- 对于卷积核gθ的定义
- 关于论文的2 (FAST APPROXIMATE CONVOLUTIONAS ON GRAPHS)
- 关于论文的2.1(SPECTRAL GRAPH CONVOLUTIONS)
- 关于论文2.2(lAYER-WISE LINEAR MODEL)
- 关于论文3.1(EXAMPLE)
- 部分代码
- Reference
前言
在学习semi-supervised classification with graph convolutional networks之前,我认真的查阅了关于GCN(Graph Convolutional Networks)的知识,并且认为很有必要(对于像我这种小白,去先了解清楚关于GCN的知识),这篇论文是基于前人的研究结果提出的新的方法。
因为是从零开始学,对于理解有误的地方欢迎大家指正!
必备知识: GCN(Graph Convolutional network)
intro:
现在我们的现实生活中有大量的一些数据集:social networks, knowledge graphs, protein-interaction networks, the World Wide Web。它们的结构是Non Euclidean Structure的,是一种拓扑图。
而传统的CNN并不能有效的解决对这种数据类型的有效的特征提取,因为拓扑图(如下)中每个节点的响铃节点的数目不确定,无法进行同一个卷积核对数据特征提取的时候保持平移不变性,因此提出了GCN。

GCN的核心思想就是在一个graph上定义一个关于graph 的卷积操作,实现这一过程需要借助图的拉普拉斯矩阵。
详细参照如何理解GCN(此链接详细推导介绍了Graph卷积公式的推导过程)
需要重点掌握卷积的定义,拉普拉斯矩阵的定义和特点,图的傅里叶变化
总结:GCN的目的是在拓扑图上定义一个卷积操作,不同于CNN,它利用了图的拉普拉斯矩阵,
(为啥要用拉普拉斯矩阵? 因为经过一系列的变换,拓扑图中所有节点的特征都可以被该图的拉普拉斯矩阵的特征向量的线性组合所表示)得到GCN卷积的最终公式(这也是论文中所基于的一个基本思想):

其中X为图的节点的特征提取构成的向量(相当于是图的一个节点信息的输入);U是图的拉普拉斯矩阵的特征向量组成的矩阵;gθ为卷积核;σ()是激活函数
对于卷积核gθ的定义
上诉公式推导出来以后,由于U和x,σ()都是确定的因素,因此就需要定义卷积核。
-
第一代GCN采用的方法是将gθ定义成如下:

其中的θ有n个(也就是和图的节点数相同),是通过初始化赋值,然后进行误差的反向传播进行调整。
缺点:当n的值很大的时候(也就是说对大规模的图来说),整个公式的计算量会很大 -
第二代GCN采用的方法是将卷积核定义成如下:
α是任意的参数,通过初始化赋值然后利用误差反向传播进行调整
其中的K表示从图中任意一个中心节点到任意一阶走的step的数目,K远远小于N,如图:

单独看gθ似乎并没有简化计算,但是把gθ带入GCN的卷积公式中,可以发现,GCN的卷积可以简化为:

此算式只需要计算K次求和,计算量大大减少.
关于论文的2 (FAST APPROXIMATE CONVOLUTIONAS ON GRAPHS)
本篇论文提出了一个核心思想,即一个关于GCN的propagation rule:

因为邻接矩阵A只包含了一个节点相邻的节点的信息,丧失了节点本身的信息,因此作者加上一个单位矩阵,相当于补充了该节点的信息。
同时D(节点的度矩阵)同样的加上节点自身的信息,重新计算了一个度矩阵。
L表示第L层,W是第L层的权值参数,H表示某一层的输出。
整个等式可以理解为L+1层 =( L层的权值 * L层的输出 * 一个拉普拉斯矩阵)的激活
关于论文的2.1(SPECTRAL GRAPH CONVOLUTIONS)
论文的SPECTRAL GRAPH CONVOLUTIONS部分提到 了前人的研究,本文的思想是基于前人关于GCN卷积计算
![]()
此公式也就是GCN上的卷积操作,和上面的介绍的公式一样,其中x为图片节点的输入信息。只是在此论文中,作者提到了另外一种对于卷积核gθ的假设,即利用了
切比雪夫多项式(Tk(x)=2xTk−1(x)−Tk−2(x)Tk(x)=2xTk−1(x)−Tk−2(x)
当令k为0,1时:
T0(x)=1T0(x)=1
T1(x)=xT1(x)=x),
将gθ设置为如下所示的表达:
当把这个带入上面的卷积公式中,可以化简为(怎么化简得来的我也没有深究):
这里的K的定义同第二代GCN中卷积核中K的定义相同,同样的简化了计算。
具体参数的含义,参考论文,值得注意的是,此算式中没有了U(拉普拉斯矩阵特征向量构成的矩阵,需要将拉普拉斯矩阵分解得到),而是直接乘以拉普拉斯矩阵,也从这一方面简化了计算。
关于论文2.2(lAYER-WISE LINEAR MODEL)
详细推导参考https://blog.csdn.net/qq_41727666/article/details/84640549
当我们假设k=1时,可以将2.1中得到的等式化简为

令参数θ=θ0=-θ1,得到卷积公式如下:
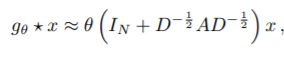
其中括号的部分可以理解为在临界矩阵A和度矩阵D上加上了节点自身的信息,因此可以转换为:
![]()
其中θ是一个参数矩阵,X为图片节点输入信息(关于节点特征提取向量组成的矩阵),而剩下的部分则是一个拉普拉斯矩阵。Z表示卷积后的图片信息。
这个公式是整个论文的核心,因此向前传播模型propogation rule可以直接在每一层用此公式计算,再使用激活函数激活
关于论文3.1(EXAMPLE)
当我们考虑一个只有两层的GCN进行半监督分类,那么也就是下列式子所代表的计算过程。其中W的权重更新通过计算交叉熵再梯度下降去检验更新。

部分代码
完整代码参考pytorch实现
数据集的加载和处理
def load_data(path="../data/cora/", dataset="cora"):
"""Load citation network dataset (cora only for now)"""
print('Loading {} dataset...'.format(dataset))
idx_features_labels = np.genfromtxt("{}{}.content".format(path, dataset),
dtype=np.dtype(str))
features = sp.csr_matrix(idx_features_labels[:, 1:-1], dtype=np.float32)
labels = encode_onehot(idx_features_labels[:, -1])
# build graph
idx = np.array(idx_features_labels[:, 0], dtype=np.int32)
idx_map = {j: i for i, j in enumerate(idx)}
edges_unordered = np.genfromtxt("{}{}.cites".format(path, dataset),
dtype=np.int32)
edges = np.array(list(map(idx_map.get, edges_unordered.flatten())),
dtype=np.int32).reshape(edges_unordered.shape)
adj = sp.coo_matrix((np.ones(edges.shape[0]), (edges[:, 0], edges[:, 1])),
shape=(labels.shape[0], labels.shape[0]),
dtype=np.float32)
# build symmetric adjacency matrix
adj = adj + adj.T.multiply(adj.T > adj) - adj.multiply(adj.T > adj)
# features = normalize(features)
# features = preprocessing.normalize(features, norm='l2', axis=0)
adj = normalize(adj + sp.eye(adj.shape[0]))
idx_train = range(140)
idx_val = range(200, 700)
idx_test = range(700, 1700)
features = torch.FloatTensor(np.array(features.todense()))
labels = torch.LongTensor(np.where(labels)[1])
adj = sparse_mx_to_torch_sparse_tensor(adj)
idx_train = torch.LongTensor(idx_train)
idx_val = torch.LongTensor(idx_val)
idx_test = torch.LongTensor(idx_test)
return adj, features, labels, idx_train, idx_val, idx_test
模型的定义
import torch.nn as nn
import torch.nn.functional as F
from layers import GraphConvolution
class GCN(nn.Module):
def __init__(self, nfeat, nhid, nclass, dropout):
super(GCN, self).__init__()
self.gc1 = GraphConvolution(nfeat, nhid)
self.gc2 = GraphConvolution(nhid, nclass)
self.out = nn.Linear(nclass, nclass)
self.dropout = dropout
def forward(self, x, adj):
x = F.relu(self.gc1(x, adj))
x = F.dropout(x, self.dropout, training=self.training)
x = self.gc2(x, adj)
# x = self.out(x)
# x = F.dropout(x, self.dropout, training=self.training)
return F.log_softmax(x, dim=1)
class GraphConvolution(Module):
"""
Simple GCN layer, similar to https://arxiv.org/abs/1609.02907
"""
def __init__(self, in_features, out_features, bias=True):
super(GraphConvolution, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.weight = Parameter(torch.FloatTensor(in_features, out_features))
if bias:
self.bias = Parameter(torch.FloatTensor(out_features))
else:
self.register_parameter('bias', None)
self.reset_parameters()
def reset_parameters(self):
stdv = 1. / math.sqrt(self.weight.size(1))
self.weight.data.uniform_(-stdv, stdv)
if self.bias is not None:
self.bias.data.uniform_(-stdv, stdv)
def forward(self, input, adj):
support = torch.mm(input, self.weight)
output = torch.spmm(adj, support)
if self.bias is not None:
return output + self.bias
else:
return output
def __repr__(self):
return self.__class__.__name__ + ' (' \
+ str(self.in_features) + ' -> ' \
+ str(self.out_features) + ')'
Reference
SEMI-SUPERVISED CLASSIFICATION WITH GRAPH CONVOLUTIONAL NETWORKS
https://www.zhihu.com/question/54504471
https://tkipf.github.io/graph-convolutional-networks/
https://blog.csdn.net/qq_41727666/article/details/84640549
https://www.cnblogs.com/wangxiaocvpr/p/8299336.html
https://github.com/kaize0409/pygcn/blob/master/pygcn