sklearn入门
KNN近邻算法
k-近邻算法(kNN),它的工作原理是:存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系。输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标签。最后,选择k个最相似数据中出现次数最多的分类,作为新数据的分类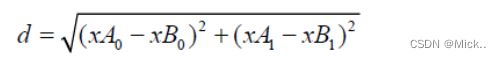
import numpy as np
import operator
"""
Parameters:
无
Returns:
group - 数据集
labels - 分类标签
"""
# 函数说明:创建数据集
def createDataSet():
#六组二维特征
group = np.array([[3,104],[2,100],[1,81],[101,10],[99,5],[98,2]])
#六组特征的标签
labels = ['爱情片','爱情片','爱情片','动作片','动作片','动作片']
return group, labels
"""
Parameters:
inX - 用于分类的数据(测试集)
dataSet - 用于训练的数据(训练集)
labels - 分类标签
k - kNN算法参数,选择距离最小的k个点
Returns:
sortedClassCount[0][0] - 分类结果
"""
# 函数说明:kNN算法,分类器
def classify0(inX, dataSet, labels, k):
#测试集数据距离训练集的距离
diffMat=inX-dataSet
sqDiffMat = diffMat**2
#sum()所有元素相加,sum(0)列相加,sum(1)行相加
sqDistances = sqDiffMat.sum(axis=1)
#开方,计算出距离
distances = sqDistances**0.5
#返回distances中元素从小到大排序后的索引值
sortedDistIndices = distances.argsort()
#定一个记录类别次数的字典
classCount = {}
for i in range(k):
#取出前k个元素的类别
voteIlabel = labels[sortedDistIndices[i]]
#dict.get(key,default=None),字典的get()方法,返回指定键的值,如果值不在字典中返回默认值。
#计算类别次数
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
#reverse降序排序字典
sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
#返回次数最多的类别,即所要分类的类别
return sortedClassCount[0][0]
if __name__ == '__main__':
#创建数据集
group, labels = createDataSet()
#测试集
test = [101,20]
#kNN分类
test_class = classify0(test, group, labels, 3)
#打印分类结果
print(test_class)
sklearn中knn
class sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, weights=’uniform’,
algorithm=’auto’, leaf_size=30,
p=2, metric=’minkowski’,
metric_params=None,
n_jobs=None, **kwargs)
参数:
n_neighbors : int,optional(default = 5)
默认情况下kneighbors查询使用的邻居数。就是k-NN的k的值,选取最近的k个点。weights : str或callable,可选(默认=‘uniform’)
默认是uniform,参数可以是uniform、distance,也可以是用户自己定义的函数。uniform是均等的权重,就说所有的邻近点的权重都是相等的。distance是不均等的权重,距离近的点比距离远的点的影响大。用户自定义的函数,接收距离的数组,返回一组维数相同的权重。algorithm : {‘auto’,‘ball_tree’,‘kd_tree’,‘brute’},可选
快速k近邻搜索算法,默认参数为auto,可以理解为算法自己决定合适的搜索算法。除此之外,用户也可以自己指定搜索算法ball_tree、kd_tree、brute方法进行搜索,brute是蛮力搜索,也就是线性扫描,当训练集很大时,计算非常耗时。kd_tree,构造kd树存储数据以便对其进行快速检索的树形数据结构,kd树也就是数据结构中的二叉树。以中值切分构造的树,每个结点是一个超矩形,在维数小于20时效率高。ball tree是为了克服kd树高纬失效而发明的,其构造过程是以质心C和半径r分割样本空间,每个节点是一个超球体。leaf_size : int,optional(默认值= 30)
默认是30,这个是构造的kd树和ball树的大小。这个值的设置会影响树构建的速度和搜索速度,同样也影响着存储树所需的内存大小。需要根据问题的性质选择最优的大小。p : 整数,可选(默认= 2)
距离度量公式。在上小结,我们使用欧氏距离公式进行距离度量。除此之外,还有其他的度量方法,例如曼哈顿距离。这个参数默认为2,也就是默认使用欧式距离公式进行距离度量。也可以设置为1,使用曼哈顿距离公式进行距离度量。metric : 字符串或可调用,默认为’minkowski’
用于距离度量,默认度量是minkowski,也就是p=2的欧氏距离(欧几里德度量)。metric_params : dict,optional(默认=None)
距离公式的其他关键参数,这个可以不管,使用默认的None即可。n_jobs : int或None,可选(默认=None)
并行处理设置。默认为1,临近点搜索并行工作数。如果为-1,那么CPU的所有cores都用于并行工作。
from sklearn import datasets
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
iris=datasets.load_iris()
x=iris.data
y=iris.target
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3)
# 构建模型
knn=KNeighborsClassifier()
#训练
knn.fit(x_train,y_train)
#测试 预测结果
knn.predict(x_test)
acc=knn.score(x_test,y_test)
print(acc)生成不同分布的数据集
### 簇
from sklearn import datasets
import matplotlib.pyplot as plt
centers=[[2,2],[8,2],[2,8],[8,8]]
#数量 维度 中心 方差
x,y=datasets.make_blobs(n_samples=1000,n_features=2,centers=centers,cluster_std=2)
plt.scatter(x[:,0],x[:,1],s=8,c=y)
plt.show()
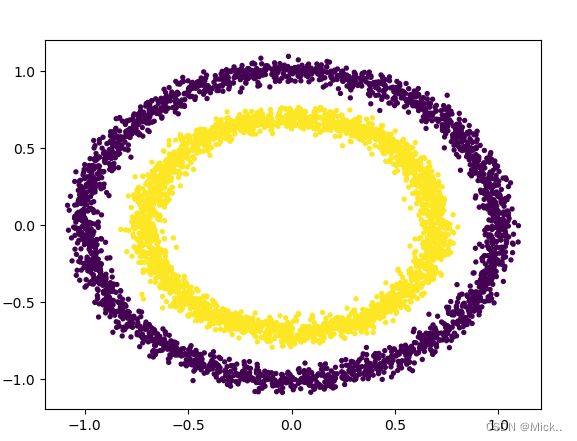
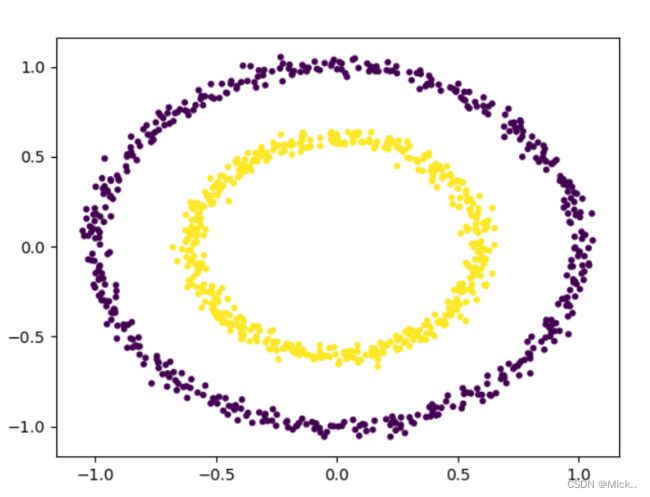
### 同心圆
# 数量 噪声 里面圆向外圆距离
x,y=datasets.make_circles(n_samples=5000,noise=0.04,factor=0.7)
plt.scatter(x[:,0],x[:,1],s=8,c=y)
plt.show()
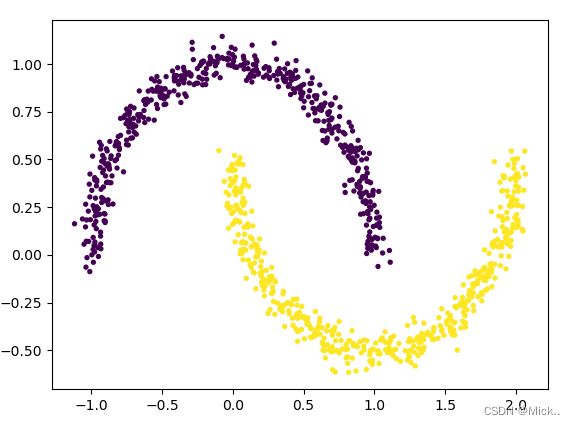
### 月牙
x,y=datasets.make_moons(n_samples=1000,noise=0.05)
plt.scatter(x[:,0],x[:,1],s=8,c=y)
plt.show() 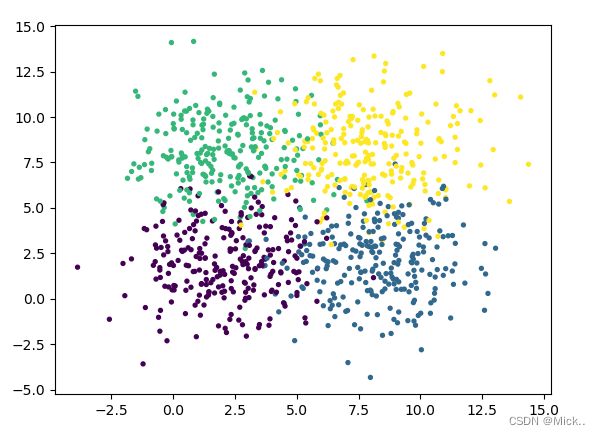
线性回归 Lasso (L1) 岭回归(L2) 弹性网(L1+L2)
# 线性回归和交叉验证
### 线性回归 Lasso (L1) 岭回归(L2) 弹性网(L1+L2)
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LinearRegression,Lasso,Ridge,ElasticNet
x,y=fetch_california_housing(return_X_y=True)
print('数据的维度',x.shape)
lr=LinearRegression()
loss=-cross_val_score(lr,x,y,cv=5,scoring='neg_mean_squared_error').mean()
print(loss)
lasso=Lasso(alpha=0.01)
loss1=-cross_val_score(lasso,x,y,cv=5,scoring='neg_mean_squared_error').mean()
print(loss1)
ridge=Ridge(alpha=0.01)
loss2=-cross_val_score(ridge,x,y,cv=5,scoring='neg_mean_squared_error').mean()
print(loss2)
elasticNet=ElasticNet(alpha=0.01)
loss3=-cross_val_score(elasticNet,x,y,cv=5,scoring='neg_mean_squared_error').mean()
print(loss3)数据预处理
#数据预处理
from sklearn import datasets,preprocessing
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
X,y=load_iris(return_X_y=True)
# random是为了让数据集固定
x_train,x_test,y_train,y_test=train_test_split(X,y,test_size=0.13,random_state=13)
knn=KNeighborsClassifier().fit(x_train,y_train)
print(knn.score(x_test,y_test))
#标准化
X,y=load_iris(return_X_y=True)
X=preprocessing.StandardScaler().fit_transform(X)
x_train,x_test,y_train,y_test=train_test_split(X,y,test_size=0.13,random_state=13)
knn=KNeighborsClassifier().fit(x_train,y_train)
print(knn.score(x_test,y_test))
#归一化 缩放到一个范围内
X,y=load_iris(return_X_y=True)
X=preprocessing.MinMaxScaler().fit_transform(X)
# X=preprocessing.minmax_scale(X)
x_train,x_test,y_train,y_test=train_test_split(X,y,test_size=0.13,random_state=13)
knn=KNeighborsClassifier().fit(x_train,y_train)
print(knn.score(x_test,y_test))
#处理异常值
X,y=load_iris(return_X_y=True)
X=preprocessing.RobustScaler().fit_transform(X)
# X=preprocessing.minmax_scale(X)
x_train,x_test,y_train,y_test=train_test_split(X,y,test_size=0.13,random_state=13)
knn=KNeighborsClassifier().fit(x_train,y_train)
print(knn.score(x_test,y_test))
# 稀疏矩阵的处理,有很多缺失值,缩放到[-1,1]
X,y=load_iris(return_X_y=True)
X=preprocessing.maxabs_scale(X)
x_train,x_test,y_train,y_test=train_test_split(X,y,test_size=0.13,random_state=13)
knn=KNeighborsClassifier().fit(x_train,y_train)
print(knn.score(x_test,y_test))
# 缺失值的库
from sklearn.impute import SimpleImputer
X=SimpleImputer().fit_transform(X)
# missing_values 把什么看做缺失值
# strategy='mean' 平均值,strategy='median' 中位数,strategy='most_frequent' 众数
#,strategy='constant' 常数,如果是是常数那么fill_value=None要确定一个值
参数验证曲线
from sklearn.datasets import load_iris
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score, validation_curve
import matplotlib.pyplot as plt
x, y = load_iris(return_X_y=True)
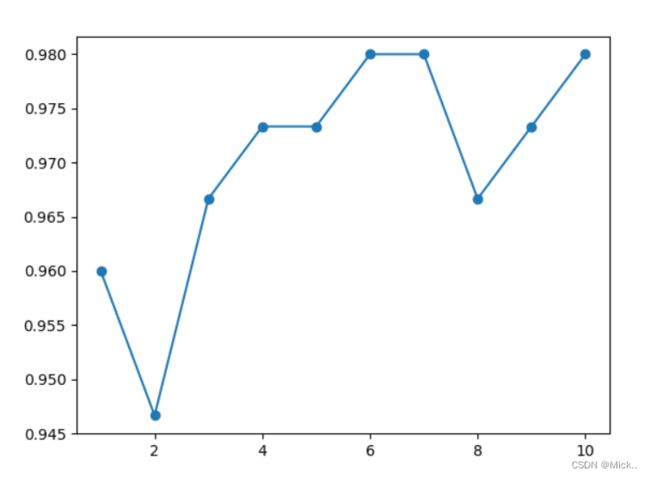
acc = []
for i in range(1,11):
knn=KNeighborsClassifier(i)
acc.append(cross_val_score(knn,x,y,cv=5).mean())
plt.plot(range(1,11),acc,'o-')
plt.show()
# 参数验证曲线
knn1 = KNeighborsClassifier()
train_acc, test_acc = validation_curve(knn1, x, y, param_name='n_neighbors'
, param_range=range(1, 11), cv=5)
# x1=range(1,11)
# y1=train_acc.mean(axis=1)
# print(len(x1))
# print(len(train_acc))
# plt.plot(x1, train_acc.mean(axis=1))
plt.plot(train_acc.mean(axis=1), 'o-', label='train_acc')
plt.plot(test_acc.mean(axis=1), 'o-', label='test_acc')
plt.legend()
plt.show()
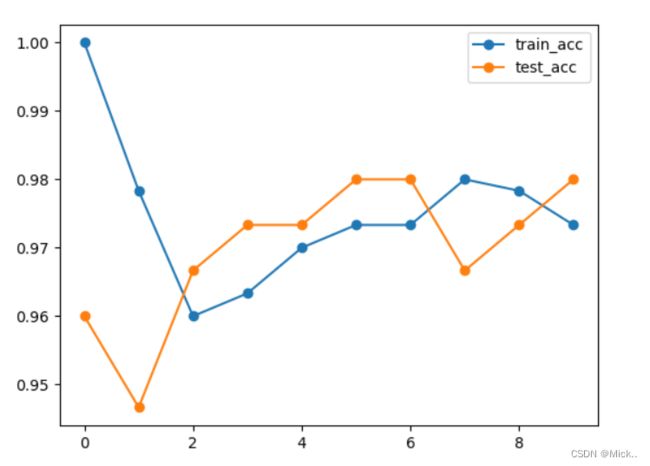
学习曲线
# 逻辑回归(作分类)与学习曲线
from sklearn.linear_model import LogisticRegression as LR
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import learning_curve
import matplotlib.pyplot as plt
x,y=load_breast_cancer(return_X_y=True)
lrl1=LR(penalty="l1",solver="liblinear",C=1,max_iter=1000) # L1正则化必须改solver
lrl2=LR(penalty="l2",solver="liblinear",C=1,max_iter=1000) # GD迭代1000次,默认100下
train_size,train_acc,test_acc=learning_curve(lrl1,x,y,cv=5)
train_size1,train_acc1,test_acc1=learning_curve(lrl2,x,y,cv=5)
print(x.shape)
print(train_size)
print(train_size1)
# axis 因为运转5次会有5个结果得到均值
plt.plot(train_size,train_acc.mean(axis=1),label='train_acc')
# plt.legend()
# plt.show()
plt.plot(train_size,test_acc.mean(axis=1),label='test_acc')
plt.legend()
plt.show()
plt.plot(train_size1,train_acc1.mean(axis=1),label='train_acc1')
# plt.legend()
# plt.show()
plt.plot(train_size1,test_acc1.mean(axis=1),label='test_acc1')
plt.legend()
plt.show()
#竖向是准确率
#两条曲线的间距越小泛化能力越强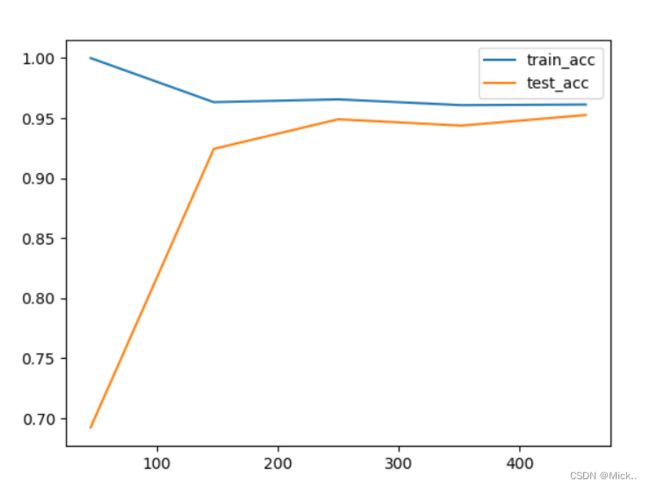
svd
# 如果PCA计算协方差矩阵,因此矩阵太大,资源计算不够,可以尝试SVD
from sklearn.decomposition import TruncatedSVD
from sklearn.datasets import load_iris
iris=load_iris()
x=iris.data
y=iris.target
# print(x.shape)
svd=TruncatedSVD(2)
x=svd.fit_transform(x)
print(x.shape)pca
# 降维
# PCA SVD
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
iris=load_iris()
x=iris.data
y=iris.target
pca=PCA(2) #这是需要降低的维数
x=pca.fit_transform(x)
# pca=PCA(n_components=0.95,svd_solver='full')
# x=pca.fit_transform(x)
# print(x.shape)
plt.figure()
# 第0类样本 第0维度特征,第1维度特征
plt.scatter(x[y==0,0],x[y==0,1],c="r",label=iris.target_names[0])
# 第1类样本 第0维度特征,第1维度特征
plt.scatter(x[y==1,0],x[y==1,1],c="b",label=iris.target_names[1])
# 第2类样本 第0维度特征,第1维度特征
plt.scatter(x[y==2,0],x[y==2,1],c="y",label=iris.target_names[2])
plt.legend()
plt.title("PCA of iris")
plt.show()
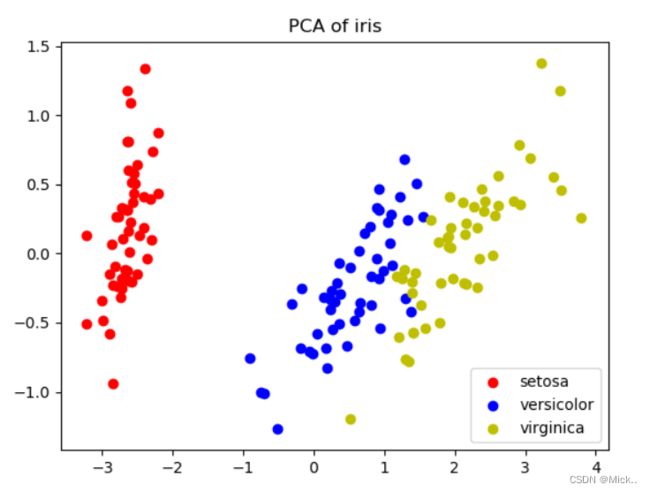
svm
from sklearn.svm import LinearSVC,SVC
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
from sklearn import datasets
x,y=datasets.make_blobs(n_samples=50,centers=2,random_state=0,cluster_std=0.6)
plt.scatter(x[:,0],x[:,1],s=50,c=y,cmap='rainbow')
plt.show()
print(cross_val_score(LinearSVC(),x,y,cv=5,scoring='accuracy').mean())
print(cross_val_score(SVC(kernel='linear'),x,y,cv=5,scoring='accuracy').mean())
x,y=datasets.make_circles(n_samples=1000,noise=0.03,factor=0.6)
plt.scatter(x[:,0],x[:,1],s=10,c=y)
plt.show()
print(cross_val_score(SVC(kernel='linear'),x,y,cv=5,scoring='accuracy').mean())
print(cross_val_score(SVC(kernel='rbf'),x,y,cv=5,scoring='accuracy').mean())

朴素贝叶斯
# 朴素贝叶斯
from sklearn import datasets
from sklearn.naive_bayes import GaussianNB,BernoulliNB
from sklearn.model_selection import cross_val_score
x,y=datasets.load_digits(return_X_y=True)
print(cross_val_score(GaussianNB(),x,y,cv=5,scoring='accuracy').mean())
print(cross_val_score(BernoulliNB(),x,y,cv=5,scoring='accuracy').mean())
聚类分析 Kmeans
#聚类分析
#K-MEANS
from sklearn import datasets
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans,DBSCAN
from sklearn.metrics import silhouette_score
import numpy as np
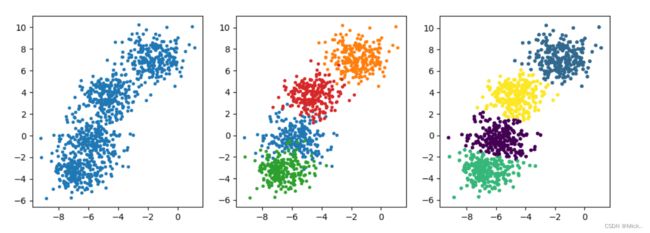
x,y=datasets.make_blobs(n_samples=1000,n_features=2, centers=4,random_state=22)
fig,ax=plt.subplots(1,3,figsize=(12,4))
ax[0].scatter(x[:,0],x[:,1],s=8)
color=["r","green","b","orange"]
for i in range(4):
ax[1].scatter(x[y==i,0],x[y==i,1],s=8)
pred=KMeans(n_clusters=4,random_state=22).fit_predict(x)
for i in range(4):
ax[2].scatter(x[:,0],x[:,1],s=8,c=pred)
plt.show()
print(silhouette_score(x,y))
print(silhouette_score(x,pred))

聚类分析 DBSCAN
#聚类分析
#K-MEANS + DBSCAN
from sklearn import datasets
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans,DBSCAN
import numpy as np
# DBSCAN算法 运转功能极其不错
# centerst=[[1.2,1.2]]
x1,_=datasets.make_circles(n_samples=5000,noise=0.05,factor=0.5)
x2,_=datasets.make_blobs(n_samples=1000,n_features=2, centers=[[1.2,1.2]],cluster_std=0.1)
fig,ax=plt.subplots(1,3,figsize=(16,4))
x=np.concatenate((x1,x2))
ax[0].scatter(x[:,0],x[:,1],s=8)
pred=KMeans(n_clusters=3).fit_predict(x)
ax[1].scatter(x[:,0],x[:,1],s=8,c=pred)
# 降低eps值 提高min_sample值,可以提高这个算法的效率
pred=DBSCAN(eps=0.1,min_samples=10).fit_predict(x) #提高成蔟条件,减小领域,增大样本要求
ax[2].scatter(x[:,0],x[:,1],s=8,c=pred)
plt.show()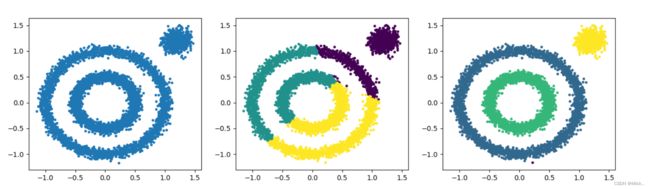
神经网络
# 神经网络
# 学习能力强,计算资源大,运转时间慢,还是使用深度学习运转好
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import cross_val_score
from sklearn.neural_network import MLPRegressor
x,y=fetch_california_housing(return_X_y=True)
print(x.shape)
NN=MLPRegressor(hidden_layer_sizes=(100,),random_state=22)
loss=-cross_val_score(NN,x,y,cv=5,scoring='neg_mean_squared_error').mean()
print(loss)
NN=MLPRegressor(hidden_layer_sizes=(100,100),random_state=22)
loss=-cross_val_score(NN,x,y,cv=5,scoring='neg_mean_squared_error').mean()
print(loss)
NN=MLPRegressor(hidden_layer_sizes=(150,),random_state=22)
loss=-cross_val_score(NN,x,y,cv=5,scoring='neg_mean_squared_error').mean()
print(loss)
NN=MLPRegressor(hidden_layer_sizes=(50,),random_state=22)
loss=-cross_val_score(NN,x,y,cv=5,scoring='neg_mean_squared_error').mean()
print(loss)
NN=MLPRegressor(hidden_layer_sizes=(16,),random_state=22)
loss=-cross_val_score(NN,x,y,cv=5,scoring='neg_mean_squared_error').mean()
print(loss)
模型的保存与加载
# 保存与加载
from sklearn.datasets import load_iris
from sklearn.svm import SVC
import joblib
x,y=load_iris(return_X_y=True)
clf=SVC().fit(x,y)
print(clf.score(x,y))
#保存
joblib.dump(clf,'svc.pkl')
clf2=joblib.load('svc.pkl')
print(clf2.score(x,y))决策树
# 决策树
from sklearn.datasets import load_wine
from sklearn import tree
from sklearn.model_selection import train_test_split
wine=load_wine()
x_train,x_test,y_train,y_test=train_test_split(wine.data,wine.target,test_size=0.3,random_state=22)
# criterion 判定标准 splitter 是选取特征 random特征较多可以帮助过拟合
clf=tree.DecisionTreeClassifier(criterion='entropy',random_state=22,splitter='random'
,max_depth=10,min_samples_leaf=3,min_samples_split=3
)
clf.fit(x_train,y_train)
acc=clf.score(x_test,y_test)
print(acc)集成学习
#集成学习
#bagging 模型独立,共同决策 100个决策树 40 A, 60 B 则该数据集是60
#boosting 模型有序,逐渐提升 第一颗决策树 60%是正确的,40%错误的(加权重)
#逐渐决策树,拿到前面决策树的不好结果
from sklearn.datasets import load_wine
from sklearn import tree
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
# 集成模块
from sklearn.ensemble import RandomForestClassifier,BaggingClassifier,AdaBoostClassifier
wine=load_wine()
x_train,x_test,y_train,y_test=train_test_split(wine.data,wine.target,test_size=0.3,random_state=0)
dtc=DecisionTreeClassifier(random_state=22).fit(x_train,y_train)
#随机森林
rfc=RandomForestClassifier(random_state=22).fit(x_train,y_train)
print(dtc.score(x_test,y_test))
print(rfc.score(x_test,y_test))
#集成模块
bgc=BaggingClassifier(random_state=22).fit(x_train,y_train)
adc=AdaBoostClassifier(learning_rate=0.1,random_state=22).fit(x_train,y_train)
print(bgc.score(x_test,y_test))
print(adc.score(x_test,y_test))xgboost
# xgboost
from sklearn.model_selection import train_test_split
from sklearn.datasets import fetch_california_housing
from sklearn.metrics import mean_squared_error as MSE
import xgboost
x,y=fetch_california_housing(return_X_y=True)
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=0)
dtrain=xgboost.DMatrix(x_train,y_train)
dtest=xgboost.DMatrix(x_test,y_test)
# silent默认是true False将建树过程给弄出来,objective 默认是分类, eta学习率
param={'silent':False,'objective':'reg:linear' #默认是分类,这个是搞回归
,"eta":0.1}
xgb=xgboost.train(param,dtrain,num_boost_round=175)
pred=xgb.predict(dtest)
print(MSE(y_test,pred))