二手车价格预测
二手车价格预测
- 查看要求
- 查看原始数据
-
- 导入数据
- 查看数据
-
- 日期格式转化
- 是否存在空值
- 特征工程
-
- 使用天数
- 数据分箱
- 选择特征字段
- 处理测试数据
- 特别注意
- 构建模型
-
- 模块导入
- 数据预处理
- 模型搭建
-
- Lasso模型
- Ridge模型
- BayesianRidge模型
- ExtraTreesRegressor模型
- XGBRegressor模型
- 运行结果
- 模型融合
-
- 数据准备
- 最终模型
- 最终结果
- 提交结果
- 总结
查看要求
原始数据有三个数据文件,训练数据、测试数据和格式数据。目的通过构建模型,来预测二手车的价格,评价的标准就是MSE越小越好。

查看原始数据
导入数据
首先导入数据,要注意的是,这里的csv文件是用空格进行分割的。
import pandas as pd
import numpy as np
path1='/home/jhon/Desktop/DATA/car/used_car_train_20200313.csv'
path2='/home/jhon/Desktop/DATA/car/used_car_testB_20200421.csv'
train=pd.read_csv(path1,sep=' ')
test=pd.read_csv(path2,sep=' ')
查看数据
查看数据内容,包括数据的属性,是数值类型还是字符串类型。其中有15个是已知字段,包括车的品牌、车的类型等等,15个匿名字段v_0到v_14。
train.describe
train.head()
train.columns
train.dtypes
#运行结果,只截取前三条
SaleID int64
name int64
regDate int64
这里日期有两个字段regDate和creatDate,查看格式就知道,直接导入有问题。原始数据,没有用分隔符把年月日分开,所以识别别不了,需要更改格式。
train['regDate']
#运行结果,只截取前三条
0 20040402
1 20030301
2 20040403
日期格式转化
train['creatDate']=pd.to_datetime(train['creatDate'],format='%Y%m%d',errors='coerce')
train['regDate']=pd.to_datetime(train['regDate'],format='%Y%m%d',errors='coerce')
#运行结果,只截取前三条
0 2004-04-02
1 2003-03-01
2 2004-04-03
Name: regDate, Length: 150000, dtype: datetime64[ns]
这些参数不过多介绍,但errors要注意,因为有些车没有regDate,errors就必须要加上。
是否存在空值
train.isnull().sum()
#运行结果,只截取前三条
SaleID 0
name 0
regDate 11347
model 1
brand 0
bodyType 4506
fuelType 8680
gearbox 5981
可以看出regDate存在很多空值,最简单粗暴的方法,就是把这些空值全部都删掉,但这会损失很大的数据。先把数据放在这里,在特征工程的时候一起处理。
特征工程
特征工程是很重要的内容,很多时候特征工程会直接影响模型的好坏。
使用天数
根据常识,二手车使用的时间越长,价格肯定是越低的,当然那些有收藏价值的老爷车不在此行列。所以我们需要得到使用天数,这也是先验信息。
#对时间序列进行处理,常识知道,使用的时间越短,交易的价格越高
train['day']=train['creatDate']-train['regDate']
train['day']=train['day'].dt.days
#对于没有天数的数据填充-1
train['day']=train['day'].fillna(value=-1)
#查看数据的大致分布
train['day'].plot(kind='kde')
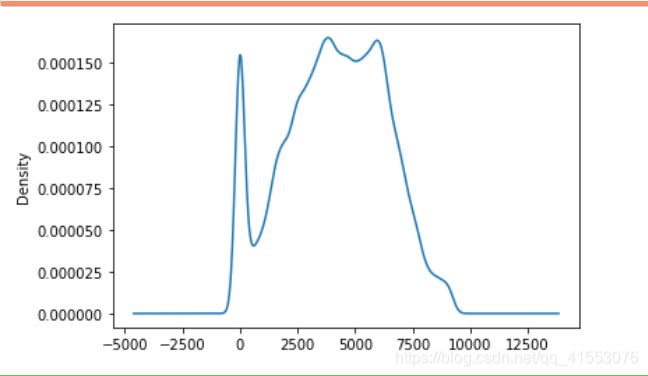
上面的代码就不过多的介绍,但是这个概率密度分布很有意思。出现的第一个小高峰,可能是不满意自己买的车,也有可能是某车型刚出来,买了囤积然后倒卖,或者其他的原因。从两三百天的开始,大概率是人们想换车,也是我们平常意义上的二手车。
数据分箱
数据分箱,说白了就是对数据进行分类。方法有卡方分箱、等距分箱、等频分箱以及其他的分箱方式,当然也可以自己手动划分。这里我对天数和power_level进行了分箱。
def day_level(x):
if x < 80:
return 0
elif x < 200:
return 1
elif x < 500:
return 2
elif x < 1000:
return 3
elif x < 2000:
return 4
elif x < 3000:
return 5
elif x < 4000:
return 6
elif x < 5000:
return 7
elif x < 6000:
return 8
else:
return 9
train['day_level']=train['day'].apply(day_level)
train['power_level']=pd.cut(train['power'],bins=10,labels=np.arange(10))
train['power_level']=train['power_level'].astype('int')
选择特征字段
最后选择特征字段,我这里写的有点啰嗦。
train_t=train[['SaleID', 'model', 'brand', 'bodyType', 'fuelType',
'gearbox', 'kilometer', 'notRepairedDamage', 'regionCode',
'seller', 'offerType','day', 'day_level', 'power','power_level',
'v_0', 'v_1', 'v_2', 'v_3','v_4', 'v_5', 'v_6', 'v_7',
'v_8', 'v_9', 'v_10', 'v_11', 'v_12','v_13', 'v_14']]
train_t['model']=train_t['model'].fillna(-1)
train_t['bodyType']=train_t['bodyType'].fillna(-1)
train_t['fuelType']=train_t['fuelType'].fillna(-1)
train_t['gearbox']=train_t['gearbox'].fillna(-1)
处理测试数据
以上都是对训练数据进行处理,但是我们需要对测试数据进行相同处理,否则会在后面的模型中出现问题。
test['creatDate']=pd.to_datetime(test['creatDate'],format='%Y%m%d',errors='coerce')
test['regDate']=pd.to_datetime(test['regDate'],format='%Y%m%d',errors='coerce')
test['day']=test['creatDate']-test['regDate']
test['day']=test['day'].dt.days
test['day']=test['day'].fillna(value=-1)
test['day_level']=test['day'].apply(day_level)
test['power_level']=pd.cut(test['power'],bins=10,labels=np.arange(10))
test['power_level']=test['power_level'].astype('int')
test_t=test[['SaleID', 'model', 'brand', 'bodyType', 'fuelType',
'gearbox', 'kilometer', 'notRepairedDamage', 'regionCode',
'seller', 'offerType','day', 'day_level', 'power','power_level',
'v_0', 'v_1', 'v_2', 'v_3','v_4', 'v_5', 'v_6', 'v_7',
'v_8', 'v_9', 'v_10', 'v_11', 'v_12','v_13', 'v_14']]
test_t['model']=test_t['model'].fillna(-1)
test_t['bodyType']=test_t['bodyType'].fillna(-1)
test_t['fuelType']=test_t['fuelType'].fillna(-1)
test_t['gearbox']=test_t['gearbox'].fillna(-1)
特别注意
notRepairedDamage这个字段如果不进行处理的话会出现问题,这个字段一共有三个值0,1,和“-”,需要把“-”替换,不然会出错,就是因为模型出错,回头检查才发现这个问题,所以一定要仔细了。
train_t['notRepairedDamage'].replace(to_replace='-',value=-1,inplace=True)
train_t['notRepairedDamage']=pd.to_numeric(train_t['notRepairedDamage'])
test_t['notRepairedDamage'].replace(to_replace='-',value=-1,inplace=True)
test_t['notRepairedDamage']=pd.to_numeric(test_t['notRepairedDamage'])
到此为止特征工程就结束了,肯定还有其他的处理方式的,可以尝试一下。
构建模型
这里我选择五种算法进行预测,包括两种线性算法,一种非线性的贝叶斯回归和随机森林以及大名鼎鼎的xgboost,最后根据五种算法的预测结果,得到最终的模型。SVM没敢用,一运行肯定要崩。
模块导入
把需要的模块都导入,包括评价标准MSE。
#选择五种算法进行预测,最后根据五种算法的预测结果,得到最终的模型
#包括Lasso,Ridge,RandomForestRegressor,XGBRegressor
from sklearn.preprocessing import StandardScaler ,PolynomialFeatures
from sklearn.model_selection import train_test_split,GridSearchCV
from sklearn.pipeline import Pipeline
from sklearn.ensemble import ExtraTreesRegressor
from sklearn.linear_model import Lasso,Ridge,BayesianRidge
from xgboost import XGBRegressor
from sklearn.metrics import mean_squared_error
from sklearn.decomposition import PCA
数据预处理
先对数据进行预处理,包括数据的标准化。一般而言数据标准化有两种方式。一种是MinMaxScaler,也就是归一化。另一种是StandardScaler,在概率论中这很重要。这里我用,StandardScaler对数据进行标准化。
pipe=Pipeline([('std',StandardScaler())])
train_t=pipe.fit_transform(train_t)
x_train,x_test,y_train,y_test=train_test_split(train_t,train['price'],
test_size=0.25,
random_state=666)
模型搭建
Lasso模型
def lasso(x,y):
param_grid={'alpha':[0.01,1,10,100]}
g=GridSearchCV(Lasso(),
param_grid=param_grid,
refit=True,
verbose=0,
n_jobs=-1,
cv=3)
g.fit(x,y)
print(g.score(x,y))
return g.best_estimator_
Ridge模型
def ridge(x,y):
param_grid={'alpha':[0.01,1,10,100]}
g=GridSearchCV(Ridge(),
param_grid=param_grid,
refit=True,
verbose=0,
n_jobs=-1,
cv=3)
g.fit(x,y)
print(g.score(x,y))
return g.best_estimator_
BayesianRidge模型
def br(x,y):
p=PolynomialFeatures(degree=2)
x=p.fit_transform(x_train)
param_grid={'n_iter':[100,200,300]}
g=GridSearchCV(BayesianRidge(),
param_grid=param_grid,
refit=True,
verbose=0,
n_jobs=-1,
cv=3)
g.fit(x,y)
print(g.score(x,y))
return g.best_estimator_
ExtraTreesRegressor模型
def FR(x,y):
param_grid={'n_estimators':[200,300],
'max_features':[0.5,0.7],
'max_depth':[10,14]}
g=GridSearchCV(ExtraTreesRegressor(oob_score=True,
min_samples_split=10,
min_samples_leaf=3,
bootstrap=True),
param_grid=param_grid,
refit=True,
verbose=0,
n_jobs=-1,
cv=3)
g.fit(x,y)
print(g.score(x,y))
return g.best_estimator_
XGBRegressor模型
超参数设置的少点,主要还是减少计算量。
def xgbr(x,y):
param_grid={'n_estimators':[200,300],
'max_depth':[10,14],
'learning_rate':[0.05,0.1]}
g=GridSearchCV(XGBRegressor(reg_lambda =1,
subsample=0.8,
reg_alpha=1),
param_grid=param_grid,
refit=True,
verbose=0,
n_jobs=-1,
cv=3)
g.fit(x,y)
print(g.score(x,y))
return g.best_estimator_
运行结果
可以看出大名鼎鼎的xgboost真的很厉害,预测结果达到了99.5%,大概率有的过拟合了,其他模型会是一个很好的补充。
k1=ridge(x_train,y_train)
k2=lasso(x_train,y_train)
k3=br(x_train,y_train)
k4=FR(x_train,y_train)
k5=xgbr(x_train,y_train)
#运行的时间和预测结果
0.7070375689222635
CPU times: user 114 ms, sys: 224 ms, total: 338 ms
Wall time: 1.59 s
0.6943739987190218
CPU times: user 6.47 s, sys: 313 ms, total: 6.78 s
Wall time: 14.5 s
0.92228695612173
CPU times: user 22.8 s, sys: 4.04 s, total: 26.8 s
Wall time: 1min 16s
0.9712418187139599
CPU times: user 35.7 s, sys: 111 ms, total: 35.8 s
Wall time: 4min 1s
0.9948270978230055
CPU times: user 3min 20s, sys: 1.1 s, total: 3min 21s
Wall time: 14min 47s
模型融合
数据准备
需要把五个模型的预测结果,构成最终模型的训练数据。特别注意的是BayesianRidge模型,我增加了一个degree,变成了非线性模型。所以转化的时候需要注意。
b=pd.DataFrame()
b['lasso']=k1.predict(train_t)
b['ridge']=k2.predict(train_t)
p1=PolynomialFeatures(degree=2)
p1.fit_transform(train_t)
b['br']=k3.predict(p1.fit_transform(train_t))
b['fr']=k4.predict(train_t)
b['xgbr']=k5.predict(train_t)
最终模型
得到最终模型的预测结果。
%%time
#最终模型
x1_train,x1_test,y1_train,y1_test=train_test_split(b,train['price'],
test_size=0.2,
random_state=6096)
k_f=xgbr(x1_train,y1_train)
k_f.score(x1_test,y1_test)
#最终结果
0.99414410853459
CPU times: user 2min 18s, sys: 3.08 s, total: 2min 21s
Wall time: 11min 7s
0.9962043460182209
最终结果
最终的模型是五种模型的融合结果,那么这五种模型他们各自所占的比例是多少呢?
#查看五种模型所占的比例,乖乖,xgboost面前,其他的都是弟弟
#这是最终模型在训练集上的MSE
k_f.feature_importances_
price_t=k_f.predict(b)
mse=mean_squared_error(train['price'],price_t)
print(k_f.feature_importances_,'\n'*2,mse)
#最终结果
五种模型占比:[0.00104416 0.00119545 0.00122893 0.00137374 0.9951577 ]
MSE:387094.37828317087
可以看到在xgboost面前其他的都是弟弟,结果是很不错的。
提交结果
b1=pd.DataFrame()
pipe=Pipeline([('std',StandardScaler())])
test_t=pipe.fit_transform(test_t)
b1['lasso']=k1.predict(test_t)
b1['ridge']=k2.predict(test_t)
p2=PolynomialFeatures(degree=2)
p2.fit_transform(test_t)
b1['br']=k3.predict(p2.fit_transform(test_t))
b1['fr']=k4.predict(test_t)
b1['xgbr']=k5.predict(test_t)
prediction_result=pd.DataFrame(k_f.predict(b1))
prediction_result.head(2)
prediction_result.to_csv('/home/jhon/Desktop/prediction_result.csv')
总结
此次项目收获很多。包括机器学习,数据清洗的一些很有用的小技巧,最后如果有什么问题可以留言给我。