【python爬虫+可视化】2020疫情数据可视化
补档一下2020.6在家去不了学校做的疫情数据可视化 (使用Python进行爬虫+可视化输出)
**
一、 环境配置
**
使用编程软件python3.7
代码涉及函数库:
关于警告的warnings
基础数据处理的两个函数库numpy和pandas
涉及网络爬虫的requests
Java相关的json
时间函数库time
画图函数库pyecharts *使用版本1.7.1
import warnings
import numpy as np
import pandas as pd
import requests
import json
import time
from pyecharts import options as opts
from pyecharts.charts import Map
from pyecharts.charts import Line
pd.set_option('max_rows',500)
warnings.filterwarnings('ignore')
二、输入输出文件
代码文件:疫情数据可视化.py
输出html:
中国疫情地图.html
世界疫情地图.html
广东疫情折线图.html
美国疫情折线图.html
三.、代码设计
1. 网络爬虫获取数据
编写类放所有函数
(1)连接网站
(2)获取数据
(3)写入CSV存储
(4)获取全国各省的实时数据
(5)获取世界实时数据
(6)获取中国历史疫情数据
(7)获取特定省的疫情数据
(8)获取特定国家疫情数据
(9)获取世界各国历史数据
'''获取疫情数据'''
class getCOVID19(object):
'''请求连接网站'''
def connectUrl(self,url):
'''url:要访问的网址,str'''
#设置代理网站
headers = {};
headers['User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.157 Safari/537.36'
try:
# 使用requests发起请求
response = requests.get(url,headers = headers)
# print(response.text)
print('请求状态:',response.status_code)
print('访问成功!!!')
except:
print('访问失败!!!')
return response
'''获取所有数据'''
def getTotalData(self,response):
'''response:访问网站解析之后得到的文件'''
# 查看网站的源代码可以看到数据为类似字典的json格式
# 故转换为json格式
data_json = json.loads(response.text)
# print('查看json格式的数据格式:\n',data_json.keys())
# 'data'键中存放着我们需要的数据
# 取出数据(字典格式)
data = data_json['data']
# print('疫情数据:\n',data)
# print('取出的数据的键:\n',data.keys())
'''
chinaTotal:全国当日数据
chinaDayList:全国历史数据
lastUpdateTime:更新时间
areaTree:世界各地实时数据
'''
return data
'''写入csv的函数'''
def writeCSV(self,data,name):
'''data:要写入的数据,DataFrame格式
name:主要的文件名称
'''
file_name = name + '_' + time.strftime('%Y_%m_%d',time.\
localtime(time.time())) + '.csv'
data.to_csv(file_name,index = None,encoding = 'utf_8_sig')
print(file_name + '保存成功')
'''获取全国各省的实时数据'''
def getTimlyChinaData(self):
start = time.time()
url = r'https://c.m.163.com/ug/api/wuhan/app/data/list-total'
# 连接网址
response = getCOVID19.connectUrl(self,url)
print('网站数据大小:',len(response.text))
# 获取数据
data = getCOVID19.getTotalData(self,response)
# 全国各省的实时数据
provice_data = data['areaTree'][2]['children']
'''
provice_data是列表格式
每个元素是一个省的实时数据,
并且为字典格式,每个省的键名称全部相同
'''
# print('每个省键名称:\n',provice_data[0].keys())
'''
today:各省当日数据
total:各省当日累计数据
extData:无任何数据,空值
name:各省名称
id:各省行政编号
lastUpdateTime:更新时间
children:各省下一级数据
'''
# 提取需要的数据并封装
##主要信息
info = pd.DataFrame(provice_data)[['id','lastUpdateTime','name']]
## 生成today的数据
today_data = pd.DataFrame([i['today'] for i in provice_data])
## 修改列名
today_data.columns = ['today_' + i for i in today_data.columns]
## 生成total的数据
total_data = pd.DataFrame([i['total'] for i in provice_data])
## 修改列名
total_data.columns = ['total_' + i for i in total_data.columns]
final_data = pd.concat([info,total_data,today_data],axis = 1)
# #写入csv文件
# name = 'ChinaTimly'
# getCOVID19.writeCSV(self,final_data,name)
print('耗时:',round(time.time() - start))
return final_data
'''获取世界实时数据'''
def getTimlyWorldData(self):
start = time.time()
url = r'https://c.m.163.com/ug/api/wuhan/app/data/list-total'
# 连接网址
response = getCOVID19.connectUrl(self,url)
print('网站数据大小:',len(response.text))
# 获取数据
data = getCOVID19.getTotalData(self,response)
# 取出实际各地的数据
area_tree = data['areaTree']
# print('世界数据的键名:\n',area_tree[0])
'''
today 当日数据
total 累计数据
extData 无任何数据
name 国家名称
id 各国编号
lastUpdateTime 更新时间
children 各国下一级数据(例如省份或州)
'''
# 提取需要的数据并封装
##主要信息
info = pd.DataFrame(area_tree)[['id','lastUpdateTime','name']]
## 生成today的数据
today_data = pd.DataFrame([i['today'] for i in area_tree])
## 修改列名
today_data.columns = ['today_' + i for i in today_data.columns]
## 生成total的数据
total_data = pd.DataFrame([i['total'] for i in area_tree])
## 修改列名
total_data.columns = ['total_' + i for i in total_data.columns]
final_data = pd.concat([info,total_data,today_data],axis = 1)
# #写入csv文件
# name = 'WorldTimly'
# getCOVID19.writeCSV(self,final_data,name)
print('耗时:',round(time.time() - start))
return final_data
'''获取中国历史数据'''
def getHisChinaData(self):
start = time.time()
'''
为了得到每个省的历史数据,
我们只需要将各省的行政代码作为参数传入这个地址即可,如下所示:
https://c.m.163.com/ug/api/wuhan/app/data/list-by-area-code?areaCode=各省行政代码
例如广东省历史数据的地址为:https://c.m.163.com/ug/api/wuhan/app/data/list-by-area-code?areaCode=440000
湖南省历史数据的地址为:https://c.m.163.com/ug/api/wuhan/app/data/list-by-area-code?areaCode=430000
'''
# 获取各省的行政代码
timly_china = getCOVID19.getTimlyChinaData(self)
province_info = {num:name for num,name in zip(timly_china['id'],timly_china['name'])}
# 遍历各省编号
for province_id in province_info:
# 容错机制
try:
# 按照各省的行政编号构造网址
url = r'https://c.m.163.com/ug/api/wuhan/app/data/list-by-area-code?areaCode=' + province_id
# 连接网址
response = getCOVID19.connectUrl(self,url)
print('网站数据大小:',len(response.text))
data_json = json.loads(response.text)
# 需要的主要数据
data = data_json['data']['list']
#主要信息
info = pd.DataFrame(data)['date']
# 生成today的数据
today_data = pd.DataFrame([i['today'] for i in data])
# 修改列名
today_data.columns = ['today_' + i for i in today_data.columns]
# 生成total的数据
total_data = pd.DataFrame([i['total'] for i in data])
# 修改列名
total_data.columns = ['total_' + i for i in total_data.columns]
# 合并数据
province_data = pd.concat([info,total_data,today_data],axis = 1)
# 提取数据并添加各省的名称列
province_data['name'] = province_info[province_id]
# 合并数据(从湖北开始)
if province_id == '420000':
his_province = province_data
else:
his_province = pd.concat([his_province,province_data])
print('{0} 成功!!!大小:{1}->{2}'.format(province_info[province_id],
province_data.shape,his_province.shape))
end = round(time.time() - start)
print('耗时:',end)
print('-'*40)
#设置延迟等待
time.sleep(5)
except:
print('{0} 失败!!!大小:{1}->{2}'.format(province_info[province_id],
province_data.shape,his_province.shape))
print('-'*40)
# # 写入CSV文件
# name = 'HistoryChina'
# getCOVID19.writeCSV(self,his_province,name)
final_end = round(time.time() - start)
print('累计耗时:',final_end)
return his_province
'''获取特定省的疫情数据'''
def getProvinceData(self,province_name):
start = time.time()
# 获取该省的行政代码
timly_china = getCOVID19.getTimlyChinaData(self)
province_info = {name:num for name,num in zip(timly_china['name'],timly_china['id'])}
province_id = str(province_info[province_name])
# 容错机制
try:
# 按照各省的行政编号构造网址
url = r'https://c.m.163.com/ug/api/wuhan/app/data/list-by-area-code?areaCode=' + province_id
# 连接网址
response = getCOVID19.connectUrl(self,url)
print('网站数据大小:',len(response.text))
data_json = json.loads(response.text)
# 需要的主要数据
data = data_json['data']['list']
#主要信息
info = pd.DataFrame(data)['date']
# 生成today的数据
today_data = pd.DataFrame([i['today'] for i in data])
# 修改列名
today_data.columns = ['today_' + i for i in today_data.columns]
# 生成total的数据
total_data = pd.DataFrame([i['total'] for i in data])
# 修改列名
total_data.columns = ['total_' + i for i in total_data.columns]
# 合并数据
province_data = pd.concat([info,total_data,today_data],axis = 1)
print('{0} 成功!!!大小:{1}'.format(province_name,province_data.shape))
end = round(time.time() - start)
print('耗时:',end)
print('-'*40)
except:
print('{0} 失败!!!大小:{1}'.format(province_name,province_data.shape))
print('-'*40)
return province_data
'''获取特定国家疫情数据的函数'''
def getCountryData(self,country_name):
start = time.time()
# 获取该国的行政代码
timly_world = getCOVID19.getTimlyWorldData(self)
country_info = {name:num for name,num in zip(timly_world['name'],timly_world['id'])}
country_id = str(country_info[country_name])
# 容错机制
try:
# 按照各国的编号构造网址
url = r'https://c.m.163.com/ug/api/wuhan/app/data/list-by-area-code?areaCode=' + country_id
# 连接网址
response = getCOVID19.connectUrl(self,url)
print('网站数据大小:',len(response.text))
data_json = json.loads(response.text)
# 需要的主要数据
data = data_json['data']['list']
# 主要信息
info = pd.DataFrame(data)['date']
# 生成today的数据
today_data = pd.DataFrame([i['today'] for i in data])
# 修改列名
today_data.columns = ['today_' + i for i in today_data.columns]
# 生成total的数据
total_data = pd.DataFrame([i['total'] for i in data])
# 修改列名
total_data.columns = ['total_' + i for i in total_data.columns]
# 合并数据
country_data = pd.concat([info,total_data,today_data],axis = 1)
print('{0} 成功!!!大小:{1}'.format(country_name,country_data.shape))
end = round(time.time() - start)
print('耗时:',end)
print('-'*40)
except:
print('{0} 失败!!!大小:{1}'.format(country_name,country_data.shape))
print('-'*40)
return country_data
'''世界各国历史数据'''
def getHisWorldData(self):
start = time.time()
'''
通过每个国家的编号访问每个国家历史数据的地址
例如意大利历史数据网址为:https://c.m.163.com/ug/api/wuhan/app/data/list-by-area-code?areaCode=15
'''
# 获取各国的行政代码
timly_world = getCOVID19.getTimlyWorldData(self)
country_info = {num:name for num,name in zip(timly_world['id'],timly_world['name'])}
# 遍历各国编号
for country_id in country_info:
# 容错机制
try:
# 按照各国的编号构造网址
url = r'https://c.m.163.com/ug/api/wuhan/app/data/list-by-area-code?areaCode=' + country_id
# 连接网址
response = getCOVID19.connectUrl(self,url)
print('网站数据大小:',len(response.text))
data_json = json.loads(response.text)
# 需要的主要数据
data = data_json['data']['list']
# 主要信息
info = pd.DataFrame(data)['date']
# 生成today的数据
today_data = pd.DataFrame([i['today'] for i in data])
# 修改列名
today_data.columns = ['today_' + i for i in today_data.columns]
# 生成total的数据
total_data = pd.DataFrame([i['total'] for i in data])
# 修改列名
total_data.columns = ['total_' + i for i in total_data.columns]
# 合并数据
country_data = pd.concat([info,total_data,today_data],axis = 1)
# 提取数据并添加各国的名称列
country_data['name'] = country_info[country_id]
# 合并数据(从突尼斯开始)
if country_id == '9577772':
his_world = country_data
else:
his_world = pd.concat([his_world,country_data])
print('{0} 成功!!!大小:{1}->{2}'.format(country_info[country_id],
country_data.shape,his_world.shape))
end = round(time.time() - start)
print('耗时:',end)
print('-'*40)
#设置延迟等待
time.sleep(5)
except:
print('{0} 失败!!!大小:{1}->{2}'.format(country_info[country_id],
country_data.shape,his_world.shape))
print('-'*40)
# # 写入CSV文件
# name = 'HistoryWorld'
# getCOVID19.writeCSV(self,his_world,name)
final_end = round(time.time() - start)
print('累计耗时:',final_end)
return his_world
2. 可视化
编写类放所有函数
(1)绘制中国地图
(2)绘制世界地图
(3)绘制中国疫情地图
(4)绘制世界疫情地图
(5)绘制疫情折线图
(6)绘制指定省的疫情折线图
(7)绘制指定国家的疫情折线图
'''可视化的类'''
class dataVisual(object):
'''绘制中国地图的函数'''
def visualMapChina(self,page_title,current_data_dic1,current_data_dic2,current_data_dic3,time_format):
'''
page_title:标题,str
current_data_dic1:今日确诊人数的[省名,数据],嵌套列表
current_data_dic2:累计确诊人数的[省名,数据],嵌套列表
current_data_dic3:累计死亡人数的[省名,数据],嵌套列表
time_format:系统时间
'''
c = (
Map(init_opts=opts.InitOpts(page_title=page_title, bg_color="#FDF5E6",width="1200px", height="700px"))
.add("今日确诊人数", data_pair=current_data_dic1, maptype="china")
.add("累计确诊人数", data_pair=current_data_dic2, maptype="china")
.add("累计死亡人数", data_pair=current_data_dic3, maptype="china")
.set_series_opts(label_opts=opts.LabelOpts(color="#8B4C39", font_size=10))
.set_global_opts(
title_opts=opts.TitleOpts(title=page_title, subtitle="数据更新于"+time_format),
# 自定义的每一段的范围,以及每一段的文字,以及每一段的特别的样式
visualmap_opts=opts.VisualMapOpts(pieces=[
{"value": 0, "label": "无", "color": "#00ccFF"},
{"min": 1, "max": 9, "color": "#FFCCCC"},
{"min": 10, "max": 99, "color": "#DB5A6B"},
{"min": 100, "max": 499, "color": "#FF6666"},
{"min": 500, "max": 999, "color": "#CC2929"},
{"min": 1000, "max": 9999, "color": "#8C0D0D"},
{"min": 10000, "color": "#9d2933"}
], is_piecewise=True),
)
)
return c
'''绘制世界地图的函数'''
def visualMapWorld(self,page_title,current_data_dic1,current_data_dic2,current_data_dic3,time_format):
'''
page_title:标题,str
current_data_dic1:今日确诊人数的[省名,数据],嵌套列表
current_data_dic2:累计确诊人数的[省名,数据],嵌套列表
current_data_dic3:累计死亡人数的[省名,数据],嵌套列表
time_format:系统时间
'''
c = (
Map(init_opts=opts.InitOpts(page_title=page_title, bg_color="#FDF5E6",width="1200px", height="700px"))
.add("今日确诊人数", data_pair=current_data_dic1, maptype="world")
.add("累计确诊人数", data_pair=current_data_dic2, maptype="world")
.add("累计死亡人数", data_pair=current_data_dic3, maptype="world")
.set_series_opts(label_opts=opts.LabelOpts(color="#8B4C39", font_size=10))
.set_global_opts(
title_opts=opts.TitleOpts(title=page_title, subtitle="数据更新于"+time_format),
# 自定义的每一段的范围,以及每一段的文字,以及每一段的特别的样式
visualmap_opts=opts.VisualMapOpts(pieces=[
{"value": 0, "label": "无", "color": "#00ccFF"},
{"min": 1, "max": 9, "color": "#FFCCCC"},
{"min": 10, "max": 99, "color": "#DB5A6B"},
{"min": 100, "max": 499, "color": "#FF6666"},
{"min": 500, "max": 999, "color": "#CC2929"},
{"min": 1000, "max": 9999, "color": "#8C0D0D"},
{"min": 10000, "color": "#9d2933"}
], is_piecewise=True),
)
)
return c
'''绘制中国疫情地图的函数'''
def nCoV2019MapChina(self):
# 获取中国实时数据
timly_china = getCOVID19.getTimlyChinaData(self)
# 今日确诊数据
data1 = timly_china[['name','today_confirm']]
data1['today_confirm'].replace(np.nan,'0',inplace=True)
current_data_dic1 = []
for i in range(len(data1)):
pcurrent_data_dic=[]
area = data1.iloc[i]['name']
pcurrent_data_dic.append(area)
confirm = int(data1.iloc[i]['today_confirm'])
pcurrent_data_dic.append(confirm)
current_data_dic1.append(pcurrent_data_dic)
# 累计确诊数据
data2 = timly_china[['name','total_confirm']]
data2['total_confirm'].replace(np.nan,'0',inplace=True)
current_data_dic2 = []
for i in range(len(data2)):
pcurrent_data_dic=[]
area = data2.iloc[i]['name']
pcurrent_data_dic.append(area)
confirm = int(data2.iloc[i]['total_confirm'])
pcurrent_data_dic.append(confirm)
current_data_dic2.append(pcurrent_data_dic)
# 累计死亡数据
data3 = timly_china[['name','total_dead']]
data3['total_dead'].replace(np.nan,'0',inplace=True)
current_data_dic3 = []
for i in range(len(data3)):
pcurrent_data_dic=[]
area = data3.iloc[i]['name']
pcurrent_data_dic.append(area)
confirm = int(data3.iloc[i]['total_dead'])
pcurrent_data_dic.append(confirm)
current_data_dic3.append(pcurrent_data_dic)
time_format = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
page_title = "中国疫情地图"
dataVisual.visualMapChina(self,page_title,
current_data_dic1,current_data_dic2,current_data_dic3,
time_format).render("中国疫情地图.html")
print('地图已完成!!!请在文件夹内查看。')
'''国家名中英对照字典'''
def nameMap(self):
name_map = {'新加坡': 'Singapore Rep.',
'多米尼加': 'Dominican Rep.',
'巴勒斯坦': 'Palestine',
'巴哈马': 'The Bahamas',
'东帝汶': 'East Timor',
'阿富汗': 'Afghanistan',
'几内亚比绍': 'Guinea Bissau',
'科特迪瓦': "Côte d'Ivoire",
'锡亚琴冰川': 'Siachen Glacier',
'英属印度洋领土': 'Br. Indian Ocean Ter.',
'安哥拉': 'Angola',
'阿尔巴尼亚': 'Albania',
'阿联酋': 'United Arab Emirates',
'阿根廷': 'Argentina',
'亚美尼亚': 'Armenia',
'法属南半球和南极领地': 'French Southern and Antarctic Lands',
'澳大利亚': 'Australia',
'奥地利': 'Austria',
'阿塞拜疆': 'Azerbaijan',
'布隆迪': 'Burundi',
'比利时': 'Belgium',
'贝宁': 'Benin',
'布基纳法索': 'Burkina Faso',
'孟加拉国': 'Bangladesh',
'保加利亚': 'Bulgaria',
'波斯尼亚和黑塞哥维那': 'Bosnia and Herz.',
'白俄罗斯': 'Belarus',
'伯利兹': 'Belize',
'百慕大': 'Bermuda',
'玻利维亚': 'Bolivia',
'巴西': 'Brazil',
'文莱': 'Brunei',
'不丹': 'Bhutan',
'博茨瓦纳': 'Botswana',
'中非': 'Central African Rep.',
'加拿大': 'Canada',
'瑞士': 'Switzerland',
'智利': 'Chile',
'中国': 'China',
'象牙海岸': 'Ivory Coast',
'喀麦隆': 'Cameroon',
'刚果民主共和国': 'Dem. Rep. Congo',
'刚果': 'Congo',
'哥伦比亚': 'Colombia',
'哥斯达黎加': 'Costa Rica',
'古巴': 'Cuba',
'北塞浦路斯': 'N. Cyprus',
'塞浦路斯': 'Cyprus',
'捷克': 'Czech Rep.',
'德国': 'Germany',
'吉布提': 'Djibouti',
'丹麦': 'Denmark',
'阿尔及利亚': 'Algeria',
'厄瓜多尔': 'Ecuador',
'埃及': 'Egypt',
'厄立特里亚': 'Eritrea',
'西班牙': 'Spain',
'爱沙尼亚': 'Estonia',
'埃塞俄比亚': 'Ethiopia',
'芬兰': 'Finland',
'斐': 'Fiji',
'福克兰群岛': 'Falkland Islands',
'法国': 'France',
'加蓬': 'Gabon',
'英国': 'United Kingdom',
'格鲁吉亚': 'Georgia',
'加纳': 'Ghana',
'几内亚': 'Guinea',
'冈比亚': 'Gambia',
'赤道几内亚': 'Eq. Guinea',
'希腊': 'Greece',
'格陵兰': 'Greenland',
'危地马拉': 'Guatemala',
'法属圭亚那': 'French Guiana',
'圭亚那': 'Guyana',
'洪都拉斯': 'Honduras',
'克罗地亚': 'Croatia',
'海地': 'Haiti',
'匈牙利': 'Hungary',
'印度尼西亚': 'Indonesia',
'印度': 'India',
'爱尔兰': 'Ireland',
'伊朗': 'Iran',
'伊拉克': 'Iraq',
'冰岛': 'Iceland',
'以色列': 'Israel',
'意大利': 'Italy',
'牙买加': 'Jamaica',
'约旦': 'Jordan',
'日本':'Japan',
'日本本土': 'Japan',
'哈萨克斯坦': 'Kazakhstan',
'肯尼亚': 'Kenya',
'吉尔吉斯斯坦': 'Kyrgyzstan',
'柬埔寨': 'Cambodia',
'韩国': 'Korea',
'科索沃': 'Kosovo',
'科威特': 'Kuwait',
'老挝': 'Lao PDR',
'黎巴嫩': 'Lebanon',
'利比里亚': 'Liberia',
'利比亚': 'Libya',
'斯里兰卡': 'Sri Lanka',
'莱索托': 'Lesotho',
'立陶宛': 'Lithuania',
'卢森堡': 'Luxembourg',
'拉脱维亚': 'Latvia',
'摩洛哥': 'Morocco',
'摩尔多瓦': 'Moldova',
'马达加斯加': 'Madagascar',
'墨西哥': 'Mexico',
'马其顿': 'Macedonia',
'马里': 'Mali',
'缅甸': 'Myanmar',
'黑山': 'Montenegro',
'蒙古': 'Mongolia',
'莫桑比克': 'Mozambique',
'毛里塔尼亚': 'Mauritania',
'马拉维': 'Malawi',
'马来西亚': 'Malaysia',
'纳米比亚': 'Namibia',
'新喀里多尼亚': 'New Caledonia',
'尼日尔': 'Niger',
'尼日利亚': 'Nigeria',
'尼加拉瓜': 'Nicaragua',
'荷兰': 'Netherlands',
'挪威': 'Norway',
'尼泊尔': 'Nepal',
'新西兰': 'New Zealand',
'阿曼': 'Oman',
'巴基斯坦': 'Pakistan',
'巴拿马': 'Panama',
'秘鲁': 'Peru',
'菲律宾': 'Philippines',
'巴布亚新几内亚': 'Papua New Guinea',
'波兰': 'Poland',
'波多黎各': 'Puerto Rico',
'朝鲜': 'Dem. Rep. Korea',
'葡萄牙': 'Portugal',
'巴拉圭': 'Paraguay',
'卡塔尔': 'Qatar',
'罗马尼亚': 'Romania',
'俄罗斯': 'Russia',
'卢旺达': 'Rwanda',
'西撒哈拉': 'W. Sahara',
'沙特阿拉伯': 'Saudi Arabia',
'苏丹': 'Sudan',
'南苏丹': 'S. Sudan',
'塞内加尔': 'Senegal',
'所罗门群岛': 'Solomon Is.',
'塞拉利昂': 'Sierra Leone',
'萨尔瓦多': 'El Salvador',
'索马里兰': 'Somaliland',
'索马里': 'Somalia',
'塞尔维亚': 'Serbia',
'苏里南': 'Suriname',
'斯洛伐克': 'Slovakia',
'斯洛文尼亚': 'Slovenia',
'瑞典': 'Sweden',
'斯威士兰': 'Swaziland',
'叙利亚': 'Syria',
'乍得': 'Chad',
'多哥': 'Togo',
'泰国': 'Thailand',
'塔吉克斯坦': 'Tajikistan',
'土库曼斯坦': 'Turkmenistan',
'特里尼达和多巴哥': 'Trinidad and Tobago',
'突尼斯': 'Tunisia',
'土耳其': 'Turkey',
'坦桑尼亚': 'Tanzania',
'乌干达': 'Uganda',
'乌克兰': 'Ukraine',
'乌拉圭': 'Uruguay',
'美国': 'United States',
'乌兹别克斯坦': 'Uzbekistan',
'委内瑞拉': 'Venezuela',
'越南': 'Vietnam',
'瓦努阿图': 'Vanuatu',
'西岸': 'West Bank',
'也门': 'Yemen',
'南非': 'South Africa',
'赞比亚': 'Zambia',
'津巴布韦': 'Zimbabwe'}
return name_map
'''绘制世界疫情地图的函数'''
def nCoV2019MapWorld(self):
# 读取国家中英对照字典
name_map = dataVisual.nameMap(self)
# 获取全球的实时数据
timly_world = getCOVID19.getTimlyWorldData(self)
# 今日确诊数据
data1 = timly_world[['name','today_confirm']]
data1['today_confirm'].replace(np.nan,'0',inplace=True)
current_data_dic1 = []
for i in range(len(data1)):
pcurrent_data_dic=[]
if data1.iloc[i]['name'] in list(name_map.keys()):
area = name_map[data1.iloc[i]['name']]
pcurrent_data_dic.append(area)
confirm = int(data1.iloc[i]['today_confirm'])
pcurrent_data_dic.append(confirm)
current_data_dic1.append(pcurrent_data_dic)
# 累计确诊数据
data2 = timly_world[['name','total_confirm']]
data2['total_confirm'].replace(np.nan,'0',inplace=True)
current_data_dic2 = []
for i in range(len(data2)):
pcurrent_data_dic=[]
if data2.iloc[i]['name'] in list(name_map.keys()):
area = name_map[data2.iloc[i]['name']]
pcurrent_data_dic.append(area)
confirm = int(data2.iloc[i]['total_confirm'])
pcurrent_data_dic.append(confirm)
current_data_dic2.append(pcurrent_data_dic)
# 累计死亡数据
data3 = timly_world[['name','total_dead']]
data3['total_dead'].replace(np.nan,'0',inplace=True)
current_data_dic3 = []
for i in range(len(data3)):
pcurrent_data_dic=[]
if data3.iloc[i]['name'] in list(name_map.keys()):
area = name_map[data3.iloc[i]['name']]
pcurrent_data_dic.append(area)
confirm = int(data3.iloc[i]['total_dead'])
pcurrent_data_dic.append(confirm)
current_data_dic3.append(pcurrent_data_dic)
time_format = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
page_title = "世界疫情地图"
dataVisual.visualMapWorld(self,page_title,
current_data_dic1,current_data_dic2,current_data_dic3,
time_format).render("世界疫情地图.html")
print('地图已完成!!!请在文件夹内查看。')
'''画疫情折线图的函数'''
def nCoV2019Line(self,title_name,date,total_confirm,today_confirm,total_dead,total_heal):
'''
title_name:标题,str
date:日期,列表
total_confirm:累计确诊人数,列表
today_confirm:今日确诊人数,列表
total_dead:累计期望人数
total_heal:累计治愈人数
'''
line = (
Line()
.add_xaxis(date)
.add_yaxis('累计确诊人数',total_confirm,is_smooth=True)
.add_yaxis('今日确诊人数',today_confirm,is_smooth=True)
.add_yaxis('累计死亡人数',total_dead,is_smooth=True)
.add_yaxis('累计治愈人数',total_heal,is_smooth=True)
.set_global_opts(xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-30)), # 设置x轴标签旋转角度
yaxis_opts=opts.AxisOpts(name='人数', min_=0),
title_opts=opts.TitleOpts(title=title_name))
)
return line
'''画指定省折线图的函数'''
def nCoV2019ProvinceLine(self,name):
# 获取指定地区的数据
his_data = getCOVID19.getProvinceData(self,name)
# 日期
date = his_data['date'].tolist()
# 累计确诊
total_confirm = his_data['total_confirm'].tolist()
# 今日确诊
today_confirm = his_data['today_confirm'].tolist()
# 累计死亡
total_dead = his_data['total_dead'].tolist()
# 累计治愈
total_heal = his_data['total_heal'].tolist()
title_name = name + '疫情折线图'
# 画折线图
dataVisual.nCoV2019Line(self,title_name,date,
total_confirm,today_confirm,total_dead,total_heal
).render(title_name+'.html')
print('折线图已完成!!!请在文件夹内查看。')
'''画指定地区折线图的函数'''
def nCoV2019CountryLine(self,name):
# 获取指定地区的数据
his_data = getCOVID19.getCountryData(self,name)
# 日期
date = his_data['date'].tolist()
# 累计确诊
total_confirm = his_data['total_confirm'].tolist()
# 今日确诊
today_confirm = his_data['today_confirm'].tolist()
# 累计死亡
total_dead = his_data['total_dead'].tolist()
# 累计治愈
total_heal = his_data['total_heal'].tolist()
title_name = name + '疫情折线图'
# 画折线图
dataVisual.nCoV2019Line(self,title_name,date,
total_confirm,today_confirm,total_dead,total_heal
).render(title_name+'.html')
print('折线图已完成!!!请在文件夹内查看。')
3. 主函数可视化交互菜单
if __name__ == '__main__':
# 调用大类
COVID19 = getCOVID19()
VISUAL = dataVisual()
# 交互菜单
while True:
print('-'*40)
print('新冠病毒疫情数据可视化'.center(25))
print('-'*40)
print('目录'.center(32))
print('查看中国疫情地图请输入:1'.center(28))
print('查看世界疫情地图请输入:2'.center(28))
print('查看指定省疫情折线图请输入:3'.center(30))
print('查看指定国家的疫情折线图请输入:4'.center(32))
print('退出菜单请输入:q'.center(23))
print('-'*40)
code = input('请输入数字:')
if code == '1':
VISUAL.nCoV2019MapChina()
if code == '2':
VISUAL.nCoV2019MapWorld()
if code == '3':
name = input('请输入你想查看的省(e.g.湖北):')
VISUAL.nCoV2019ProvinceLine(name)
if code == '4':
name = input('请输入你想查看的国家(e.g.意大利):')
VISUAL.nCoV2019CountryLine(name)
if code == 'q':
print('-'*40)
print('谢谢使用!!!'.center(23))
print('-'*40)
break
四、 可视化展示
运行程序

1.查看中国疫情地图

存放代码文件的文件夹下会有一个html文件
![]()
双击打开查看:

有3种数据可视化(通过正上方的按钮交互)
(1)今日确诊人数

(2)累计确诊人数
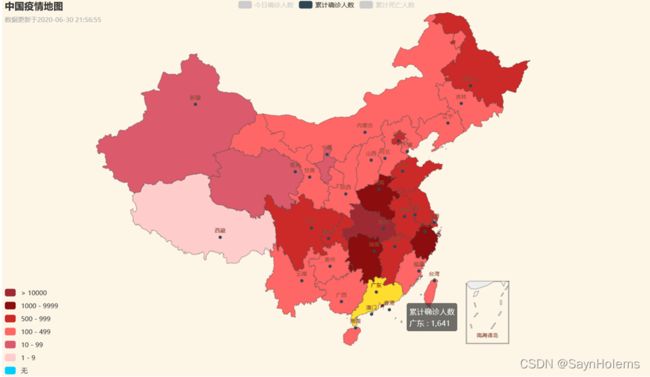
(3)累计死亡人数

2.查看世界疫情地图

存放代码文件的文件夹下会有一个html文件
![]()
双击打开查看:

有3种数据可视化(通过正上方的按钮交互)
(1)今日确诊人数

(2)累计确诊人数

(3)累计死亡人数

3.查看指定省的疫情数据折线图
 (这里以广东为例:)
(这里以广东为例:)

在存放代码文件的文件夹下会有一个html文件
![]() 双击打开查看:
双击打开查看:

有4种数据可视化(通过正上方的按钮交互)
(1)累计确诊人数

(2)今日确诊人数

(3)累计死亡人数

(4)累计治愈人数

4.查看指定国家的疫情数据折线图
 (这里以美国为例)
(这里以美国为例)
 在存放代码文件的文件夹下会有一个html文件
在存放代码文件的文件夹下会有一个html文件
![]() 双击打开查看:
双击打开查看:
 有4种数据可视化(通过正上方的按钮交互)
有4种数据可视化(通过正上方的按钮交互)
(1)累计确诊人数

(2)今日确诊人数

(3)累计死亡人数

(4)累计治愈人数
