深度学习经典网络: MobileNet系列网络(MobileNet v1)
MobileNet v1:https://arxiv.org/abs/1704.04861
keras 代码:https://github.com/keras-team/keras-applications/blob/master/keras_applications/mobilenet.py
MobileNet v1
- 0. 前言
- 1. 深度可分离卷积
-
- 1.1 与普通卷积对比
- 1.2 深度可分离卷积
- 2. MobileNet v1
- 3. 宽度因子和分辨率因子
- 4. 实验
- 5. MobileNet v1 代码
- References
0. 前言
可分离卷积通常包含两种类型,一种是空间可分离卷积,另一种是深度可分离卷积。而这两种方式都能减小卷积操作的计算量, 空间可分离就是将一个大的卷积核变成两个小的卷积核,比如将一个3×3的核分成一个3×1和一个1×3的核,像Inception系列网络就采用的这种方式:
[ 1 2 3 0 0 0 2 4 6 ] = [ 1 0 2 ] × [ 1 2 3 ] \left[\begin{array}{lll}{1} & {2} & {3} \\ {0} & {0} & {0} \\ {2} & {4} & {6}\end{array}\right]=\left[\begin{array}{l}{1} \\ {0} \\ {2}\end{array}\right] \times\left[\begin{array}{lll}{1} & {2} & {3}\end{array}\right] ⎣⎡102204306⎦⎤=⎣⎡102⎦⎤×[123]
另一种深度可分离卷积则是本文所采用的方式,深度可分离卷积就是将普通卷积拆分成为一个深度卷积和一个逐点卷积。深度卷积对输入每一个通道进行卷积,然后利用逐点的卷积进行升维。
1. 深度可分离卷积
1.1 与普通卷积对比
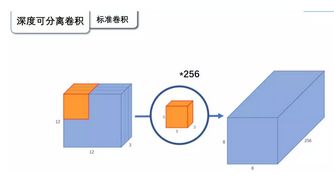
普通卷积: 输入一个12×12×3的一个输入特征图,经过5×5×3的卷积核卷积得到一个8×8×1的输出特征图。如果此时我们有256个特征图,我们将会得到一个8×8×256的输出特征图。
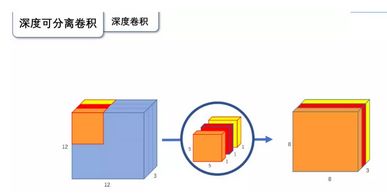
深度卷积: 将卷积核拆分成为但单通道形式,在不改变输入特征图像的深度的情况下,对每一通道进行卷积操作,这样就得到了和输入特征图通道数一致的输出特征图。如上图:输入12×12×3的特征图,经过5×5×1×3的深度卷积之后,得到了8×8×3的输出特征图。输入个输出的维度是不变的3。
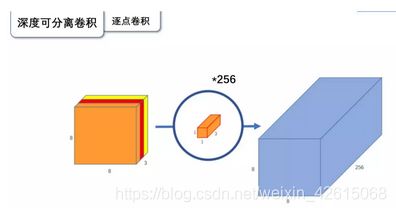
逐点卷积: 由于深度卷积的输出通道和输入通道一样,这样就造成了深度卷积后特征通道太少的问题,所以利用1×1的逐点卷积进行升维, 在深度卷积的过程中,我们得到了8×8×3的输出特征图,我们用256个1×1×3的卷积核对输入特征图进行卷积操作,输出的特征图和标准的卷积操作一样都是8×8×256了。
1.2 深度可分离卷积
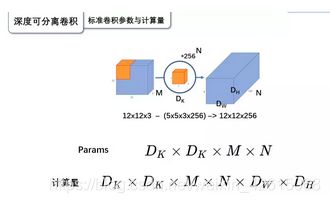
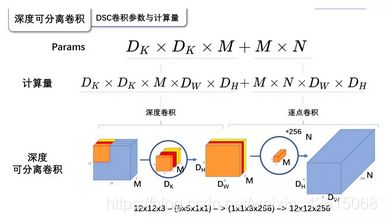
标准卷积参数量: 卷积核的尺寸是Dk×Dk×M,一共有N个,所以标准卷积的参数量是:
D K × D K × M × N D_{K} \times D_{K} \times M \times N DK×DK×M×N
标准卷积的计算量: 卷积核的尺寸是Dk×Dk×M,一共有N个,每一个都要进行Dw×Dh次运算,所以标准卷积的计算量是:
D K × D K × M × N × D W × D H D_{K} \times D_{K} \times M \times N \times D_{W} \times D_{H} DK×DK×M×N×DW×DH
深度可分离卷积参数量: 深度卷积的卷积核尺寸Dk×Dk×M;逐点卷积的卷积核尺寸为1×1×M,一共有N个,所以深度可分离卷积的参数量是:
D K × D K × M + M × N D_{K} \times D_{K} \times M+M \times N DK×DK×M+M×N
深度可分离卷积计算量: 深度卷积的卷积核尺寸Dk×Dk×M,一共要做Dw×Dh次乘加运算;逐点卷积的卷积核尺寸为1×1×M,有N个,一共要做Dw×Dh次乘加运算,所以深度可分离卷积的计算量是:
D K × D K × M × D W × D H + M × N × D W × D H D_{K} \times D_{K} \times M \times D_{W} \times D_{H}+M \times N \times D_{W} \times D_{H} DK×DK×M×DW×DH+M×N×DW×DH
两种卷积计算量对比:
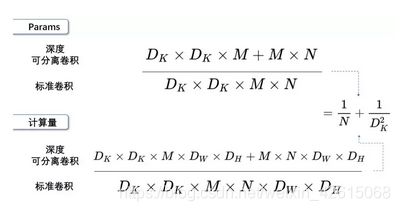
深度可分离卷积可以参数数量和乘加操作的运算量均下降为原来的 1 N + 1 D K 2 \frac{1}{N}+\frac{1}{D_{K}^{2}} N1+DK21
我们通常所使用的是3×3的卷积核,也就是会下降到原来的九分之一到八分之一。
例如:
输出为一个224×224×3的图像,VGG网络某层卷积输入的尺寸是112×112×64的特征图,卷积核为3×3×128,标准卷积的运算量是:
3×3×128×64×112×112=924844032
深度可分离卷积的运算量是:
3×3×64×112×112+128×64×112×112 = 109985792
这一层,MobileNetV1所采用的深度可分离卷积计算量与标准卷积计算量的比值为:
109985792 /924844032 = 0.1189
与我们所计算的九分之一到八分之一一致。
2. MobileNet v1
深度可分离卷积层:
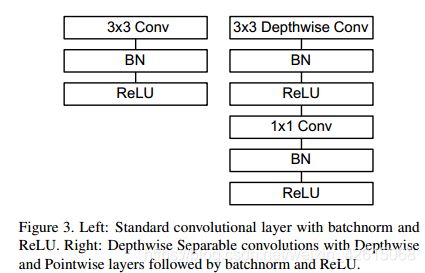
上图左边是标准卷积层,右边是深度可分离卷积的卷积层,虚线处是不相同点。深度可分离的卷积层,首先使用3×3的深度卷积提取特征,接着是一个BN层,随后是一个ReLU层,在之后就会逐点卷积,最后就是BN和ReLU了。这也很符合深度可分离卷积,将左边的标准卷积拆分成右边的一个深度卷积和一个逐点卷积。
ReLU6:
有部分代码实现采用ReLU6, 右边是ReLU6,当输入的值大于6的时候,返回6,relu6“具有一个边界”。作者认为ReLU6作为非线性激活函数,在低精度计算下具有更强的鲁棒性。
MobileNet v1 网络结构:

首先是一个3x3的标准卷积,进行下采样。然后就是堆积深度可分离卷积,并且其中的部分深度卷积会利用深度卷积进行下采样。然后采用平均池化层将feature变成1x1,根据预测类别大小加上全连接层,最后是一个softmax层。整个网络有28层,其中深度卷积层有13层。
3. 宽度因子和分辨率因子
MobileNet有两个简单的全局超参数,分别是宽度因子和分辨率因子,可有效的在延迟和准确率之间做折中。允许我们依据约束条件选择合适大小、低延迟、易满足嵌入式设备要求的模型。
宽度因子: 上述的逐通道卷积的卷积核个数通常是M,也就是Dk* Dk*1 的卷积核个数等于输入通道数,宽度因子是一个参数为(0,1]之间的参数,作用于通道数,可以理解为按照比例缩减输入通道数。同理,输出的通道数也可以通过这个参数进行按比例缩减。用α表示这个参数,则计算量为:
D K ⋅ D K ⋅ α M ⋅ D W ⋅ D H + α M ⋅ α N ⋅ D W ⋅ D H D_{K} \cdot D_{K} \cdot \alpha M \cdot D_{W} \cdot D_{H}+\alpha M \cdot \alpha N \cdot D_{W} \cdot D_{H} DK⋅DK⋅αM⋅DW⋅DH+αM⋅αN⋅DW⋅DH
分辨率因子: 上述的输入特征图大小为DW*DH,分辨率因子取值范围在(0,1]之间,可以理解为对特征图进行下采样,也就是按比例降低特征图的大小,使得输入数据以及由此在每一个模块产生的特征图都变小,用β表示这个参数,结合宽度因子α,则计算量为:
D K ⋅ D K ⋅ α M ⋅ ρ D W ⋅ ρ D H + α M ⋅ α N ⋅ ρ D W ⋅ ρ D H D_{K} \cdot D_{K} \cdot \alpha M \cdot \rho D_{W} \cdot \rho D_{H}+\alpha M \cdot \alpha N \cdot \rho D_{W} \cdot \rho D_{H} DK⋅DK⋅αM⋅ρDW⋅ρDH+αM⋅αN⋅ρDW⋅ρDH
4. 实验
MobileNet不同结构参数量的对比:
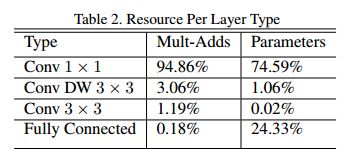
可以看出1×1的卷积操作占了总体计算量的近95%,这也是MobileNet如此之快的原因,具体分析请参考博文:
轻量级神经网络MobileNet,从V1到V3
另一个原因就是网络结构的优化导致的参数量的减少,参考:
https://www.jianshu.com/p/f2309a41931f
宽度因子对比:
 分辨率因子对比:
分辨率因子对比:
 与其他算法对比:
与其他算法对比:

5. MobileNet v1 代码
"""
mobilenet in tensorflow 2.0, tf.keras.
[1] Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
https://arxiv.org/abs/1704.04861
"""
import os
import tensorflow as tf
import tensorflow.keras as keras
from tensorflow.keras import layers, Sequential
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
class BasicConv2D(keras.Model):
"""This is the implement of native convolution operation."""
def __init__(self, num_filters, kernel_size, **kwargs):
super(BasicConv2D, self).__init__()
self.conv = layers.Conv2D(num_filters, kernel_size, use_bias=False, **kwargs)
self.bn = layers.BatchNormalization()
self.relu = layers.Activation('relu')
def call(self, inputs, training=None):
out = self.conv(inputs)
out = self.bn(out)
out = self.relu(out)
return out
class DepthSeparableConv2D(keras.Model):
"""This is the combination of depthwise convolution and pointwise convolution."""
def __init__(self, pointwise_conv_filters, kernel_size, alpha, **kwargs):
super(DepthSeparableConv2D, self).__init__()
self.depthwise_conv = Sequential([
layers.DepthwiseConv2D(kernel_size, padding='same', use_bias=False, **kwargs),
layers.BatchNormalization(),
layers.Activation('relu')
])
self.pointwise_conv = Sequential([
layers.Conv2D(int(pointwise_conv_filters*alpha), (1, 1), padding='same', use_bias=False),
layers.BatchNormalization(),
layers.Activation('relu')
])
def call(self, inputs, training=None):
out = self.depthwise_conv(inputs)
out = self.pointwise_conv(out)
return out
class MobileNetV1(keras.Model):
"""This is the implement of MobileNet v1."""
def __init__(self, width_multipler=1.0, num_classes=10):
super(MobileNetV1, self).__init__()
self.conv1 = Sequential([
BasicConv2D(int(32*width_multipler), (3, 3), strides=2, padding='same'),
DepthSeparableConv2D(64, (3, 3), alpha=width_multipler, strides=1)
])
self.conv2 = Sequential([
DepthSeparableConv2D(128, (3, 3), alpha=width_multipler, strides=2),
DepthSeparableConv2D(128, (3, 3), alpha=width_multipler, strides=1)
])
self.conv3 = Sequential([
DepthSeparableConv2D(256, (3, 3), alpha=width_multipler, strides=2),
DepthSeparableConv2D(256, (3, 3), alpha=width_multipler, strides=1)
])
self.conv4 = Sequential([
DepthSeparableConv2D(512, (3, 3), alpha=width_multipler, strides=2),
DepthSeparableConv2D(512, (3, 3), alpha=width_multipler, strides=1),
DepthSeparableConv2D(512, (3, 3), alpha=width_multipler, strides=1),
DepthSeparableConv2D(512, (3, 3), alpha=width_multipler, strides=1),
DepthSeparableConv2D(512, (3, 3), alpha=width_multipler, strides=1),
DepthSeparableConv2D(512, (3, 3), alpha=width_multipler, strides=1)
])
self.conv5 = Sequential([
DepthSeparableConv2D(1024, (3, 3), alpha=width_multipler, strides=2),
DepthSeparableConv2D(1024, (3, 3), alpha=width_multipler, strides=1)
])
self.avg_pool = layers.GlobalAveragePooling2D()
self.fc = layers.Dense(num_classes)
def call(self, inputs, training=None):
out = self.conv1(inputs)
out = self.conv2(out)
out = self.conv3(out)
out = self.conv4(out)
out = self.conv5(out)
out = self.avg_pool(out)
out = self.fc(out)
return out
if __name__ == '__main__':
model = MobileNetV1(width_multipler=0.5, num_classes=1000)
model.build(input_shape=(2, 224, 224, 3))
model.summary()
print(model.predict(tf.ones((2, 224, 224, 3))).shape)
References
1、轻量级神经网络MobileNet,从V1到V3
2、《Computer vision》笔记-MobileNet(7)
3、为什么MobileNet及其变体如此之快?