Learning with Recoverable Forgetting阅读心得
一、研究背景
终身学习的目标是在不忘记先前获得的知识的情况下学习一系列任务。然而,由于隐私或版权的原因,所涉及的培训数据可能不是终身合法的。例如,在实际场景中,模型所有者可能希望不时地启用或禁用对特定任务或特定示例的知识。不幸的是,这种对知识转移的灵活控制在以前的增量或递减学习方法中被很大程度上被忽视了,即使是在问题设置水平上。
二、解决的问题
在原文中,作者探索了一种新的学习方案,称为学习与可恢复遗忘(LIRF),它明确地处理任务或样本特定的知识去除和恢复。具体来说,LIRF引入了两种创新方案,即知识存储和提取,它们允许将用户指定的知识从预先训练过的网络中分离出来,并在必要时将其注入回来。在知识存储过程中,从目标网络中提取指定的知识并存储在存储模块中,同时保留目标网络的不敏感或一般知识。
三、创新
(1)作者介绍了一种新颖而实用的终身学习设置,可恢复遗忘
(2)原文提出了Learning with Recoverable Forgetting也就是LIRF,这个工作很具有开创性,对后续的工作都有一些启发。
四、文章内容
1.introduction
终身学习在广泛的领域得到应用,是一项长期的研究任务。它的主要目标是更新网络以适应新的数据,比如新的实例或来自新类的样本,而不忘记对过去数据的学习知识。相反,在某些情况下,由于隐私或版权问题,我们希望故意忘记或删除模型存储的特定知识。这项被称为机器遗忘的任务,由于其实用价值,也受到了行业和研究界越来越多的关注。
之前对机器遗忘的尝试主要集中在永久删除特定的知识上,这意味着一旦被删除,就不可能恢复这些知识。在这篇文章中,作者探索了一种新的学习场景,它明确地允许从预先训练过的网络中提取的知识被存储下来,并在需要时被注入到模型中。
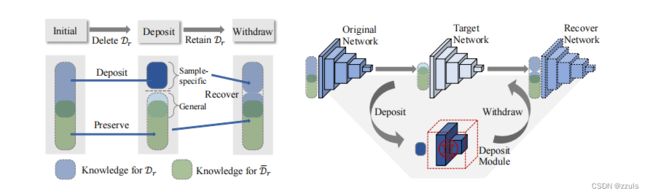
图1 LIRF图
当请求删除指定的知识时,表示为Dr(保留Dr),由于IP等问题,LIRF将这些知识从预先训练过的原始网络中分离出来,存储在一个存储模块中;然后将提取Dr的剩余网络表示为目标网络。当IP问题得到解决,模型所有者要求恢复知识或重新启用Dr时,LIRF会撤回存储的知识,并将其与目标网络合并,以生成恢复网络。
2.Related Work
(1)Life-long Learning
(2)Knowledge Transfer
知识转移的目的是将knowledge从网络转移到网络,作者主要讨论了knowledge distillation过程中的相关工作[4,5,6]。作者首次作出了对knowledge进行过滤和存储
(3)Machine Unlearning
用户应该拥有访问和删除他们共享到网络上数据的权利, 这是多数数据安全法和隐私保护法中规定的权利.不过现实是这个权利通常不能得到保障, 而在AI时代, 机器学习的广泛应用更是加剧了这个问题, 因为一个用数据训练好的模型会记住相关数据. 此外一些成功的模型攻击技术也会泄露模型中的数据导致用户隐私泄露的风险, 因此模型遗忘是一个必要的需求
3.Knowledge Deposit and Withdrawal
LIRF框架关注于class-level的终身问题,其中来自多个类的样本可能被存储或撤回,图2提出的LIRF框架。knowledge从原网络完全和部分地转移到存款模块和目标网络。恢复网络从目标网和存款模块中提取出来。

图2 LIRF框架
作者定义了数据集D,作为包含了全部数据的原始数据集,然后在D上训练的原始神经网络称为![]() ,在这个问题中,每个学习到的样本都被分配到deposit set或者preservation set。
,在这个问题中,每个学习到的样本都被分配到deposit set或者preservation set。
Deposit set ![]() :在target network
:在target network ![]() 应该被遗忘,在deposit module
应该被遗忘,在deposit module ![]() 应该被记忆的样本
应该被记忆的样本
Preservation set ![]() : 一组应该存储在目标网络上的一组样本(Dr的补充)
: 一组应该存储在目标网络上的一组样本(Dr的补充)
为了明确起见,作者讨论了一种情况,一个deposit set 需要被 deposit 和 withdrawal ,这可以肯定地推广到多个deposit set。为此作者提出了:
(1)Deposit Problem:有两个模型,一个是 T : X → Y that should map an input x to its correct class label y if x ⊂ ![]() , while map x to a wrong class label if x ⊂
, while map x to a wrong class label if x ⊂ ![]() 。另一个 是 Tr : X → F 它存储了 the knowledge of set Dr.
。另一个 是 Tr : X → F 它存储了 the knowledge of set Dr.
Constraints: Only the original network T0 and deposit set Dr are available.
(2)Withdraw Problem:Recover a model ![]() : X → Y that should map an input x to its correct class label y for both x ⊂ Dr, and x ⊂
: X → Y that should map an input x to its correct class label y for both x ⊂ Dr, and x ⊂ ![]() .
.
4.Learning with Recoverable Forgetting
LIRF由两个过程组成,一个是knowledge deposit,将 knowledge 从原始网络转移到目标网络和deposit module,另一个是 knowledge withdrawal,将knowledge恢复到恢复网络。

![]() 是原始神经网络,
是原始神经网络,![]() 是Deposit set ,
是Deposit set ,![]() 是目标网络,
是目标网络,![]() 是deposit module,
是deposit module,![]() 是recover network。
是recover network。
(1)Filter Knowledge out of Target Net
在 knowledge deposit 的过程中,重要的是怎么把Dr样本中的特定knowledge去除还不影响模型的训练效果。
首先要把![]() 在第n块处分为两个模块,分别记为
在第n块处分为两个模块,分别记为![]() 和
和![]() ,
,![]() 的划分方式和
的划分方式和![]() 一样,分为
一样,分为![]() 和
和![]() ,在之前的工作中[7],上层的部分更适合终身学习,
,在之前的工作中[7],上层的部分更适合终身学习,![]() 完全用于目标模型。
完全用于目标模型。
为此, 作者让一小部分数据块 (![]() =
= ![]() ),也就是
),也就是 ![]() 和
和 ![]() 有一部分小交叉, 希望特们共享信息,而且差异量也比较小. 因此作者将
有一部分小交叉, 希望特们共享信息,而且差异量也比较小. 因此作者将 ![]() 的部分完全转移到
的部分完全转移到![]() ,并且将
,并且将![]() 部分转移到
部分转移到![]() , 因为网络的较低层包含更多的样本特定知识。
, 因为网络的较低层包含更多的样本特定知识。
1)Sample-specific knowledge removal
作者提供了两种knowledge removal方法:

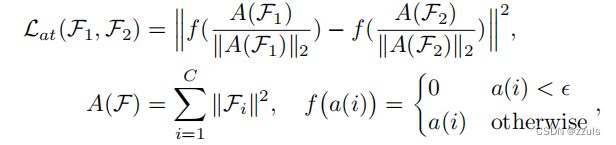
根据上式课件,如果(![]() T(x),yr)的值比较大,证明x在目标模型上面效果不好,后面一项比较小证明,去掉x后对原始模型的影响不大,那正好符合deposit set的条件。说明
T(x),yr)的值比较大,证明x在目标模型上面效果不好,后面一项比较小证明,去掉x后对原始模型的影响不大,那正好符合deposit set的条件。说明![]() 越大,越适合作为deposit set的数据。、
越大,越适合作为deposit set的数据。、
2)General knowledge preservation
目标网络需要保留两种knowledge,One is the knowledge coming from the preservation![]() ,the other is the general knowledge from the
,the other is the general knowledge from the ![]() .
.
由于目标网络T是用原始网络初始化的,而T的最后几个块在微调时保持不变,因此通过从![]() 完全转移到
完全转移到![]() ,已经保留了部分知识。
,已经保留了部分知识。

![]() 是 KL-divergence loss[10],T s是 temperature,
是 KL-divergence loss[10],T s是 temperature, ![]() 和
和 ![]() 分别是 T and T0的对数,滤波器g选择与preservation set 的类对应的对数,通过最小化
分别是 T and T0的对数,滤波器g选择与preservation set 的类对应的对数,通过最小化 ![]() ,将知识部分转移到目标网络。
,将知识部分转移到目标网络。
![]() 计算方法如下:
计算方法如下:

logits是几率:
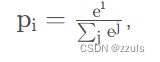
例如logits = [4,3.9,1]

文中g的介绍不多,但我猜测应该是选出logits中最大的那一个,比如g[0.511,0.4629,0.025714] = 0.511.
(2)Deposit Knowledge to Deposit Module
作者所提出的LIRF与传统的非学习问题的关键区别在于,作者将特定于样本的知识存储到存储模块中,而以前的unlearning methods中直接删除。
deposit module(存储模块需要有两个特性):容易被recover network恢复、容易被存储。
为了得到一个更好的knowledge容器,作者用修剪后的原始网络初始化了存款模块:
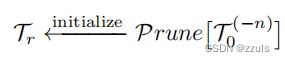
其中,作者使用简单的排序方法,通过计算其绝对核权值的和来进行修剪[11] ,裁剪之后不仅减少了模型的存储空间,而且只存储Dr的样本特定知识,而不是整个知识。
此外,与![]() 类似,应用带有滤波器g的部分知识转移损失Lpt,通过以下方法来增强该样本特定的知识。
类似,应用带有滤波器g的部分知识转移损失Lpt,通过以下方法来增强该样本特定的知识。
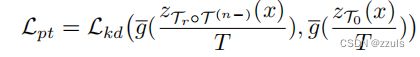
通过最小化损失Lpt,将样本特定的知识转移到存储模块,同时我们也将Tr调整到易于提取的模块,这意味着该知识对于恢复网络T是可恢复的。因此,在存款过程中,提前考虑了博士的恢复性能,以减少恢复净价值的分类损失:
![]()
(3)Withdraw Knowledge to Recover Net
一旦知识被成功存储,提出的LIRF框架就完成了,其中知识可以直接提取,不需要任何微调,更不用说不需要任何数据了。
恢复网被重构而不进行微调,其形式为:
![]()
更新LIRF框架的总体损失函数为:
![]()
四、reference
[1] Wu, C., Herranz, L., Liu, X., Wang, Y., van de Weijer, J., Raducanu, B.: Memory replay gans: Learning to generate new categories without forgetting. In: Conference and Workshop on Neural Information Processing Systems (2018)
[2] Shmelkov, K., Schmid, C., Alahari, K.: Incremental learning of object detectors without catastrophic forgetting. IEEE International Conference on Computer Vision pp. 3420–3429 (2017)
[3] Liu, H., Yang, Y., Wang, X.: Overcoming catastrophic forgetting in graph neural networks. In: AAAI Conference on Artificial Intelligence (2021)
[4] Hinton, G.E., Vinyals, O., Dean, J.: Distilling the knowledge in a neural network. Neural Information Processing Systems (2015)
[5] Han, X., Song, X., Yao, Y., Xu, X.S., Nie, L.: Neural compatibility modeling with probabilistic knowledge distillation. IEEE Transactions on Image Processing 29, 871–882 (2020)
[6] Yang, Y., Qiu, J., Song, M., Tao, D., Wang, X.: Distilling knowledge from graph convolutional networks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2020)
[7] Lee, S., Behpour, S., Eaton, E.: Sharing less is more: Lifelong learning in deep networks with selective layer transfer. In: International Conference on Machine Learning (2021)
[8]https://blog.csdn.net/LuminCynthia_/article/details/120652438
[9] Zagoruyko, S., Komodakis, N.: Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. arXiv preprint arXiv:1612.03928 (2016)
[10] https://blog.csdn.net/LuminCynthia_/article/details/124227087
[11] Li, H., Kadav, A., Durdanovic, I., Samet, H., Graf, H.P.: Pruning filters for efficient convnets (2016)